如何在 Pandas 中获得每组的平均成对余弦相似度
原文标题 :How to get average pairwise cosine similarity per group in Pandas
我有一个示例数据框如下
df=pd.DataFrame(np.array([['facebook', "women tennis"], ['facebook', "men basketball"], ['facebook', 'club'],['apple', "vice president"], ['apple', 'swimming contest']]),columns=['firm','text'])
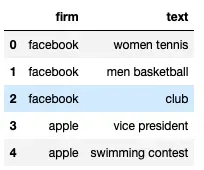
现在我想使用词嵌入计算每个公司内的文本相似度。例如,facebook 的平均余弦相似度将是第 0、1 和 2 行之间的余弦相似度。最终的数据帧应该在每个公司的每一行旁边都有一个列['mean_cos_between_items']。每个公司的价值都是相同的,因为它是公司内部的成对比较。
我写了下面的代码:
import gensim
from gensim import utils
from gensim.models import Word2Vec
from gensim.models import KeyedVectors
from gensim.scripts.glove2word2vec import glove2word2vec
from sklearn.metrics.pairwise import cosine_similarity
# map each word to vector space
def represent(sentence):
vectors = []
for word in sentence:
try:
vector = model.wv[word]
vectors.append(vector)
except KeyError:
pass
return np.array(vectors).mean(axis=0)
# get average if more than 1 word is included in the "text" column
def document_vector(items):
# remove out-of-vocabulary words
doc = [word for word in items if word in model_glove.vocab]
if doc:
doc_vector = model_glove[doc]
mean_vec=np.mean(doc_vector, axis=0)
else:
mean_vec = None
return mean_vec
# get average pairwise cosine distance score
def mean_cos_sim(grp):
output = []
for i,j in combinations(grp.index.tolist(),2 ):
doc_vec=document_vector(grp.iloc[i]['text'])
if doc_vec is not None and len(doc_vec) > 0:
sim = cosine_similarity(document_vector(grp.iloc[i]['text']).reshape(1,-1),document_vector(grp.iloc[j]['text']).reshape(1,-1))
output.append([i, j, sim])
return np.mean(np.array(output), axis=0)
# save the result to a new column
df['mean_cos_between_items']=df.groupby(['firm']).apply(mean_cos_sim)
但是,我收到以下错误:
你能帮忙吗?谢谢!
回复
我来回复-
 ewz93 评论
ewz93 评论该回答已被采纳!
去掉
model_glove.vocab这里的.vocab,当前版本的gensim不再支持这个:编辑:这里还需要split()来迭代单词而不是字符。# get average if more than 1 word is included in the "text" column def document_vector(items): # remove out-of-vocabulary words doc = [word for word in items.split() if word in model_glove] if doc: doc_vector = model_glove[doc] mean_vec = np.mean(doc_vector, axis=0) else: mean_vec = None return mean_vec在这里,当您想要迭代值时迭代索引元组,因此删除
.index。此外,您将所有值放在output中,包括单词 (/indices)i和j,因此如果您想获得它们的平均值,您必须指定您想要的平均值。由于您似乎不需要i和j,您可以只将结果sims放入列表中,然后取列表平均值:# get pairwise cosine similarity score def mean_cos_sim(grp): output = [] for i, j in combinations(grp.tolist(), 2): if document_vector(i) is not None and len(document_vector(i)) > 0: sim = cosine_similarity(document_vector(i).reshape(1, -1), document_vector(j).reshape(1, -1)) output.append(sim) return np.mean(output, axis=0)在这里,您尝试将结果添加为一列,但行数会有所不同,因为结果 DataFrame 每个公司只有一行,而原始 DataFrame 每个文本有一行。因此,您必须创建一个新的 DataFrame(然后您可以选择根据
firm列与原始 DataFrame 合并/加入):df = pd.DataFrame(np.array( [['facebook', "women tennis"], ['facebook', "men basketball"], ['facebook', 'club'], ['apple', "vice president"], ['apple', 'swimming contest']]), columns=['firm', 'text']) df_grpd = df.groupby(['firm'])["text"].apply(mean_cos_sim)总体上会给你(编辑:更新):
print(df_grpd) > firm apple [[0.53190523]] facebook [[0.83989316]] Name: text, dtype: object编辑:
我刚刚注意到超高分的原因是缺少标记化,请参阅更改的部分。如果没有
split(),这只是比较了往往非常高的角色相似度。2年前 -
fsimonjetz 评论
注意
sklearn.metrics.pairwise.cosine_similarity,当传递单个矩阵X时,会自动返回X中所有样本之间的成对相似度。即,不必手动构造对。假设你用这样的东西构建你的平均嵌入(我在这里使用
glove-twitter-25),def mean_embeddings(s): """Transfer a list of words into mean embedding""" return np.mean([model_glove.get_vector(x) for x in s], axis=0) df["embeddings"] = df.text.str.split().apply(mean_embeddings)所以
df.embeddings原来>>> df.embeddings 0 [-0.2597, -0.153495, -0.5106895, -1.070115, 0.... 1 [0.0600965, 0.39806002, -0.45810497, -1.375365... 2 [-0.43819, 0.66232, 0.04611, -0.91103, 0.32231... 3 [0.1912625, 0.0066999793, -0.500785, -0.529915... 4 [-0.82556, 0.24555385, 0.38557374, -0.78941, 0... Name: embeddings, dtype: object您可以像这样获得平均成对余弦相似度,重点是您可以直接将
cosine_similarity应用于为每个组准备好的矩阵:( df.groupby("firm").embeddings # extract 'embeddings' for each group .apply(np.stack) # turns sequence of arrays into proper matrix .apply(cosine_similarity) # the magic: compute pairwise similarity matrix .apply(np.mean) # get the mean )对于我使用的模型,结果是:
firm apple 0.765953 facebook 0.893262 Name: embeddings, dtype: float322年前