Lesson 13.3 梯度不平稳性与Glorot条件
从本节开始,我们将正式进入优化方法的具体方法部分。首先是关于激活函数使用过程的优化。在上一节的最后,我们发现虽然使用激活函数可以有效提高神经网络模型的性能,但是激活函数的简单叠加会导致模型出现很多问题。深度学习最初是一种深度神经网络。如果激活函数的叠加过程中遇到的问题没有解决,深度神经网络就无法构建。
本节将从上一节建模过程中遇到的问题开始,在堆叠激活函数后,讨论这些问题的根源,以及如何通过一些优化方法来解决这些问题。
- 模型病变和模型调整
在正式进入到模型优化方法之前,我们需要简单了解到底什么是模型优化。有很多初学者会简单的认为模型优化方法就是能让模型得出更好结果的方法,但实际上模型优化更像是对“患病”的模型进行诊断、然后对症下药,通过这些“治疗”方法,最终让模型运行恢复正常且健康的状态,并得出较好的模型预测结果。尽管优化方法就像一种种药品,各自都标注了适用的病症,但深度学习模型在某种程度上就像人体一样,是个非常复杂的系统,很多时候并不是“A药治A病”、并不是一个“只要…就…”的命题。模型优化和疾病治疗一样,很多时候都是多种手段作用于复杂系统、最终通过这个复杂系统自身的特性发挥作用。业余算法工程师进行模型调优就像我们平时去药店买药,啥病买啥药,然后挑个贵的;而专业的算法工程师进行模型调优则更像医生为患者进行诊断,在了解病理的基础上,通过一些列更加专业的诊断手段判断病情,然后提出更加高效的综合性解决方案。
所以初级算法工程师只需要知道模型会出现什么样的问题(什么病),有什么方法可以解决(有什么药),而模型调优主要靠应用和反复调试(尝试各种方法),而更专业的算法工程师需要了解这些模型问题背后的原因,即模型中这些问题(病态)的原因,也需要掌握更丰富的模型问题诊断方法(不仅要看模型评价指标结果),然后了解优化方法的基本原理及其工作方式。当然,最关键的是你需要在长期的实践中积累经验,才能最终获得专业的进步。
正是从这些角度,在优化方法的内容中,我们不仅会介绍每种方法发挥作用的场景,更重要的是,我们会同时介绍深度学习模型建模过程中的一些典型问题。诊断这些问题的病理学、观点和方法,以及优化方法背后的“药理学”。为了帮助学生尽可能走向更专业的方向。
1.梯度消失和梯度爆炸
对于神经网络的复杂系统,模型训练过程中最基本、最常见的问题之一就是梯度消失和梯度爆炸。
我们知道,神经网络在进行反向传播的过程中,各参数层的梯度计算会涉及到激活函数导函数取值,具体来说,假设现在有一个三层的神经网络,其中两个隐藏层的激活函数为,对应的导函数为
,设X为输入训练的数据特征,y为标签,
为模型向前传播输出结果,
为第一层参数、
为第二层参数、
为第三层参数,loss为损失函数,则有如下计算公式:
每次前向传递计算的结果:
而loss是一个关于y和的函数,而y是常量,
是一个关于w的函数,因此loss也进行如下表示:
求解梯度时,假设
对应梯度为
,
对应梯度为
,
对应梯度为
。为了简化计算,我们假设所有
都是标量。根据链式法则,计算过程如下:
值得注意的是,此时激活函数的导函数在
中计算了两次,而在上述过程中,
是第一个隐藏层接收到的数据,
是第二个隐藏层接收到的数据层数据。如果比较是计算
的梯度,有如下过程:
我们发现激活函数的导数在计算过程中只出现一次。当然,如果我们是计算
的梯度,计算过程如下:
事实上,如果神经网络层数不断增加,激活函数的数量不断增加,那么在计算梯度的过程中,需要乘以第一层参数的激活函数导数的数量也会随之增加。增加,后续层的参数梯度也会增加。计算中涉及的激活函数导数的数量逐步减少。
当然,如果把上面的过程换成矩阵求导,公式的主要部分基本不变,只有最后一项会发生变化。由于最终的运算结果不能写成比较简洁的矩阵运算形式(矩阵自变量的实向量函数),这里以标量运算为例。
而累乘就容易造成指数级变化,当激活函数值、激活函数导函数值
或者参与相乘的参数取值(
)较大(>1)时,会出现
远大于
远大于
的情况,也就是神经网络前几层参数梯度非常大、而后几层参数梯度相对较小的情况,此时就被称为梯度爆炸,并且受到累乘效应的影响,前几层梯度也会大于甚至远大于1,此时就会造成模型迭代过程不稳定的情况发生;而反之如果上述几个变量均小于1,甚至远小于1,则会出现前几层参数梯度非常小、而后几层参数梯度非常大的情况,此时就被称为梯度消失,此时由于模型各层参数学习率伴随层数增加逐渐增加,并且由于构成梯度的基本参数均小于1,因此最后几层梯度也会小于1甚至远小于1,此时前几层参数梯度取值将非常小,甚至趋于0,因而会使得前几层的参数无法在迭代中得到更新。
综上所述,不同层参数的梯度在计算过程中存在很大差异,而这种差异是乘法效应,也可以简单理解为随着层数的增加呈指数变化的差异。而这种相乘效应会导致线性层参数的一部分梯度过大而另一部分过小,从而影响模型的平滑训练。由于具体原因,各层参数的梯度主要与两个因素有关,一是线性层的输入数据,如或
,二是激活函数导函数
的计算结果。
接下来,我们就从梯度消失和梯度爆炸的角度剖析Sigmoid和tanh激活函数叠加过程中可能存在的隐患。
二、Sigmoid和tanh激活函数的梯度更新问题
1.Sigmoid激活函数的梯度消失问题
- 理论描述
对于sigmoid激活函数来说,简答的叠加是极容易出现梯度消失的问题。sigmoid函数及导函数图像如下所示:
# 绘制Sigmoid函数的函数图像和导函数图像
X = torch.arange(-5, 5, 0.1)
X.requires_grad=True
sigmoid_y = torch.sigmoid(X)
# 反向传播
sigmoid_y.sum().backward()
# Sigmoid函数图像
plt.subplot(121)
plt.plot(X.detach(), sigmoid_y.detach())
plt.title("Sigmoid Function")
# Sigmoid导函数图像
plt.subplot(122)
plt.plot(X.detach(), X.grad.detach())
plt.title("Sigmoid Derivative function")
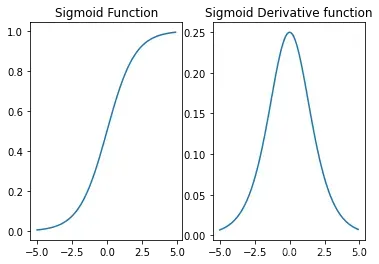
单独观察Sigmoid导函数
plt.plot(X.detach(), X.grad.detach())
plt.title("Sigmoid Derivative function")
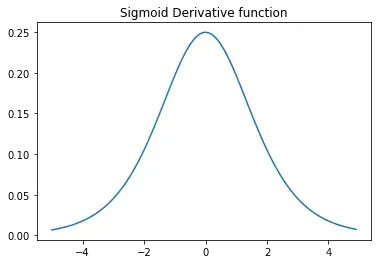
我们发现,Sigmoid导函数最大值为0.25(在0点处取到),当x较大或者较小时,导函数取值趋于0。
此时如果我们假设还是上述结构的三层神经网络,则第一层参数梯度由于计算过程出现两次导函数连乘,哪怕两次都导函数都取到最大值(虽然可能性较小),
都将在0.0625的基础上进行其余部分相乘,最终结果也极有可能是个非常小的值,因此对于Sigmoid激活函数叠加的情况来说,是极容易出现梯度消失情况的。
梯度消失或梯度爆炸总是一个概率问题。不能说导函数小就必然会出现梯度消失问题,但是导函数的最大值越小,梯度消失的可能性就越大。
- Sigmoid函数饱和区间
一般来说我们会将靠近sigmoid函数的左右两端的区间称为函数的饱和区间(如下图圈出部分)(也就是自变量绝对值较大的区间),不难发现,当自变量落入饱和区间时,因变量会趋于0或者1,而无论自变量是极小(负数绝对值极大)还是极大,都会使得导函数取值趋于0,从而更容易导致模型梯度消失。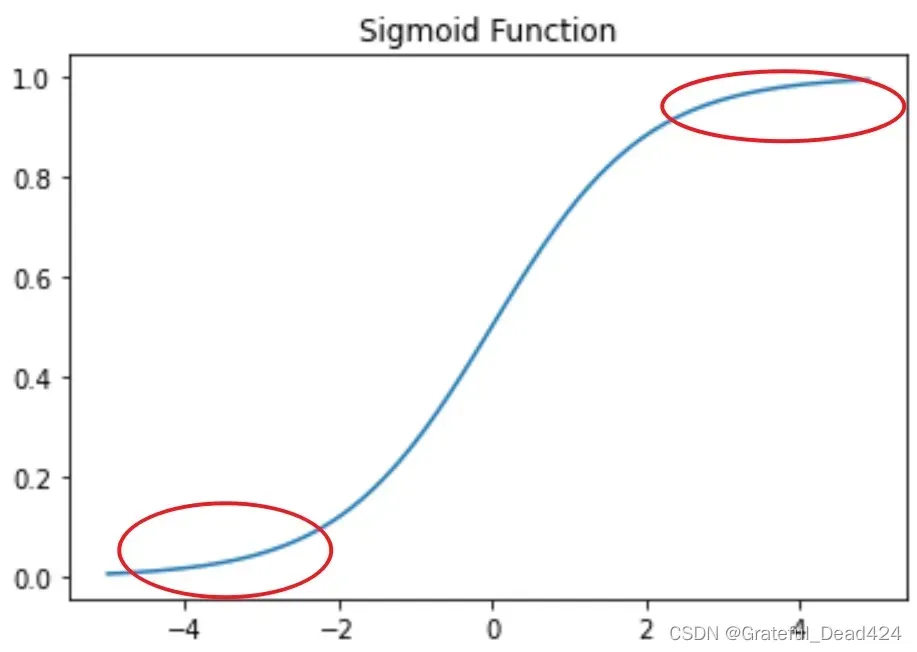
- Sigmoid激活函数叠加后的梯度消失问题
接下来,我们通过创建一个实例来观察Sigmoid激活函数叠加后梯度消失问题。
# 设置随机数种子
torch.manual_seed(420)
# 创建最高项为2的多项式回归数据集
features, labels = tensorGenReg(w=[2, -1], bias=False, deg=2)
# 进行数据集切分与加载
train_loader, test_loader = split_loader(features, labels)
然后使用此前定义的、拥有三个隐藏层(四个线性层)的Sigmoid_class3模型进行建模。
# 创建随机数种子
torch.manual_seed(420)
# 实例化模型
sigmoid_model3 = Sigmoid_class3()
然后我们来观察每一层的参数的梯度是如何随着迭代过程而变化的。
由于需要对各线性层参数的变化情况进行观察,此处我们也简单总结此前提到的关于模型参数和及其对应梯度的提取方法。首先是利用.parameters()方法观察模型所有参数。
pl = list(sigmoid_model3.parameters())
pl
#[Parameter containing:
