自聚合示例
为了能够实现想要的各种FL架构,我们必须学会怎么改造官方例子,使之能够自己聚合、训练,在自己聚合方面,有这样一个例子:
import torch
import copy
import syft as sy
from torch import nn
from torch import optim
hook = sy.TorchHook(torch)
# 工作机作为客户端,用于训练模型,安全工作机作为服务器,用于数据的整合及交流
Li = sy.VirtualWorker(hook, id='Li')
Zhang = sy.VirtualWorker(hook, id='Zhang')
secure_worker = sy.VirtualWorker(hook, id='secure_worker')
data = torch.tensor([[0, 1], [0, 1], [1, 0], [1, 1.]], requires_grad=True)
target = torch.tensor([[0], [0], [1], [1.]], requires_grad=True)
data_Li = data[0:2]
target_Li = target[0:2]
data_Zhang = data[2:]
target_Zhang = target[2:]
Li_data = data_Li.send(Li)
Zhang_data = data_Zhang.send(Zhang)
Li_target = target_Li.send(Li)
Zhang_target = target_Zhang.send(Zhang)
model = nn.Linear(2, 1)
# 定义迭代次数
iterations = 20
worker_iters = 5
for a_iter in range(iterations):
Li_model = model.copy().send(Li)
Zhang_model = model.copy().send(Zhang)
# 定义优化器
Li_opt = optim.SGD(params=Li_model.parameters(), lr=0.1)
Zhang_opt = optim.SGD(params=Zhang_model.parameters(), lr=0.1)
# 并行训练
for wi in range(worker_iters):
# 训练Li的模型
Li_opt.zero_grad()
Li_pred = Li_model(Li_data)
Li_loss = ((Li_pred - Li_target) ** 2).sum()
Li_loss.backward()
Li_opt.step()
Li_loss = Li_loss.get().data
# 训练Zhang的模型
Zhang_opt.zero_grad()
Zhang_pred = Zhang_model(Zhang_data)
Zhang_loss = ((Zhang_pred - Zhang_target) ** 2).sum()
Zhang_loss.backward()
Zhang_opt.step()
Zhang_loss = Zhang_loss.get().data
# 将更新的模型发送至安全工作机
Zhang_model.move(secure_worker)
Li_model.move(secure_worker)
# 模型平均
with torch.no_grad():
model.weight.set_(#此时Zhang和Li的model已经在安全工作机上了
((Zhang_model.weight.data + Li_model.weight.data) / 2).get())
model.bias.set_(
((Zhang_model.bias.data + Li_model.bias.data) / 2).get())
# 打印当前结果
print("Li:" + str(Li_loss) + "Zhang:" + str(Zhang_loss))
# 模型评估
preds = model(data)
loss = ((preds - target) ** 2).sum()
print(preds)
print(target)
print(loss.data)
其中关键的是,它用三个VirtualWorker来模拟了架构,利用.move()改变了模型的位置,然后再手动聚合。而我们要想用相同的思路对官方的例子进行改进,就必须了解pysyft的一些函数概念.federate() .send() .get()等等。
PySyft再探究
federated_train_loader = sy.FederatedDataLoader(
datasets.MNIST('/minist_data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
.federate((qin, zheng)),
