张量 a (3) 的大小必须与非单维 1 的张量 b (32) 的大小相匹配
原文标题 :The size of tensor a (3) must match the size of tensor b (32) at non-singleton dimension 1
我正在训练一个深度学习模型,但我遇到了错误,例如张量 a (3) 的大小必须与非单维 1 的张量 b (32) 的大小相匹配。而且在训练数据时,准确度高于 1这意味着我得到了像 1.04,1.06 这样的准确度。下面是训练代码
def train(model,criterion,optimizer,iters):
epoch = iters
train_loss = []
validaion_loss = []
train_acc = []
validation_acc = []
states = ['Train','Valid']
for epoch in range(epochs):
print("epoch : {}/{}".format(epoch+1,epochs))
for phase in states:
if phase == 'Train':
model.train()
dataload = train_data_loader
else:
model.eval()
dataload = valid_data_loader
run_loss,run_acc = 0,0
for data in dataload:
inputs,labels = data
#print("Inputs:",inputs.shape)
#print("Labels:",labels.shape)
inputs = inputs.to(device)
labels = labels.to(device)
labels = labels.byte()
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'Train'):
outputs = model(inputs)
print("Outputs",outputs.shape)
loss = criterion(outputs,labels)
predict = outputs>=0.5
#print("Predict",predict.shape)
if phase == 'Train':
loss.backward()
optimizer.step()
acc = torch.sum(predict == labels.data)
run_loss+=loss.item()
#print("Running_Loss",run_loss)
run_acc+=acc.item()/len(labels)
#print("Running_Acc",run_acc)
if phase == 'Train':
epoch_loss = run_loss/len(train_data_loader)
train_loss.append(epoch_loss)
epoch_acc = run_acc/len(train_data_loader)
train_acc.append(epoch_acc)
else:
epoch_loss = run_loss/len(valid_data_loader)
validaion_loss.append(epoch_loss)
epoch_acc = run_acc/len(valid_data_loader)
validation_acc.append(epoch_acc)
print("{}, loss :{},accuracy:{}".format(phase,epoch_loss,epoch_acc))
history = {'Train_loss':train_loss,'Train_accuracy':train_acc,
'Validation_loss':validaion_loss,'Validation_Accuracy':validation_acc}
return model,history
下面是基本模型的代码
model = models.resnet34(pretrained = True)
for param in model.parameters():
param.requires_grad = False
model.fc = nn.Sequential(nn.Linear(model.fc.in_features,out_features = 1024),nn.ReLU(),
nn.Linear(in_features = 1024,out_features = 512),nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(in_features=512,out_features=256),nn.ReLU(),
nn.Linear(in_features = 256,out_features = 3),nn.LogSoftmax(dim = 1))
device = torch.device("cuda" if cuda.is_available() else "cpu")
print(device)
model.to(device)
optimizer = optim.Adam(model.parameters(),lr = 0.00001)
criterion = nn.CrossEntropyLoss()
我尝试使用 predict == labels.unsqueeze(1) 它没有引发任何错误,但准确度超过 1。我可以知道我必须在哪里更改代码。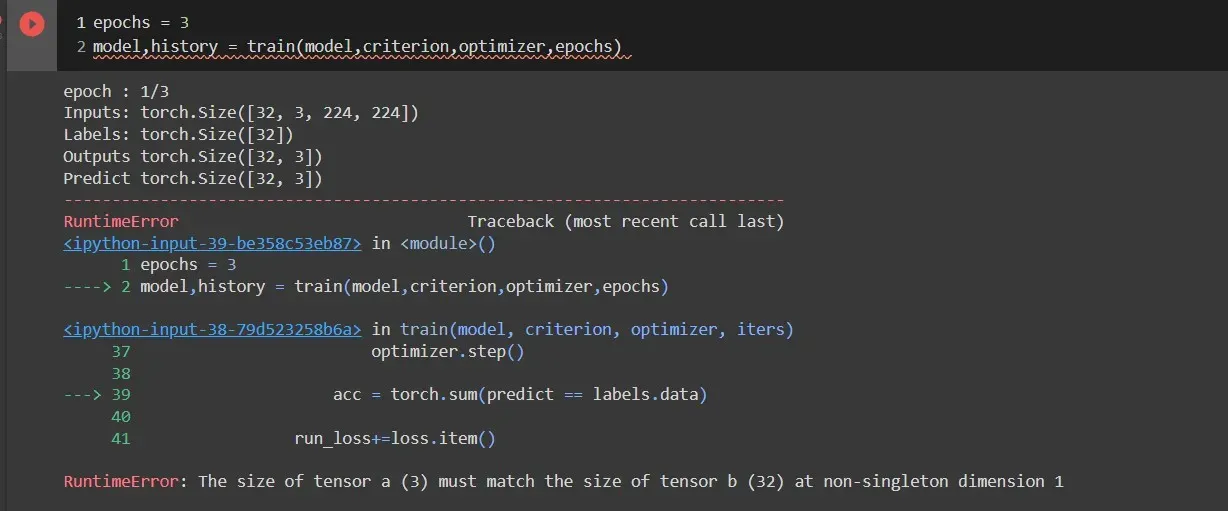
-
 Phoenix 评论
Phoenix 评论您的 [32,3] 大小的输出张量 32 是小批量的数量,3 是您的神经网络的输出,例如。
[[0.25, 0.45, 0.3], [0.45, 0.15, 0.4], .... .... [0.2, 0.15, 0.65]]当您比较输出是否 >= 0.5 时,结果是预测张量,但它是具有相同大小的输出 [32,3] 的布尔张量,如下所示:
[[False, False, False], [False, False, False], .... .... [False, False, True]]Labels 是 0D 张量,有 32 个值,例如。
[0,2,...,0]问题的原因在这里:要比较 predicts 和 labels ,您应该从 predicts 张量中的每一行中选择最大概率的索引,如下所示:
predicts = predicts.argmax(1) # output [0,0,...,2]但是 predicts 是 bool 张量,不能直接将 argmax 应用于 bool 张量。因此,您收到了评论中指出的错误消息。要解决此问题,您只需执行以下操作:
predicts = (output >= 0.5)*1现在您可以比较两个张量预测标签,因为它们的大小相同。
简而言之,您应该使用:
predicts = (output >= 0.5)*1 acc = torch.sum(predicts.argmax(1) == Labels)您的问题已解决,但在逻辑上准确性不正确。因此,如果您想使用 sigmoid 进行多分类问题,请小心,因为您使用 output >= 0.5 但是,输出中有 3 个类。这是不正确的,因为假设你在输出中有 [0.15,0.45,0.4]。你的预测将是 [0, 0, 0] 然后 argmax(1) 将选择第一个索引,如果有相等的数字,但是,应该选择第二个索引在这种情况下,因为它具有最大的概率。如果你有一个多分类问题,最好的方法是使用 softmax 而不是 sigmoid (>= 0.5) 。
顺便说一句,如果你回到你的模型结构(最后一行),你会发现你已经使用了 nn.LogSoftmax 。你只需删除这一行 predicts = (outputs >= 0.5) 并直接使用:
#before the for loop num_corrects = 0 # inside the for loop num_corrects = num_corrects + torch.sum(outputs.argmax(1) == Labels) #outside the loop train_accuracy = (100. * num_corrects / len(train_loader.dataset))2年前