# tensor([[ 0.4318, -0.4256],
# [ 0.6730, -0.5617],
# [-0.2157, -0.4873],
# [ 0.5453, 0.2653]], requires_grad=True),
# Parameter containing:
# tensor([-0.3527, -0.5469, -0.4094, -0.1364], requires_grad=True),
# Parameter containing:
# tensor([[-0.2552, 0.3644, -0.2104, -0.3271],
# [-0.1542, -0.4883, -0.2428, -0.2728],
# [ 0.1076, 0.4066, 0.0540, -0.2914],
# [ 0.2058, -0.2129, -0.2367, -0.0958]], requires_grad=True),
# Parameter containing:
# tensor([-0.2609, 0.0550, 0.4059, 0.0682], requires_grad=True),
# Parameter containing:
# tensor([[ 3.0199e-01, -4.3436e-01, -3.9335e-01, -6.6525e-02],
# [ 4.5806e-04, 3.1209e-01, -4.3974e-01, 2.0861e-01],
# [-4.2916e-01, 8.0655e-02, 3.3044e-01, 6.8971e-02],
# [ 1.5964e-01, 3.1789e-01, 4.9465e-01, -3.1377e-01]],
# requires_grad=True),
# Parameter containing:
# tensor([ 0.1638, 0.4116, 0.2843, -0.4529], requires_grad=True),
# Parameter containing:
# tensor([[-0.3468, -0.4897, 0.2213, 0.4947]], requires_grad=True),
# Parameter containing:
# tensor([-0.4843], requires_grad=True)]
.parameters()方法返回模型所有参数,包括截距,但需要使用list将其转化为显式的列表。此时列表中的每个元素都是带名称的张量,关于带名称的张量会在此后课程中介绍,此处我们只需要知道模型参数本身也是张量,并且是可微张量即可。并且,就像此前说到的一样,推导过程中我们使用数据是按照行排列,一行代表一条数据,一列代表数据的一个特征,而PyTorch在进行计算时,会将数据转化为按列排列,一列代表一条数据,因此PyTorch中我们查看到的模型参数和推导的模型参数互为转置关系。我们可以通过如下过程简单说明
f = torch.tensor([[1., 2]])
f # 行向量,代表一条数据
#tensor([[1., 2.]])
sigmoid_model3(f) # 返回最终输出结果
#tensor([[-0.5715]], grad_fn=<AddmmBackward>)
sigmoid_model3.modules()
#<generator object Module.modules at 0x0000026E622321C8>
list(sigmoid_model3.modules())
#[Sigmoid_class3(
# (linear1): Linear(in_features=2, out_features=4, bias=True)
# (linear2): Linear(in_features=4, out_features=4, bias=True)
# (linear3): Linear(in_features=4, out_features=4, bias=True)
# (linear4): Linear(in_features=4, out_features=1, bias=True)
# ),
# Linear(in_features=2, out_features=4, bias=True),
# Linear(in_features=4, out_features=4, bias=True),
# Linear(in_features=4, out_features=4, bias=True),
# Linear(in_features=4, out_features=1, bias=True)]
list(sigmoid_model3.modules())[1]
#Linear(in_features=2, out_features=4, bias=True)
list(sigmoid_model3.modules())[1](f) # 返回模型第一层输出结果
#tensor([[-0.7721, -0.9973, -1.5997, 0.9395]], grad_fn=<AddmmBackward>)
pl
#[Parameter containing:
# tensor([[ 0.4318, -0.4256],
# [ 0.6730, -0.5617],
# [-0.2157, -0.4873],
# [ 0.5453, 0.2653]], requires_grad=True),
# Parameter containing:
# tensor([-0.3527, -0.5469, -0.4094, -0.1364], requires_grad=True),
# Parameter containing:
# tensor([[-0.2552, 0.3644, -0.2104, -0.3271],
# [-0.1542, -0.4883, -0.2428, -0.2728],
# [ 0.1076, 0.4066, 0.0540, -0.2914],
# [ 0.2058, -0.2129, -0.2367, -0.0958]], requires_grad=True),
# Parameter containing:
# tensor([-0.2609, 0.0550, 0.4059, 0.0682], requires_grad=True),
# Parameter containing:
# tensor([[ 3.0199e-01, -4.3436e-01, -3.9335e-01, -6.6525e-02],
# [ 4.5806e-04, 3.1209e-01, -4.3974e-01, 2.0861e-01],
# [-4.2916e-01, 8.0655e-02, 3.3044e-01, 6.8971e-02],
# [ 1.5964e-01, 3.1789e-01, 4.9465e-01, -3.1377e-01]],
# requires_grad=True),
# Parameter containing:
# tensor([ 0.1638, 0.4116, 0.2843, -0.4529], requires_grad=True),
# Parameter containing:
# tensor([[-0.3468, -0.4897, 0.2213, 0.4947]], requires_grad=True),
# Parameter containing:
# tensor([-0.4843], requires_grad=True)]
torch.mm(f, pl[0].t()) + pl[1].t() # 手动实现
#tensor([[-0.7721, -0.9973, -1.5997, 0.9395]], grad_fn=<AddBackward0>)
当然,我们还可以通过.module方法,观察构成该模型的每个线性层的参数。
ml = list(sigmoid_model3.modules())
ml
#[Sigmoid_class3(
# (linear1): Linear(in_features=2, out_features=4, bias=True)
# (linear2): Linear(in_features=4, out_features=4, bias=True)
# (linear3): Linear(in_features=4, out_features=4, bias=True)
# (linear4): Linear(in_features=4, out_features=1, bias=True)
# ),
# Linear(in_features=2, out_features=4, bias=True),
# Linear(in_features=4, out_features=4, bias=True),
# Linear(in_features=4, out_features=4, bias=True),
# Linear(in_features=4, out_features=1, bias=True)]
ml中,除了第一个元素是自定义的类以外,其他的都是构成模型的线性层。
list(ml[0].parameters()) # ml中第一个元素和模型相同
#[Parameter containing:
# tensor([[ 0.4318, -0.4256],
# [ 0.6730, -0.5617],
# [-0.2157, -0.4873],
# [ 0.5453, 0.2653]], requires_grad=True),
# Parameter containing:
# tensor([-0.3527, -0.5469, -0.4094, -0.1364], requires_grad=True),
# Parameter containing:
# tensor([[-0.2552, 0.3644, -0.2104, -0.3271],
# [-0.1542, -0.4883, -0.2428, -0.2728],
# [ 0.1076, 0.4066, 0.0540, -0.2914],
# [ 0.2058, -0.2129, -0.2367, -0.0958]], requires_grad=True),
# Parameter containing:
# tensor([-0.2609, 0.0550, 0.4059, 0.0682], requires_grad=True),
# Parameter containing:
# tensor([[ 3.0199e-01, -4.3436e-01, -3.9335e-01, -6.6525e-02],
# [ 4.5806e-04, 3.1209e-01, -4.3974e-01, 2.0861e-01],
# [-4.2916e-01, 8.0655e-02, 3.3044e-01, 6.8971e-02],
# [ 1.5964e-01, 3.1789e-01, 4.9465e-01, -3.1377e-01]],
# requires_grad=True),
# Parameter containing:
# tensor([ 0.1638, 0.4116, 0.2843, -0.4529], requires_grad=True),
# Parameter containing:
# tensor([[-0.3468, -0.4897, 0.2213, 0.4947]], requires_grad=True),
# Parameter containing:
# tensor([-0.4843], requires_grad=True)]
ml[1] # 其他元素都是线性层
#Linear(in_features=2, out_features=4, bias=True)
list(ml[1].parameters())
#[Parameter containing:
# tensor([[ 0.4318, -0.4256],
# [ 0.6730, -0.5617],
# [-0.2157, -0.4873],
# [ 0.5453, 0.2653]], requires_grad=True),
# Parameter containing:
# tensor([-0.3527, -0.5469, -0.4094, -0.1364], requires_grad=True)]
线性层可以使用weight返回其自变量权重,通过bias返回其截距
ml[1].weight
#Parameter containing:
#tensor([[ 0.4318, -0.4256],
# [ 0.6730, -0.5617],
# [-0.2157, -0.4873],
# [ 0.5453, 0.2653]], requires_grad=True)
ml[1].bias
#Parameter containing:
#tensor([-0.3527, -0.5469, -0.4094, -0.1364], requires_grad=True)
同时,一个单独的线性层也可以看作是一个独立的“模型”,输入数据也可以输出结果。此时的结果相当于模型的中间结果。
ml[0].bias
#ModuleAttributeError: 'Sigmoid_class3' object has no attribute 'bias'
ml[1](f)
#tensor([[-0.7721, -0.9973, -1.5997, 0.9395]], grad_fn=<AddmmBackward>)
sigmoid_model3(f)[1]
#tensor([[-0.7721, -0.9973, -1.5997, 0.9395]], grad_fn=<AddmmBackward>)
因此,我们目前所使用的模型,也可以称为线性层叠加模型。不过这种通过线性层模块单独提取参数的方法需要注意,每一个线性层的weight和bias(如果有的话)是单独的属性,实际建模过程中需要视情况提取weight或者bias。
# 提取weight
for m in sigmoid_model3.modules():
if isinstance(m, nn.Linear):
print(m.weight)
#Parameter containing:
#tensor([[ 0.4318, -0.4256],
# [ 0.6730, -0.5617],
# [-0.2157, -0.4873],
# [ 0.5453, 0.2653]], requires_grad=True)
#Parameter containing:
#tensor([[-0.2552, 0.3644, -0.2104, -0.3271],
# [-0.1542, -0.4883, -0.2428, -0.2728],
# [ 0.1076, 0.4066, 0.0540, -0.2914],
# [ 0.2058, -0.2129, -0.2367, -0.0958]], requires_grad=True)
#Parameter containing:
#tensor([[ 3.0199e-01, -4.3436e-01, -3.9335e-01, -6.6525e-02],
# [ 4.5806e-04, 3.1209e-01, -4.3974e-01, 2.0861e-01],
# [-4.2916e-01, 8.0655e-02, 3.3044e-01, 6.8971e-02],
# [ 1.5964e-01, 3.1789e-01, 4.9465e-01, -3.1377e-01]],
# requires_grad=True)
#Parameter containing:
#tensor([[-0.3468, -0.4897, 0.2213, 0.4947]], requires_grad=True)
# 提取weight
for m in sigmoid_model3.modules():
if isinstance(m, nn.Linear):
print(m.bias)
#Parameter containing:
#tensor([-0.3527, -0.5469, -0.4094, -0.1364], requires_grad=True)
#Parameter containing:
#tensor([-0.2609, 0.0550, 0.4059, 0.0682], requires_grad=True)
#Parameter containing:
#tensor([ 0.1638, 0.4116, 0.2843, -0.4529], requires_grad=True)
#Parameter containing:
#tensor([-0.4843], requires_grad=True)
当然,我们也可直接使用.grad查看梯度。但由于目前模型还未训练,因此返回结果为None。后续查看每一个线性层梯度时可以使用如下方法:
# 提取weight
for m in sigmoid_model3.modules():
if isinstance(m, nn.Linear):
print(m.weight.grad)
#None
#None
#None
#None
有了以上基础知识铺垫,就可以开始后续的学习了。
接下来训练模型,观察数据遍历五次后的参数变化。
fit(net = sigmoid_model3,
criterion = nn.MSELoss(),
optimizer = optim.SGD(sigmoid_model3.parameters(), lr = 0.03),
batchdata = train_loader,
epochs=5,
cla=False)
for m in sigmoid_model3.modules():
if isinstance(m, nn.Linear):
print(m.weight)
#Parameter containing:
#tensor([[ 0.4373, -0.4245],
# [ 0.7056, -0.5486],
# [-0.2127, -0.4852],
# [ 0.5289, 0.2734]], requires_grad=True)
#Parameter containing:
#tensor([[-0.2630, 0.3532, -0.2101, -0.3368],