batch_size=args['batch_size'], shuffle=True
)
torchversion相关函数
torchvision是pytorch的一个图形库,它服务于PyTorch深度学习框架的,主要用来构建计算机视觉模型。torchvision.transforms主要是用于常见的一些图形变换。以下是torchvision的构成:
- torchvision.datasets: 一些加载数据的函数及常用的数据集接口;
- torchvision.models: 包含常用的模型结构(含预训练模型),例如AlexNet、VGG、ResNet等;
- torchvision.transforms: 常用的图片变换,例如裁剪、旋转等;
- torchvision.utils: 其他的一些有用的方法。
torchvision.transforms.Compose()类:这个类的主要作用是串联多个图片变换的操作,也就是把里面的所有操作包起来一起执行。上述代码的剩下两行 也不难看出,分别是把图片转化为tensor和归一化的。
dataset.MINIST()
看完这篇文章,感觉dataset.MINIST()是最后返回的数据集列表
writer = SummaryWriter('LOGS/008log')
for i in range(10):
img, target = test_data[i]
writer.add_image('test_set', img, i)
writer.close()
他这样test_data[i]就直接代表的一个转化成tensor的图片。我们接下来的分析基本上都以这个思路继续。
.federate()做了什么
让我们探索一下,为了弄清楚上面的代码是做什么的,我们来测试一下代码:
for batch_idx, (data, target) in enumerate(federated_train_loader):
if batch_idx < 5:
print(batch_idx, type(data), data.location)
else:
break
0 <class 'torch.Tensor'> <VirtualWorker id:qin #objects:4>
1 <class 'torch.Tensor'> <VirtualWorker id:qin #objects:4>
2 <class 'torch.Tensor'> <VirtualWorker id:qin #objects:4>
3 <class 'torch.Tensor'> <VirtualWorker id:qin #objects:4>
4 <class 'torch.Tensor'> <VirtualWorker id:qin #objects:4>
哦,原来.federate()并没有改变什么,数据类型仍然是上面转换过的tensor,但是其只是分别分发到了两个虚拟打工人qin和zheng上!下面的代码
print('qin\'object: {}'.format(qin._objects))
print('zheng\'object: {}'.format(zheng._objects))
表示,二人手上都有了数据,也就是说federate()函数已经实现了分发(省去了我们一个一个send()的麻烦)!又因为实际上我们能够通过指针进行操作,那么对于federated_train_loader来说,数据在哪里并不担心,只需要和以前没有FL一样操作就可以了,其实这也是pysyft想达到的,尽可能简化操作。
现在看看我们手上有的东西:federated_train_loader加载好了训练数据可供我们调用,只不过我们是通过下发指令到远程的方式,而test_loader提供了测试数据给我们(在本地),最后可以用它来测试。并且既然qin 和zheng都有了数据,那么就说明我们可以直接对其进行操作,不一定非要用model.get()一次性全部拉过来!(但是这只是数据,而不是模型)
一个小点model.train()和.eval():
model.train():
在使用pytorch构建神经网络的时候,训练过程中会在程序上方添加一句model.train(),作用是启用batch normalization和drop out。
model.eval():
测试过程中会使用model.eval(),这时神经网络会沿用batch normalization的值,并不使用drop out。
随便举个例子
接下来要干的事: print(data.shape, target.shape)
手动分发数据,手动实施训练!
正式转型成功! ! !
修改官方示例!
官方的例子虽然给出了一个可以使用的例子,而且是直接使用的,但是直接分布数据也比较好,可以在尽可能不改变使用方式的情况下应用联邦学习。但是,正如 Bishe 所说,官方示例并没有考虑到我们自定义的训练架构。
model.get() .send().federate()等,直接一次性分发,然后用这个指针直接操作全部,扩展性太小,参考我们自己的聚合例子,我们改造一下!目标是实现我们想要的架构(例如设备之间的成对聚合模型)以进行学习。
