交叉验证过程后 r2 分数下降是否正常? (线性回归模型)
machine-learning 256
原文标题 :Is it normal for the r2 score to drop after the crossvalidation process? (Linear regression model)
车价预测代码:
# importing pandas
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import RandomizedSearchCV
from sklearn.metrics import r2_score,mean_squared_error,mean_squared_log_error,make_scorer
import warnings
import os
warnings.filterwarnings("ignore", category=DeprecationWarning)
warnings.filterwarnings("ignore", category=FutureWarning)
is_file=os.path.isfile('C:/Users/Desktop/car_price_prediction/audi-bmw-toyota.csv')
if is_file==False:
# merging two csv files
df = pd.concat(map(pd.read_csv, ['audi.csv', 'bmw.csv','toyota.csv']), ignore_index=True)
df.to_csv("audi-bmw-toyota.csv", index=False)
print('csv files have merged...')
else:
print("The file already exists.")
# loading the dataset to a pandas DataFrame
dataset = pd.read_csv('C:/Users/Desktop/car_price_prediction/audi-bmw-toyota.csv')
print('transmission_value-counts:\n',dataset['transmission'].value_counts()) #4 type
print('fueltype_value-counts:\n',dataset['fuelType'].value_counts()) #5 type
print("Manual transmissioned cars:\n", dataset.loc[dataset['transmission'] == 'Manual'])
print("Hybrid fuel typed cars:\n", dataset.loc[dataset['fuelType'] == 'Hybrid'])
print("Other fuel typed cars:\n", dataset.loc[dataset['fuelType'] == 'Other'])
dataset.info()
# correlation
df_corr = dataset.corr()
df_corr.sort_values('price',inplace=True)
fig=df_corr[['price']].plot(kind='barh',color="r",figsize=(5, 5))
fig.set_xlabel('correlation')
fig.set_title("Price and Variables's Correlation")
X=dataset.iloc[:,[0,1,3,4,5,6,7,8]]
Y=dataset.iloc[:,2]
print("X:\n",X)
print("Y:\n",Y)
#data preprocessing
X["model"]=X["model"].str.replace(' ','')
print(X["model"])
le1=LabelEncoder() #model column has so much diffrent group. That's wyh LabelEncoder is useful.
X_0=le1.fit_transform(X.iloc[:,0])
X.loc[:, 0] =X_0
X["model"] = pd.DataFrame(X_0, columns=['model'])
#categorical variables
df_transmission = pd.get_dummies(dataset["transmission"]
,prefix = "transmission"
,drop_first = True) # Preventing Multicollinearity
X1 = pd.concat([X, df_transmission[['transmission_Manual', 'transmission_Other', 'transmission_Semi-Auto']]], axis=1)
df_fuelType = pd.get_dummies(dataset["fuelType"]
,prefix = "fuelType"
,drop_first = True) # Preventing Multicollinearity
X2 = pd.concat([X1, df_fuelType[['fuelType_Electric', 'fuelType_Hybrid', 'fuelType_Other','fuelType_Petrol']]], axis=1)
X3 = X2.drop(['transmission', 'fuelType',0], axis=1)
print("X3:\n",X3)
#Feature Scaling
sclr=StandardScaler()
X3=sclr.fit_transform(X3)
print("X3:\n",X3)
#training and test set
X_train, X_test, Y_train, Y_test = train_test_split(X3,
Y,
test_size=0.2,
random_state=42)
rf=RandomForestRegressor(random_state=42)
model = rf.fit(X_train, Y_train)
y_pred=model.predict(X_test)
print("r2_score_test:",r2_score(Y_test,y_pred))
RMSE_test=np.sqrt(mean_squared_error(Y_test,model.predict(X_test)))
print("RMSE:",RMSE_test)
Cross validation and hyperparameter optimization
# Number of trees in random forest
n_estimators = [int(x) for x in np.linspace(start = 200, stop = 2000, num = 10)]
# Number of features to consider at every split
max_features = ['auto', 'sqrt']
# Maximum number of levels in tree
max_depth = [int(x) for x in np.linspace(10, 110, num = 11)]
max_depth.append(None)
# Minimum number of samples required to split a node
min_samples_split = [2, 5, 10]
# Minimum number of samples required at each leaf node
min_samples_leaf = [1, 2, 4]
# Method of selecting samples for training each tree
bootstrap = [True, False]
# Create the random grid
random_grid = {'n_estimators': n_estimators,
'max_features': max_features,
'max_depth': max_depth,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf,
'bootstrap': bootstrap}
rf_random = RandomizedSearchCV(estimator = rf, param_distributions = random_grid, n_iter = 10, cv = 3, verbose=2, n_jobs = -1)
rf_random.fit(X_train, Y_train)
print("best_params",rf_random.best_params_)
base_model = RandomForestRegressor(n_estimators = 2000,min_samples_split=5,
min_samples_leaf=1,
max_features='sqrt',
max_depth=30,
bootstrap=True,
random_state = 42).fit(X_train, Y_train)
y_pred_base=base_model.predict(X_test)
print("r2_score_test:",r2_score(Y_test,y_pred_base))
RMSE_test_based_model=np.sqrt(mean_squared_error(Y_test,base_model.predict(X_test)))
print("RMSE_based:",RMSE_test_based_model)
数据集链接:https://www.kaggle.com/adityadesai13/used-car-dataset-ford-and-mercedes
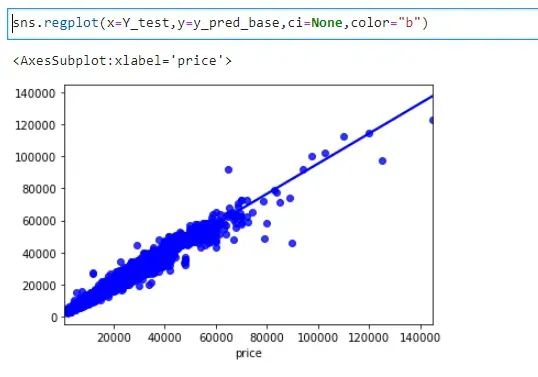
朋友您好,我已经将audi.csv、bmw.csv、toyota.csv文件合并得到一个新的CSV文件。在车价估算算法中,测试交叉验证的RMSE值大于测试的RMSE(未验证)值。另外,交叉验证后r2_score下降了一点这个过程是否正常,或者我到底做错了什么?
问题与回归模型有关吗?
交叉验证前:r2_score_test: 0.961865129046153
RMSE:2293.040184587231
交叉验证后:r2_score_test: 0.9604039571043385
RMSE_based: 2336.5572047970254
回复
我来回复-
 murat taşçı 评论
murat taşçı 评论修复:
X=dataset.iloc[:,[1,3,4,5,6,7,8]] #removing of car model column Y=dataset.iloc[:,2] #data preprocessing X['no_year'] = (2022) -X['year'] X.drop(['year'],axis = 1,inplace=True) print('X:\n',X)交叉验证前:
r2_score_test: 0.941560662538529
RMSE_test: 2838.5932576738546
交叉验证后:
r2_score_based: 0.9603626850597086RMSE_based: 2337.7746165658878
2年前