# [-0.1429, -0.4673, -0.2501, -0.2617],
# [ 0.1525, 0.4754, 0.0487, -0.2464],
# [ 0.1905, -0.2353, -0.2352, -0.1144]], requires_grad=True)
#Parameter containing:
#tensor([[ 0.2611, -0.4749, -0.4613, -0.1173],
# [-0.0566, 0.2591, -0.5354, 0.1386],
# [-0.4262, 0.0491, 0.3438, 0.0642],
# [ 0.1865, 0.2986, 0.5505, -0.2915]], requires_grad=True)
#Parameter containing:
#tensor([[ 0.0477, -0.0260, 0.6937, 0.8508]], requires_grad=True)
通过和模型训练前的惯出对比,不难看出,第一层线性层参数变化非常小,而最后一层参数值变化较大。不过这种观察还是比较粗糙的,我们希望能够观察到每一轮迭代结束后各层参数的梯度。由于我们定义的fit函数是在每一轮开始时将梯度清零,而每一轮迭代结束时还会保留梯度,因此我们可以直接使用.grad查看当前各层参数梯度情况。
关于在训练模型时是在每轮开始时清除梯度还是在结束时清除梯度,效果基本相同。由于我们需要在每轮迭代后检查梯度,因此之前的函数是使用每轮开始时的时间创建的。清除上一轮渐变的设置。
for m in sigmoid_model3.modules():
if isinstance(m, nn.Linear):
print(m.weight.grad)
#tensor([[ 2.1808e-04, -6.1006e-04],
# [-4.7424e-06, -1.8825e-03],
# [ 5.0653e-04, -5.8459e-04],
# [-2.1380e-03, 2.5715e-03]])
#tensor([[-0.0012, -0.0013, -0.0007, -0.0003],
# [ 0.0028, 0.0030, 0.0015, 0.0006],
# [ 0.0070, 0.0075, 0.0038, 0.0014],
# [-0.0024, -0.0026, -0.0014, -0.0006]])
#tensor([[ 1.8960e-04, -1.5584e-04, 6.4209e-04, 1.6556e-04],
# [-1.0389e-04, 8.5139e-05, -3.5157e-04, -9.0795e-05],
# [ 2.5782e-03, -2.4119e-03, 8.9966e-03, 2.1951e-03],
# [ 3.3940e-03, -2.9424e-03, 1.1632e-02, 2.9350e-03]])
#tensor([[0.0200, 0.0185, 0.0296, 0.0250]])
从以上结果可以看出,前几层的梯度较小,后几层的梯度较大。当然,更直观的观察方法是通过绘制小提琴图来观察每一层的梯度。具体流程如下:
import seaborn as sns # 导入seaborn绘图包,后续需要将其添加进启动项
vp = [] # 创建空列表用于存储每一层参数的梯度
for i, m in enumerate(sigmoid_model3.modules()):
if isinstance(m, nn.Linear):
vp_x = m.weight.grad.detach().reshape(-1, 1).numpy() # 每一层参数梯度
vp_y = np.full_like(vp_x, i) # 对层进行标记
vp_a = np.concatenate((vp_x, vp_y), 1)
vp.append(vp_a)
vp
# [array([[ 2.1808085e-04, 1.0000000e+00],
# [-6.1006239e-04, 1.0000000e+00],
# [-4.7424110e-06, 1.0000000e+00],
# [-1.8825047e-03, 1.0000000e+00],
# [ 5.0653063e-04, 1.0000000e+00],
# [-5.8459304e-04, 1.0000000e+00],
# [-2.1380028e-03, 1.0000000e+00],
# [ 2.5715115e-03, 1.0000000e+00]], dtype=float32),
# array([[-1.1987914e-03, 2.0000000e+00],
# [-1.2711009e-03, 2.0000000e+00],
# [-6.8579812e-04, 2.0000000e+00],
# [-2.9897725e-04, 2.0000000e+00],
# [ 2.7674725e-03, 2.0000000e+00],
# [ 2.9552632e-03, 2.0000000e+00],
# [ 1.5215666e-03, 2.0000000e+00],
# [ 6.3543138e-04, 2.0000000e+00],
# [ 6.9975322e-03, 2.0000000e+00],
# [ 7.4815727e-03, 2.0000000e+00],
# [ 3.8293116e-03, 2.0000000e+00],
# [ 1.4357837e-03, 2.0000000e+00],
# [-2.4192045e-03, 2.0000000e+00],
# [-2.5585447e-03, 2.0000000e+00],
# [-1.4026740e-03, 2.0000000e+00],
# [-6.1361748e-04, 2.0000000e+00]], dtype=float32),
# array([[ 1.8960494e-04, 3.0000000e+00],
# [-1.5583623e-04, 3.0000000e+00],
# [ 6.4209045e-04, 3.0000000e+00],
# [ 1.6556284e-04, 3.0000000e+00],
# [-1.0388688e-04, 3.0000000e+00],
# [ 8.5139473e-05, 3.0000000e+00],
# [-3.5156531e-04, 3.0000000e+00],
# [-9.0795278e-05, 3.0000000e+00],
# [ 2.5782324e-03, 3.0000000e+00],
# [-2.4119318e-03, 3.0000000e+00],
# [ 8.9966338e-03, 3.0000000e+00],
# [ 2.1950752e-03, 3.0000000e+00],
# [ 3.3940002e-03, 3.0000000e+00],
# [-2.9423889e-03, 3.0000000e+00],
# [ 1.1631813e-02, 3.0000000e+00],
# [ 2.9349811e-03, 3.0000000e+00]], dtype=float32),
# array([[0.01997625, 4. ],
# [0.01845115, 4. ],
# [0.02955662, 4. ],
# [0.02495749, 4. ]], dtype=float32)]
vp_r = np.concatenate((vp), 0) # 拼接行
vp_r
#array([[ 2.1808085e-04, 1.0000000e+00],
# [-6.1006239e-04, 1.0000000e+00],
# [-4.7424110e-06, 1.0000000e+00],
# [-1.8825047e-03, 1.0000000e+00],
# [ 5.0653063e-04, 1.0000000e+00],
# [-5.8459304e-04, 1.0000000e+00],
# [-2.1380028e-03, 1.0000000e+00],
# [ 2.5715115e-03, 1.0000000e+00],
# [-1.1987914e-03, 2.0000000e+00],
# [-1.2711009e-03, 2.0000000e+00],
# [-6.8579812e-04, 2.0000000e+00],
# [-2.9897725e-04, 2.0000000e+00],
# [ 2.7674725e-03, 2.0000000e+00],
# [ 2.9552632e-03, 2.0000000e+00],
# [ 1.5215666e-03, 2.0000000e+00],
# [ 6.3543138e-04, 2.0000000e+00],
# [ 6.9975322e-03, 2.0000000e+00],
# [ 7.4815727e-03, 2.0000000e+00],
# [ 3.8293116e-03, 2.0000000e+00],
# [ 1.4357837e-03, 2.0000000e+00],