数据读取
结合D2L学到的内容,使用Mnist数据,需要先加载,然后分批次两个步骤,在原来的例子中,使用了sy.FederatedDataLoader()和.federate((qin, zheng))一次完成了数据加载和分发给打工人。我们就用原本pytorch的DataLoader改造之:
federated_train = torchvision.datasets.MNIST(
root='/minist_data',
train=True,
download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))]
)
)
federated_train_loader = DataLoader(
federated_train,
batch_size=args['batch_size'],
shuffle=True
)
后面使用的时候,很自然的将data和target分开:
for batch_idx, (data, target) in enumerate(train_loader): # enumrate用来编序号
# print('data shape:{}'.format(data.shape))
data_qin = data[0:32]
target_qin = target[0:32]
我们print('data shape:{}'.format(data.shape))一下,就能发现通过数据加载,一个data的规格是(64 * 1 * 28 * 28)的,也就是一次加载了batch_size为64的图片,对应target也是64个,我们现在有两个打工人,那么一个人就应该分一半数据,所以才有了上面代码的切片操作,一人拿32。
培训过程
在加载完数据之后,我们还要把数据分发下去,使用CUDA,并且还要把模型也下发,训练过程中的loss也要get到读取。
qin_data = data_qin.send(qin)
qin_target = target_qin.send(qin)
# zheng_data = data[32:]
# zheng_target = target[32:]
# print(qin_data.shape)
# qin_model = model.copy().send(qin)#模型发往远程
# qin_model = model.send(qin) # 模型发往远程----------
# zheng_model = model.copy().send(zheng)
qin_data, qin_target = qin_data.to(device), qin_target.to(device)
# 训练
# qin_opt.zero_grad()
optimizer.zero_grad()
qin_output = qin_model(qin_data)
qin_loss = F.nll_loss(qin_output, qin_target)
qin_loss.backward()
# qin_opt.step()
optimizer.step()
这个步骤我先用只一个打工人进行模拟,所以没有模型聚合的部分,但是那个并不是主要问题。整体代码基本上就遵循 数据分发->数据放GPU上->优化器初始化->计算模型输出->计算损失->反向传播->优化器正向更新。
遇到的BUG
在改造的时候,遇到一个很严重的问题:损失一直下不来,这似乎很不可思议,连Mnist的损失都下不来,一定是代码改造的有问题。
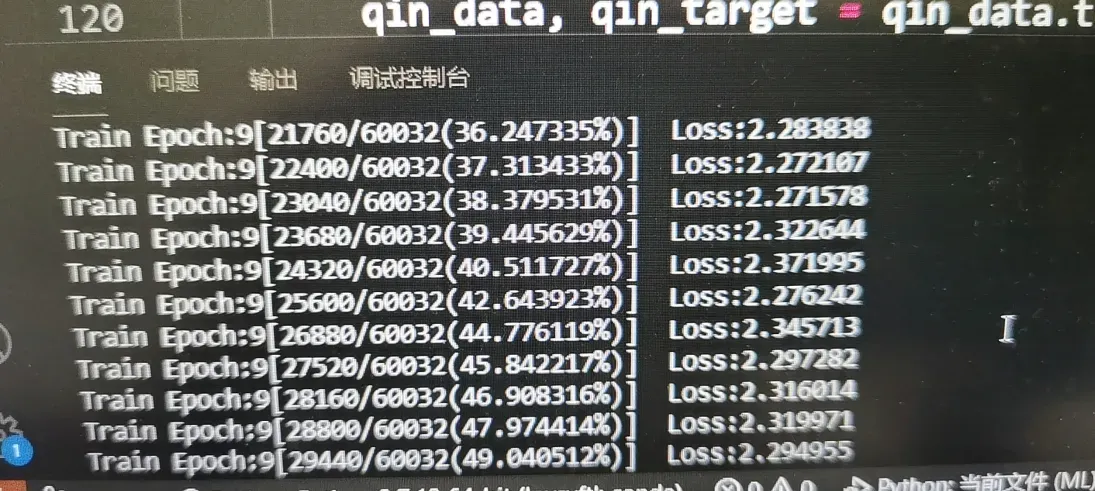
随后发现了问题,每次训练的循环里面,都重新定义了一次optimizer,就每次刚梯度下降,一个小批次还没训练完,我又给他刷新了hhh。原来错误代码:
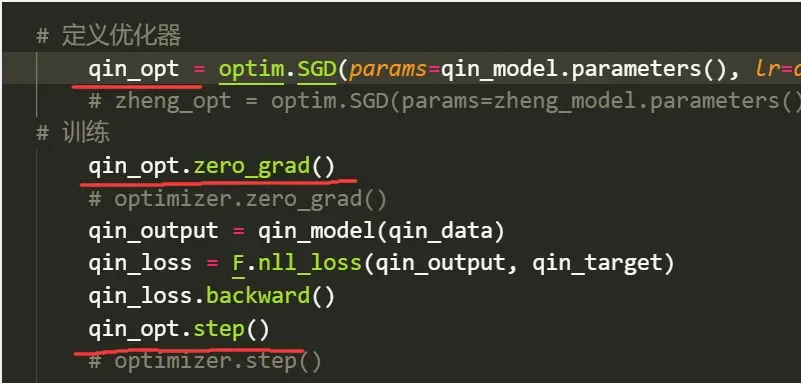
知道这个问题后,我在外面定义了优化器qinz_opt,作为参数传入训练函数:
model = Net().to(device)
print("开始训练!!\n")
qin_model = model.send(qin) # 模型发往远程
qin_opt = optim.SGD(params=qin_model.parameters(), lr=args['lr'])#优化器在这里!
for epoch in range(1, args['epochs']+1):
train(args, model, device, federated_train_loader, qin_opt, epoch)
最后,祝贺培训圆满结束
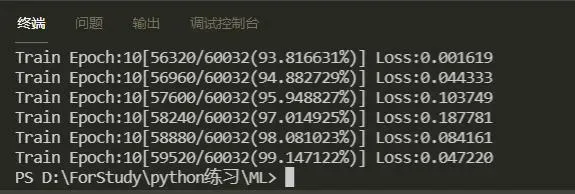
可以看到,loss终于下来了。
未来的计划
- 远处打工人 virtualworker 的数量从一个变成两个,也就是进行模型聚合
- 使用聚合模型在测试集上进行测试
- 代码重构,使用类和装饰器,允许以后实现更复杂的网络架构。
- 写KM算法(Kuhn-Munkras)求分配的代码。
文章出处登录后可见!