如何从数据框列中计算来自 Spacy 的名词数量?
nlp 414
原文标题 :How to count the number of nouns from Spacy from a dataframe column?
我有一个这样的数据框(例如)。
| text |
|---|
| I left the country. |
| Andrew is from America and he loves apples. |
我想添加一个新列,名词数量,Spacy 应该在其中计算 NOUNS pos 标签。如何在 Python 中转换它?
import pandas as pd
import spacy
# the dataframe
# NLP Spacy with POS tags
nlp = spacy.load("en_core_web_sm")
我的问题是,如何在“文本”列上应用 nlp,检查 pos 是否为 NOUN 并计算它并将其作为特征给出?
谢谢!
回复
我来回复-
 I'mahdi 评论
I'mahdi 评论你可以像下面这样使用
applyinpandas:import spacy import pandas as pd import collections sp = spacy.load("en_core_web_sm") df = pd.DataFrame({'text':['I left the country and city', 'Andrew is from America and he loves apples and bananas']}) # >>> df # text # 0 I left the country and city # 1 Andrew is from America and he loves apples and bananas def count_noun(x): res = [token.pos_ for token in sp(x)] return collections.Counter(res)['NOUN'] df['C_NOUN'] = df['text'].apply(count_noun) print(df)输出:
text C_NOUN 0 I left the country and city 2 1 Andrew is from America and he loves apples and bananas 2如果您想获取名词列表和数量,可以尝试以下操作:
def count_noun(x): nouns = [token.text for token in sp(x) if token.pos_=='NOUN'] return [nouns, len(nouns)] df[['list_NOUN','C_NOUN']] = pd.DataFrame(df['text'].apply(count_noun).tolist()) print(df)输出:
text list_NOUN C_NOUN 0 I left the country and city [country, city] 2 1 Andrew ... apples and bananas [apples, bananas] 22年前 -
Talha Tayyab 评论
首先,我正在创建一个演示数据框:
import spacy import pandas as pd nlp = spacy.load("en_core_web_sm") df = pd.DataFrame([["I left the country"],["Andrew is from America and he loves apples."]],columns=["text"])它看起来像这样:
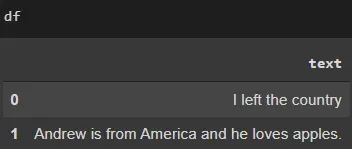
m=[] # empty list to save values for x in range(len(df['text'])): # here you can have any number of rows in dataframe doc=nlp(df['text'][x]) #here we are applying nlp on each row from text column in dataframe. for n in doc.noun_chunks: m.append(n.text) print(m) print(len(m)) # this gives the count of number of nouns in all text rows. 2年前
2年前