使用 sklearn 恢复 StandardScaler().fit_transform() 的特征名称
machine-learning 487
原文标题 :Recovering features names of StandardScaler().fit_transform() with sklearn
编辑自 Kaggle 中的教程,我尝试运行以下代码和数据(可从此处下载):
代码:
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt # for plotting facilities
from datetime import datetime, date
from sklearn.model_selection import TimeSeriesSplit, GridSearchCV
import xgboost as xgb
from sklearn.metrics import mean_squared_error, mean_absolute_error
import math
from sklearn.preprocessing import StandardScaler
df = pd.read_csv("./data/Aquifer_Petrignano.csv")
df['Date'] = pd.to_datetime(df.Date, format = '%d/%m/%Y')
df = df[df.Rainfall_Bastia_Umbra.notna()].reset_index(drop=True)
df = df.interpolate(method ='ffill')
df = df[['Date', 'Rainfall_Bastia_Umbra', 'Depth_to_Groundwater_P24', 'Depth_to_Groundwater_P25', 'Temperature_Bastia_Umbra', 'Temperature_Petrignano', 'Volume_C10_Petrignano', 'Hydrometry_Fiume_Chiascio_Petrignano']].resample('7D', on='Date').mean().reset_index(drop=False)
X = df.drop(['Depth_to_Groundwater_P24','Depth_to_Groundwater_P25','Date'], axis=1)
y1 = df.Depth_to_Groundwater_P24
y2 = df.Depth_to_Groundwater_P25
scaler = StandardScaler()
X = scaler.fit_transform(X)
model = xgb.XGBRegressor()
param_search = {'max_depth': range(1, 2, 2),
'min_child_weight': range(1, 2, 2),
'n_estimators' : [1000],
'learning_rate' : [0.1]}
tscv = TimeSeriesSplit(n_splits=2)
gsearch = GridSearchCV(estimator=model, cv=tscv,
param_grid=param_search)
gsearch.fit(X, y1)
xgb_grid = xgb.XGBRegressor(**gsearch.best_params_)
xgb_grid.fit(X, y1)
ax = xgb.plot_importance(xgb_grid)
ax.figure.tight_layout()
ax.figure.savefig('test.png')
y_val = y1[-80:]
X_val = X[-80:]
y_pred = xgb_grid.predict(X_val)
print(mean_absolute_error(y_val, y_pred))
print(math.sqrt(mean_squared_error(y_val, y_pred)))
我绘制了一个特征重要性图,其原始特征名称被隐藏:
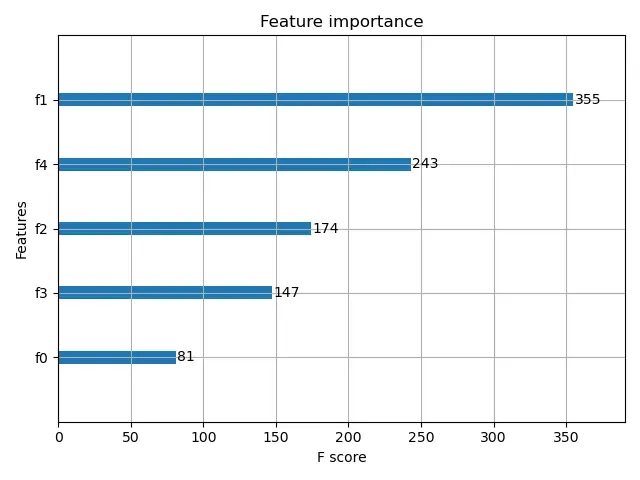
如果我注释掉这两行:
scaler = StandardScaler()
X = scaler.fit_transform(X)
我得到输出:
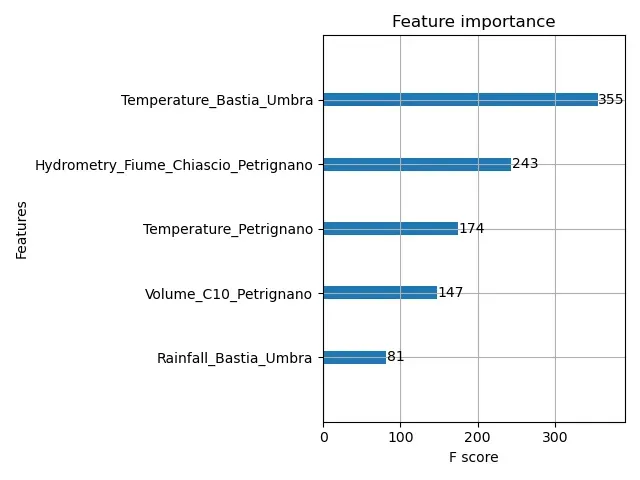
我如何使用scaler.fit_transform()forX并获得具有原始特征名称的特征重要性图?