# [-2.4192045e-03, 2.0000000e+00],
# [-2.5585447e-03, 2.0000000e+00],
# [-1.4026740e-03, 2.0000000e+00],
# [-6.1361748e-04, 2.0000000e+00],
# [ 1.8960494e-04, 3.0000000e+00],
# [-1.5583623e-04, 3.0000000e+00],
# [ 6.4209045e-04, 3.0000000e+00],
# [ 1.6556284e-04, 3.0000000e+00],
# [-1.0388688e-04, 3.0000000e+00],
# [ 8.5139473e-05, 3.0000000e+00],
# [-3.5156531e-04, 3.0000000e+00],
# [-9.0795278e-05, 3.0000000e+00],
# [ 2.5782324e-03, 3.0000000e+00],
# [-2.4119318e-03, 3.0000000e+00],
# [ 8.9966338e-03, 3.0000000e+00],
# [ 2.1950752e-03, 3.0000000e+00],
# [ 3.3940002e-03, 3.0000000e+00],
# [-2.9423889e-03, 3.0000000e+00],
# [ 1.1631813e-02, 3.0000000e+00],
# [ 2.9349811e-03, 3.0000000e+00],
# [ 1.9976251e-02, 4.0000000e+00],
# [ 1.8451154e-02, 4.0000000e+00],
# [ 2.9556617e-02, 4.0000000e+00],
# [ 2.4957493e-02, 4.0000000e+00]], dtype=float32)
vp_r[:, 0] # 每一层梯度
#array([ 2.1808085e-04, -6.1006239e-04, -4.7424110e-06, -1.8825047e-03,
# 5.0653063e-04, -5.8459304e-04, -2.1380028e-03, 2.5715115e-03,
# -1.1987914e-03, -1.2711009e-03, -6.8579812e-04, -2.9897725e-04,
# 2.7674725e-03, 2.9552632e-03, 1.5215666e-03, 6.3543138e-04,
# 6.9975322e-03, 7.4815727e-03, 3.8293116e-03, 1.4357837e-03,
# -2.4192045e-03, -2.5585447e-03, -1.4026740e-03, -6.1361748e-04,
# 1.8960494e-04, -1.5583623e-04, 6.4209045e-04, 1.6556284e-04,
# -1.0388688e-04, 8.5139473e-05, -3.5156531e-04, -9.0795278e-05,
# 2.5782324e-03, -2.4119318e-03, 8.9966338e-03, 2.1950752e-03,
# 3.3940002e-03, -2.9423889e-03, 1.1631813e-02, 2.9349811e-03,
# 1.9976251e-02, 1.8451154e-02, 2.9556617e-02, 2.4957493e-02],
# dtype=float32)
ax = sns.violinplot(y = vp_r[:, 0], x = vp_r[:, 1])
ax.set(xlabel='num_hidden', title='Gradients')

小提琴图实际上是一个统计分析图像,其基本含义如下: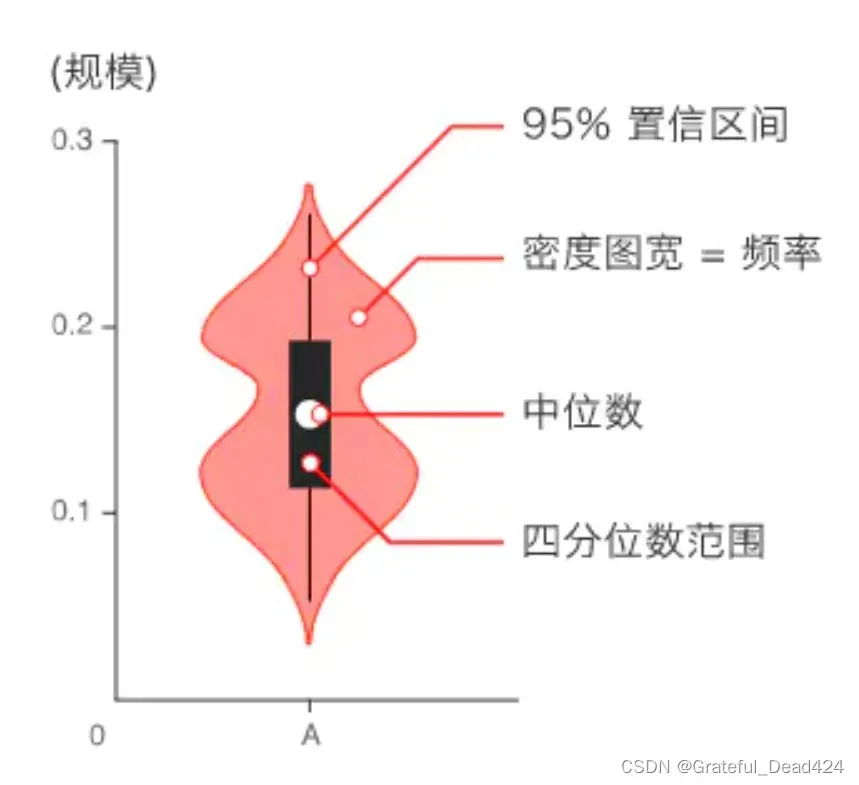
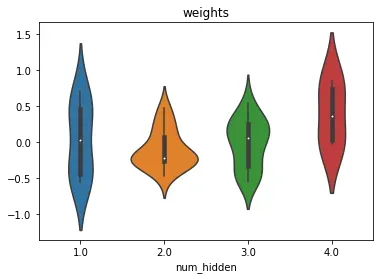
当然,为了更全面地观察模型迭代过程中数据和参数的变化,我们继续为每一层添加输入数据(也称为扇入数据),输出经过激活函数处理的数据(也称为扇入数据) – 数据)。是扇出数据)和每个线性层自身参数的小提琴图。
vp = []
for i, m in enumerate(sigmoid_model3.modules()):
if isinstance(m, nn.Linear):
vp_x = m.weight.detach().reshape(-1, 1).numpy()
vp_y = np.full_like(vp_x, i)
vp_a = np.concatenate((vp_x, vp_y), 1)
vp.append(vp_a)
vp_r = np.concatenate((vp), 0)
ax = sns.violinplot(y = vp_r[:, 0], x = vp_r[:, 1])
ax.set(xlabel='num_hidden', title='weights')
当然,我们也可以将上述过程封装成一个函数。
def weights_vp(model, att="grad"):
"""观察各层参数取值和梯度的小提琴图绘图函数。
:param model:观察对象(模型)
:param att:选择参数梯度(grad)还是参数取值(weights)进行观察
:return: 对应att的小提琴图
"""
vp = []
for i, m in enumerate(model.modules()):
if isinstance(m, nn.Linear):
if att == "grad":
vp_x = m.weight.grad.detach().reshape(-1, 1).numpy()
else:
vp_x = m.weight.detach().reshape(-1, 1).numpy()
vp_y = np.full_like(vp_x, i)
vp_a = np.concatenate((vp_x, vp_y), 1)
vp.append(vp_a)
vp_r = np.concatenate((vp), 0)
ax = sns.violinplot(y = vp_r[:, 0], x = vp_r[:, 1])
ax.set(xlabel='num_hidden', title=att)
测试功能性能
weights_vp(sigmoid_model3, att="grad")

weights_vp(sigmoid_model3, att="weight")
后续该函数也需要写入torchLearning模块中,并且sns模块导入方法也需要导入,同时也可以将sns导入代码写入startup.py文件中作为初始化默认导入的包。
值得注意的是,对于Sigmoid激活函数的梯度消失问题,是伴随着迭代次数增加或者隐藏层增加会愈发明显。
fit(net = sigmoid_model3,
criterion = nn.MSELoss(),
optimizer = optim.SGD(sigmoid_model3.parameters(), lr = 0.03),
batchdata = train_loader,
epochs=20,
cla=False)
weights_vp(sigmoid_model3, att="grad")

至此,我们也可以借助上述理论理解 Lesson 13.2中Sigmoid激活函数叠加之后所呈现出的状态。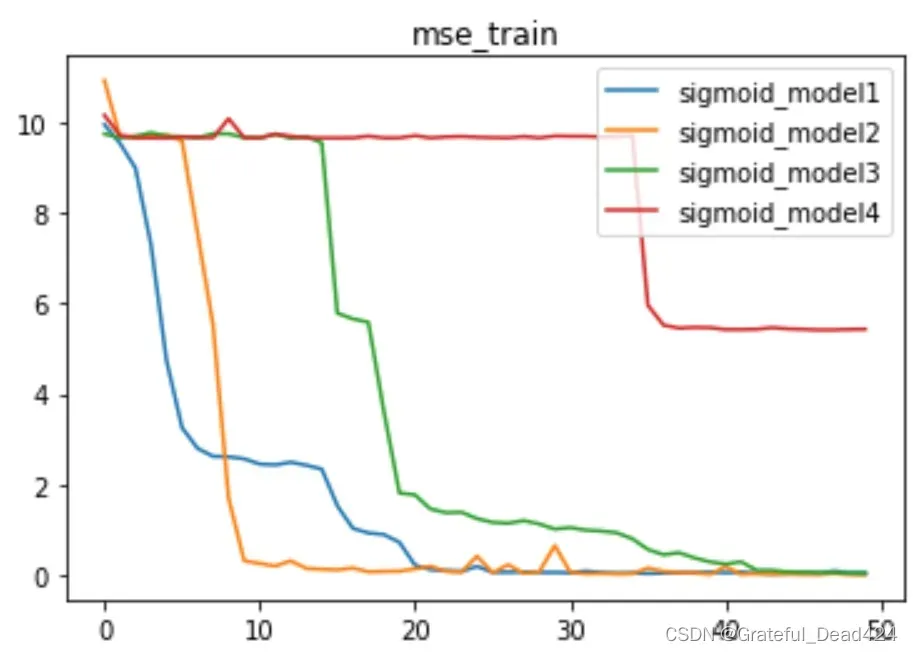
由于Sigmoid激活函数叠加会造成严重梯度消失问题,因此复杂模型,如Sigmoid3和Sigmoid4的前几层在迭代过程中逐渐丧失变化的可能性,也就是学习能力,从而导致经过了很多轮的迭代,但最终结果只能和Sigmoid2和Sigmoid3持平的情况。
需要注意的是,对于复杂模型,如果某些层失去了学习能力(参数迭代的可能性),模型的判别效果与简单模型没有区别。由此也可以看出复杂模型的有效训练的重要性。
2.tanh函数的梯度计算问题
如果说Sigmoid激活函数叠加更容易造成梯度消失,那tanh激活函数叠加是不是也是如此呢?首先我们来观察tanh激活函数导函数性质。
# 绘制tanh函数的函数图像和导函数图像
X = torch.arange(-5, 5, 0.1)
X.requires_grad=True
tanh_y = torch.tanh(X)
# 反向传播
tanh_y.sum().backward()
# tanh函数图像
plt.subplot(121)
plt.plot(X.detach(), tanh_y.detach())
plt.title("tanh Function")
# tanh导函数图像
plt.subplot(122)
plt.plot(X.detach(), X.grad.detach())
plt.title("tanh Derivative function")
