比较 Pandas 中的数据
python 170
原文标题 :Comparing Data in Pandas
我只是想获取一些数据并重新排列它。这是我的数据集,显示食物和他们在不同年份获得的分数。我想做的是找到平均得分最低和最高的食物并跟踪他们多年来的分数。
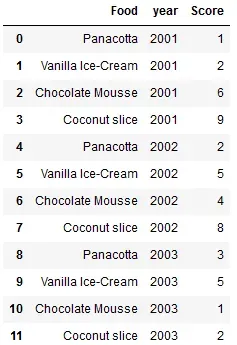
到目前为止,这是我的代码:
#import
menu = pd.read_csv("Food.csv")
#Get average rank
avg_ranking = menu.groupby(['Food']).Score.mean().round()
#Convert to DataFrame
data2 = pd.DataFrame(avg_ranking.reset_index(name = "Group"))
#Display the highest and lowest ranking
filter_food = data2[['Food', 'Group']][(data2['Group'] == avg_ranking.max()) | (data2['Group'] == avg_ranking.min())]
#This is where I have been playing around with getting the individual min and max food names:
filter_food_max = data2[['Food']][(data2['Group'] == data2.Group.max())]
Max = filter_food_max.Food
filter_food_min = data2[['Food']][(data2['Group'] == data2.Group.min())]
Min = filter_food_min.Food
下一部分是我有点卡住的地方:我需要显示原始数据集中的最大和最小食物,它将显示所有列 – 食物、年份、分数。这是我尝试过的,但它不起作用:
menu[menu.Food == Max & menu.Food == Min]
基本上我希望它在数据框中显示类似下面的内容,所以我可以绘制一些图表(即。我想制作一个线图,在 x 轴上显示年份,在 y 轴上显示分数并绘制得分最低的食物和得分最高的食物:
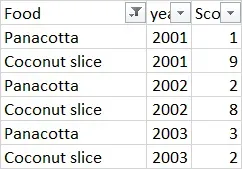
如果你们知道任何其他方法(使用 group-by 功能),请告诉我!
任何帮助,将不胜感激