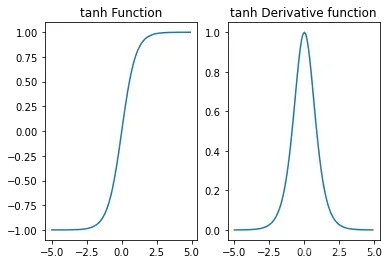
对于tanh函数来说,导函数的取值分布在0-1之间的,看似导函数取值累乘之后也是趋于0的,但实际上,tanh激活函数的叠加即可能造成梯度消失、同时也可能造成梯度爆炸,原因是在实际建模过程中,影响前几层梯度的其他变量大多数情况都大于1,因此对于一个导函数极大值可以取到1的激活函数来说,还是有可能出现梯度爆炸的情况的。
在梯度爆炸和梯度消失中,前几层的所谓梯度太大或太小。另外,梯度爆炸和梯度消失的直接表现可以归结为前后参数层的梯度不一致,两者的根本问题是影响迭代收敛过程。
作为Sigmoid激活函数的“升级版”,tanh激活函数除了能够一定程度规避梯度消失问题外,还能够生成Zero-Centered Data,而确保输入层接收到Zero-Centered Data,则是解决梯度消失和梯度爆炸问题的关键。
和Sigmoid激活函数一样,我们可以通过绘制小提琴图观察多轮迭代后,tanh激活函数叠加的神经网络是否会出现梯度消失或者梯度爆炸的情况。类似的,首先我们利用此前定义的模型,实例化一个拥有四个隐藏层(五个线性层)的以tanh为激活函数的模型,然后观察模型在迭代过程中梯度变化情况。
# 创建随机数种子
torch.manual_seed(420)
# 实例化模型
tanh_model4 = tanh_class4()
# 观察各层参数
for m in tanh_model4.modules():
if isinstance(m, nn.Linear):
print(m.weight)
#Parameter containing:
#tensor([[ 0.4318, -0.4256],
# [ 0.6730, -0.5617],
# [-0.2157, -0.4873],
# [ 0.5453, 0.2653]], requires_grad=True)
#Parameter containing:
#tensor([[-0.2552, 0.3644, -0.2104, -0.3271],
# [-0.1542, -0.4883, -0.2428, -0.2728],
# [ 0.1076, 0.4066, 0.0540, -0.2914],
# [ 0.2058, -0.2129, -0.2367, -0.0958]], requires_grad=True)
#Parameter containing:
#tensor([[ 3.0199e-01, -4.3436e-01, -3.9335e-01, -6.6525e-02],
# [ 4.5806e-04, 3.1209e-01, -4.3974e-01, 2.0861e-01],
# [-4.2916e-01, 8.0655e-02, 3.3044e-01, 6.8971e-02],
# [ 1.5964e-01, 3.1789e-01, 4.9465e-01, -3.1377e-01]],
# requires_grad=True)
#Parameter containing:
#tensor([[-0.3468, -0.4897, 0.2213, 0.4947],
# [-0.4843, 0.3998, -0.4678, -0.0610],
# [ 0.4057, -0.0786, 0.0555, 0.3645],
# [-0.4194, 0.1265, -0.2440, 0.4589]], requires_grad=True)
#Parameter containing:
#tensor([[-0.2952, 0.1712, -0.3926, 0.2928]], requires_grad=True)
# 模型训练
train_l, test_l = model_train_test(tanh_model4,
train_loader,
test_loader,
num_epochs = 5,
criterion = nn.MSELoss(),
optimizer = optim.SGD,
lr = 0.03,
cla = False,
eva = mse_cal)
# 观察各层参数
for m in tanh_model4.modules():
if isinstance(m, nn.Linear):
print(m.weight)
#Parameter containing:
#tensor([[ 1.6769, -0.6027],
# [ 1.3749, -1.1713],
# [-1.2316, 0.4022],
# [ 0.7930, 0.8796]], requires_grad=True)
#Parameter containing:
#tensor([[-1.3399, 0.1283, -0.6818, -1.2345],
# [ 0.1208, -0.4748, -0.6172, 1.2410],
# [ 0.5063, 1.3194, -0.3683, -0.4244],
# [-0.2189, -0.3174, -1.0260, 1.0486]], requires_grad=True)
#Parameter containing:
#tensor([[ 1.2209, -0.2646, -1.4842, 0.0036],
# [-0.4049, 1.0204, -1.5835, 0.6733],
# [-0.4540, 0.8314, 0.7015, 1.1003],
# [ 0.9633, 0.0759, 0.9421, -0.3454]], requires_grad=True)
#Parameter containing:
#tensor([[-0.5470, -1.1383, -0.0333, 0.8862],
# [-1.4907, 0.9662, -1.7399, -0.3322],
# [ 1.5209, -0.2784, 0.1876, 0.2312],
# [-0.9778, 1.3098, -0.9836, 0.6102]], requires_grad=True)
#Parameter containing:
#tensor([[-2.8199, 2.0906, -1.3815, 1.6865]], requires_grad=True)
# 观察各层梯度
for m in tanh_model4.modules():
if isinstance(m, nn.Linear):
print(m.weight.grad)
#tensor([[-0.0971, -0.0493],
# [ 0.0441, 0.1050],
# [ 2.2989, 1.2395],
# [-0.2245, -0.1881]])
#tensor([[-0.1136, -0.0416, -0.1321, 0.1183],
# [-0.9492, -0.8461, -0.3950, -0.9318],
# [-0.4514, -0.4854, -0.1851, -0.3405],
# [-1.0763, -0.9551, -0.4483, -1.0507]])
#tensor([[ 0.1131, 0.1137, 0.0849, 0.1336],
# [-0.1081, -0.0071, 0.0344, -0.0783],
# [ 1.2732, -0.3419, -0.7359, 0.6891],
# [-0.0879, 0.5006, -0.1024, 0.1304]])
#tensor([[ 0.0347, 0.0432, 0.0330, 0.0181],
# [-0.3551, -0.3562, -0.1436, 0.0340],
# [ 0.0351, 0.0417, 0.0063, 0.0320],
# [-0.1548, -0.1800, 0.2662, -0.3853]])
#tensor([[ 0.2976, 0.2090, -0.2891, -0.5080]])
从以上结果可以看出,每一层的梯度分布严重不均匀,前几层的个体梯度极不平衡。接下来,我们通过小提琴图来观察
weights_vp(tanh_model4, att="grad")

能够看出,上述模型存在一定程度的梯度爆炸的情况。当然,对于tanh激活函数来说,由于激活函数本身的良好特性(也就是能够输出Zero-Centered Data),一般不会出现典型的梯度消失情况。但梯度爆炸同样会极大影响模型训练过程的稳定性,并且这种现象并不会因为模型迭代次数增加而消失。
# 创建随机数种子
torch.manual_seed(420)
# 实例化模型
tanh_model4 = tanh_class4()
train_l, test_l = model_train_test(tanh_model4,
train_loader,
test_loader,
num_epochs = 20,
criterion = nn.MSELoss(),
optimizer = optim.SGD,
lr = 0.03,
cla = False,
eva = mse_cal)
# 观察各层梯度
for m in tanh_model4.modules():
if isinstance(m, nn.Linear):
print(m.weight.grad)
#tensor([[ 1.0317e-05, 3.5053e-05],
# [-2.5057e-01, -2.9602e-01],
# [-3.1448e-06, -2.8048e-06],
# [-1.1055e-02, 1.4788e-02]])
#tensor([[ 0.0000, 0.0000, 0.0000, 0.0000],
# [-0.0246, 0.0120, -0.0246, -0.0260],
# [ 0.0419, -0.0323, 0.0419, -0.0122],
# [ 0.0579, -0.0249, 0.0579, 0.0560]])
#tensor([[ 2.6012e-06, 2.5827e-06, 1.3773e-06, 2.5614e-06],
# [ 7.2884e-07, 7.4305e-07, -7.7778e-07, 7.5927e-07],
# [-6.5680e-06, -6.6777e-06, 6.6495e-06, -6.8025e-06],
# [ 5.4093e-01, 5.4630e-01, -5.4844e-01, 5.5242e-01]])
#tensor([[-6.0082e-04, -6.0082e-04, -6.0082e-04, -6.1511e-06],
# [ 1.7472e-04, 1.7472e-04, 1.7471e-04, 5.3078e-06],
# [-3.3488e-02, -3.3487e-02, -3.3486e-02, 4.8263e-03],
# [ 1.8628e-01, 1.8629e-01, 1.8628e-01, 9.3897e-03]])
#tensor([[-0.6668, -0.6669, 0.6618, 0.6259]])
weights_vp(tanh_model4, att="grad")

我们发现,随着迭代次数增加,这种梯度爆炸的情况有增无减。从该角度出发,我们也能理解为何tanh4在Lesson 13.2中迭代过程如此不平稳的原因。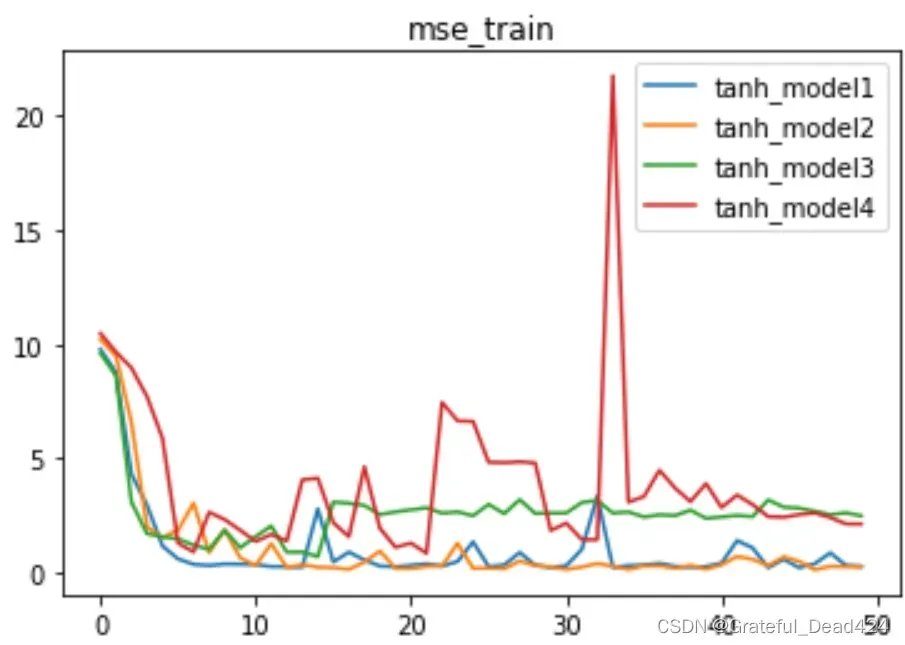
从根本上来说,tanh激活函数的迭代不平稳就是因为部分层的部分梯度存在极端值,当然,这种极端值也导致部分层无法有效学习、最终影响模型效果。
三、Zero-Centered Data与Glorot条件
通过对Sigmoid和tanh激活函数叠加后的模型梯度变化情况分析,我们不难发现,梯度不平稳是影响模型建模效果的非常核心的因素。而这个看似简单问题的解决方案,却花费了研究人员数十年的时间才逐渐完善,我们现在所接触到的优化方法,也基本上是在15年前后提出的,而这些被验证的切实可行的优化方法,也是推动这一轮深度学习浪潮的技术因素。
当然,这些优化方法主要是针对深度神经网络的。
整体来看,针对梯度不平稳的解决方案(优化方法)总共分为五类,分别是参数初始化方法、输入数据的归一化方法、衍生激活函数使用方法、学习率调度方法以及梯度下降优化方法。接下来,先介绍所有上述优化算法的一个基本理论,由Xavier Glorot在2010提出的Glorot条件。
值得注意的是,虽然不同优化算法有不同的出发点和不同的论证方式,但基本都可以从Glorot条件出发进行思考。
1.Zero-centered Data
在介绍Glorot条件之前,我们先从一个更加朴素的角度出发,讨论关于Zero-Centered Data相关作用,从而帮助我们理解后续Glorot条件。
首先,我们还是假设当前模型是一个三层神经网络,其中两个隐藏层的激活函数为,对应的导函数为
,设X为输入训练的数据特征,y为标签,
为模型向前传播输出结果,
为第一层参数、
为第二层参数、
为第三层参数,loss为损失函数,则有如下计算公式:
每一次正向传播计算结果:假设
为第i层接收到的数据,
为第i层输出的数据,则有:
依次类推。而在反向传播过程,各参数层的梯度如下在梯度消失和梯度爆炸的案例中,我们不难发现,为了确保多层神经网络的有效性,各层梯度的差距不应太大,此时一个最为基本的想法就是,就是能否让所有的输入数据(也就是X)以及所有层的参数都设置为Zero-Centered Data,也就是零点对称数据,不难发现,由于X和
都是零点对称的,因此每一个线性层中的导函数也取值也能够维持在0-1之间,进而每一层的梯度基本能维持在比较平稳的状态。
另外,除了能够避免梯度不平稳问题以外,创建Zero-Centered的参数和数据集,还能够更好的在正向传播中将信息传播到各层,以及确保各层学习的平稳性。
关于如何将带入模型训练的数据转化为Zero-Centered Data,一般来说我们会使用一系列标准化方法对其进行转化,具体方法我们会在Lesson 14进行详细介绍,由于我们此前创建的数据生成器生成的就是Zero-Centered Data,因此暂时这些数据不会影响接下来的优化方法使用。而如何将参数转化为Zero-Centered Data,就是核心需要考虑的问题了。
对于输入的数据来说,我们可以尽量保证其Zero-Centered的特性,但模型参数是随着模型迭代不断变化的,我们无法把控模型每一轮迭代后的情况,因此只能从模型参数初始值入手,尽量保证其Zero-Centered属性。
当然,既然是创建Zero-Centered参数,那能否创建初始值全是0的参数呢?我们可以简单尝试一下:
class Sigmoid_class1_test(nn.Module):
def __init__(self, in_features=2, n_hidden=2, out_features=1, bias=False):
super(Sigmoid_class1_test, self).__init__()
self.linear1 = nn.Linear(in_features, n_hidden, bias=bias)
self.linear2 = nn.Linear(n_hidden, out_features, bias=bias)
def forward(self, x):
z1 = self.linear1(x)
p1 = torch.sigmoid(z1)
out = self.linear2(p1)
return out
# 创建随机数种子
torch.manual_seed(420)
# 创建模型
sigmoid_test = Sigmoid_class1_test()
# 观察各层参数
list(sigmoid_test.parameters())
#[Parameter containing:
# tensor([[ 0.4318, -0.4256],
# [ 0.6730, -0.5617]], requires_grad=True),
# Parameter containing:
# tensor([[-0.2157, -0.4873]], requires_grad=True)]
# 将各层参数修改为0
list(sigmoid_test.parameters())[0].data = torch.tensor([[0., 0], [0, 0]])
list(sigmoid_test.parameters())[1].data = torch.tensor([[0., 0]])
# 查看修改结果
list(sigmoid_test.parameters())
#[Parameter containing:
# tensor([[0., 0.],
# [0., 0.]], requires_grad=True),
# Parameter containing:
# tensor([[0., 0.]], requires_grad=True)]
或者也可以通过torch.full_like(list(sigmoid_test.parameters())[0], 0)进行修改,然后再令其可导并替换原始参数值。
# 遍历五次查看结果
fit(net = sigmoid_test,
criterion = nn.MSELoss(),
optimizer = optim.SGD(sigmoid_test.parameters(), lr = 0.03),
batchdata = train_loader,
epochs=5,
cla=False)
list(sigmoid_test.parameters())
#[Parameter containing:
# tensor([[ 0.5914, -0.0281],
# [ 0.5914, -0.0281]], requires_grad=True),
# Parameter containing:
# tensor([[1.0375, 1.0375]], requires_grad=True)]
我们发现每一列参数(最后一个参数所在的行)都是同步变化的。大家可以想想这是什么原因~?
很明显,我们不能将参数的初始值全部设为0,我们只能考虑借助统计工具生成均值是0的随机数,也就是0均值的均匀分布或者是0均值的高斯分布,但这里需要考虑的另一个问题就是,该随机数的方差应该如何确定?
2.Glorot条件和Xavier方法
初始化参数的方差如何确定这一问题在一个严谨论述如何保证模型有效性的论文中,从另一个角度出发,得到了回答。根据Xavier Glorot在2010年发表的《Understanding the difficulty of training deep feedforward neural networks》论文中的观点,为保证模型本身的有效性和稳定性,我们希望正向传播时,每个线性层输入数据的方差等于输出数据的方差,同时我们也希望反向传播时,数据流经某层之前和流经某层之后该层的梯度也具有相同的方差,虽然二者很难同时满足(除非相邻两层神经元个数相同),但Glorot和Bengio(论文第二作者)表示,如果我们适当修改计算过程、是可以找到一种折中方案去设计初始参数取值,从而同时保证二者条件尽可能得到满足,这种设计参数初始值的方法也被称为Xavier方法,而这种方法也经过一段时间的实践验证被证明是很好的一种初始化模型参数的方法,尤其是对于使用tanh激活函数的神经网络来说,效果更为显著。
而这种正向传播时数据方差保持一致、反向传播时参数梯度方差保持一致的条件,也被称为Glorot条件,满足该条件的模型能够进行有效平稳的训练,而为了满足该条件而创建的(当然也是由上述论文提出的)模型初始化参数值设计方法,也被称为Xavier方法。而在Xavier方法中,最核心解决的问题,也就是为了创建Zero-Centered的初始化参数时参数的方差。和我们从朴素的角度思考的方向是一致的。
由于Glorot条件和Xavier方法是在2010年提出的,彼时ReLU激活函数还未兴起,因此Xavier方法主要是围绕tanh激活函数可能存在的梯度爆炸或梯度消失进行的优化,Sigmoid激活函数效果次之。不过尽管如此,Glorot条件却是一个通用条件,后续围绕ReLU激活函数、用于解决神经元活性失效的优化方法(如HE初始化方法),也是遵照Glorot条件进行的方法设计。
3.模型初始化参数取值影响
Xavier初始化方法的推导和使用我们将在下一节详细介绍,此处我们先通过另外一个实例,去展示为何初始参数取值不同,会够得到不同的建模结果。模型初始化时得到的不同参数,本质上等价于在损失函数上找到了不同的初始点,而同一损失函数,初始点选取的不同应该不会影响最终迭代结果才对,但事实情况并非如此。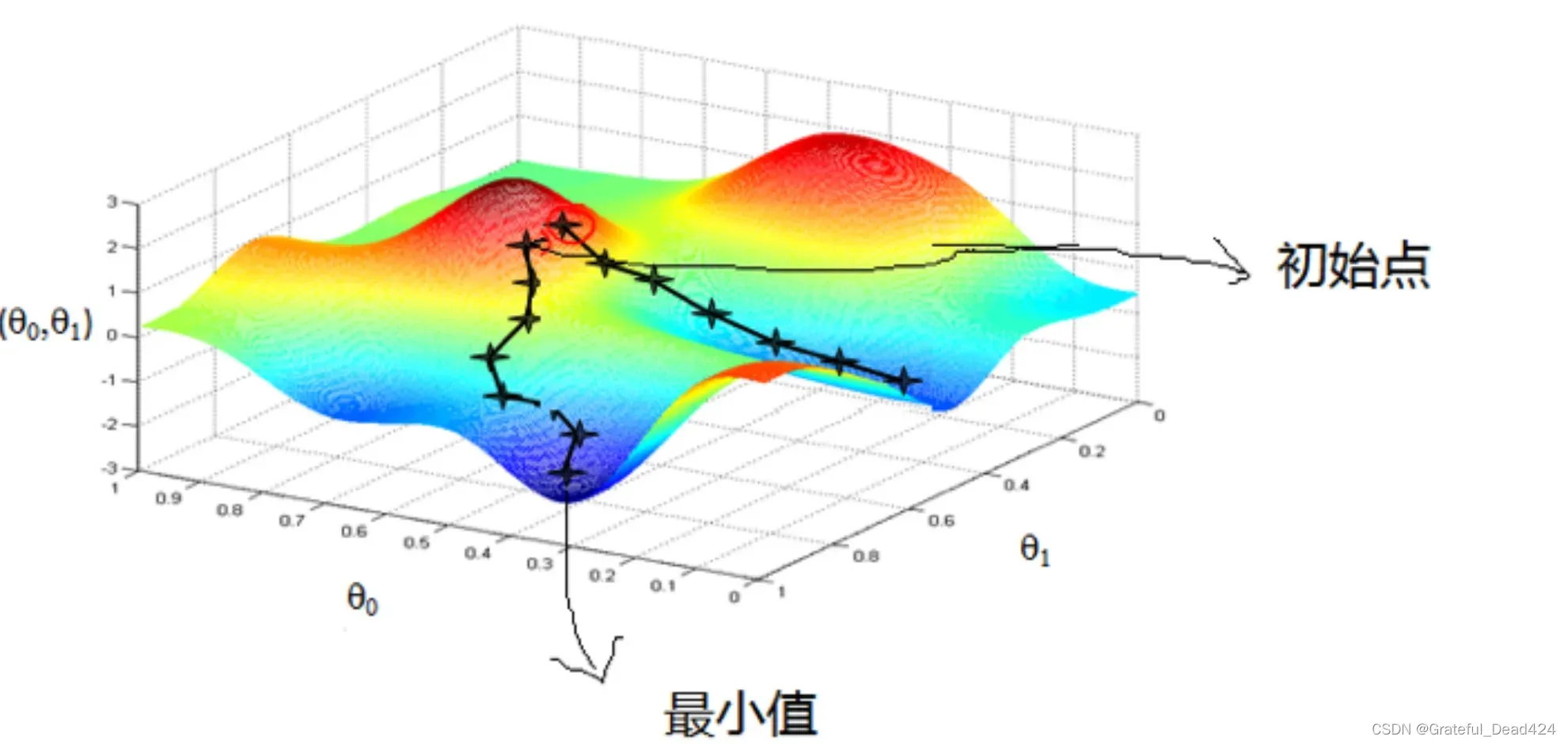
接下来,我们通过一个实验来说明初始值的替换对模型结果的影响。在模型实例化过程中,使用不同的随机数种子相当于选择了不同的模型初始参数。
# 创建随机数种子
torch.manual_seed(420)
# 实例化模型
relu_model3 = ReLU_class3(bias=False)
# 核心参数
num_epochs = 20
lr = 0.03
# 模型训练
train_l, test_l = model_train_test(relu_model3,
train_loader,
test_loader,
num_epochs = num_epochs,
criterion = nn.MSELoss(),
optimizer = optim.SGD,
lr = 0.03,
cla = False,
eva = mse_cal)
# 绘制图像,查看MSE变化情况
plt.plot(list(range(num_epochs)), train_l, label='train_mse')
plt.plot(list(range(num_epochs)), test_l, label='test_mse')
plt.legend(loc = 4)
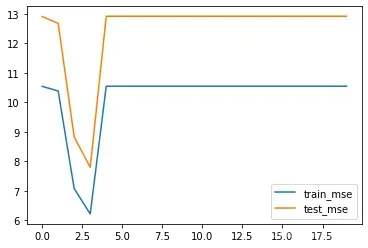
# 创建随机数种子
torch.manual_seed(29)
# 实例化模型
relu_model3 = ReLU_class3(bias=False)
# 核心参数
num_epochs = 20
lr = 0.03
# 模型训练
train_l, test_l = model_train_test(relu_model3,
train_loader,
test_loader,
num_epochs = num_epochs,
criterion = nn.MSELoss(),
optimizer = optim.SGD,
lr = 0.03,
cla = False,
eva = mse_cal)
# 绘制图像,查看MSE变化情况
plt.plot(list(range(num_epochs)), train_l, label='train_mse')
plt.plot(list(range(num_epochs)), test_l, label='test_mse')
plt.legend(loc = 4)
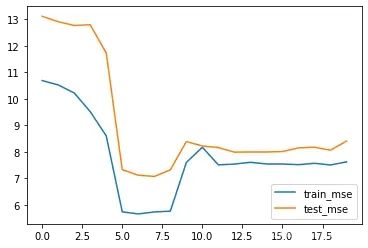
我们发现,初始参数值的选取不仅会影响模型收敛速度,甚至在某些情况下还会影响模型的最终表现。造成此现象的根本原因还是在于神经网络模型在进行训练时,不确定性过多,而在一个拥有诸多不确定性的系统中再加上不确定的初始参数,初始参数的不确定性会被这个系统放大。并且,值得一提的是,每一个epoch中的每一次迭代并不是在一个损失函数上一步步下降的,当我们使用小批量梯度下降算法时,带入不同批的数据,实际创建的损失函数也会不同。
版权声明:本文为博主Grateful_Dead424原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/Grateful_Dead424/article/details/123235167