距离上次的文章,已经有一个月之久了。要是再不继续推进,那么我17个粉丝又要催更了(纯属本人瞎说,实际情况是没人催更)。
今天就别吵了,直接上路吧!
上次的文章中,说明了如何在C++代码中解析我们的专AI模模型文件格式,大概的思路无非和构建模型的时候是反着进行的。因为这份模型文件格式是完全由flatbuffers进行解析的,因此,解析的过程是一场清晰明了的。
而之所以解析模型文件,主要是这样我们就能够实现专AI模的跨平台传送,构建好的模型能够无差异地在各个设备上使用,这正是flatbuffers作为数据交换协议的功劳。另外一个比较重要的原因是我们只有解析模型后,知道了所有的网络层、有向图中数据流的走向,才能够进行运行时(就是实际部署后的模型代码构成)推理接口的搭建。
既然模型解析部分已经完成,那么我们可以如何处理数据背后的变量数据呢?或者如何将模型部署到对应的设备上?这是我们“推理部署”的核心部分。
推理部署理念:通过各种方式将深度学习训练好的模型部署到相应的设备上,实现模型的实际应用,并期望部署后达到最快的速度和最好的准确率。如果你没有接触过深度学习模型部署,你可能会觉得一时难以理解,但是例如:非传统的人脸解锁、非传统的指纹解锁……这些是使用最广泛的推理部署示例.
一、推理与部署的思路
如果之前了解过推理部署框架,对于诸如TVM、NCNN、TNN、MNN等等或许会有所了解。这些框架大多都遵循以下所示的系统框架构建模式,这也是一般的推理框架的主要思路。
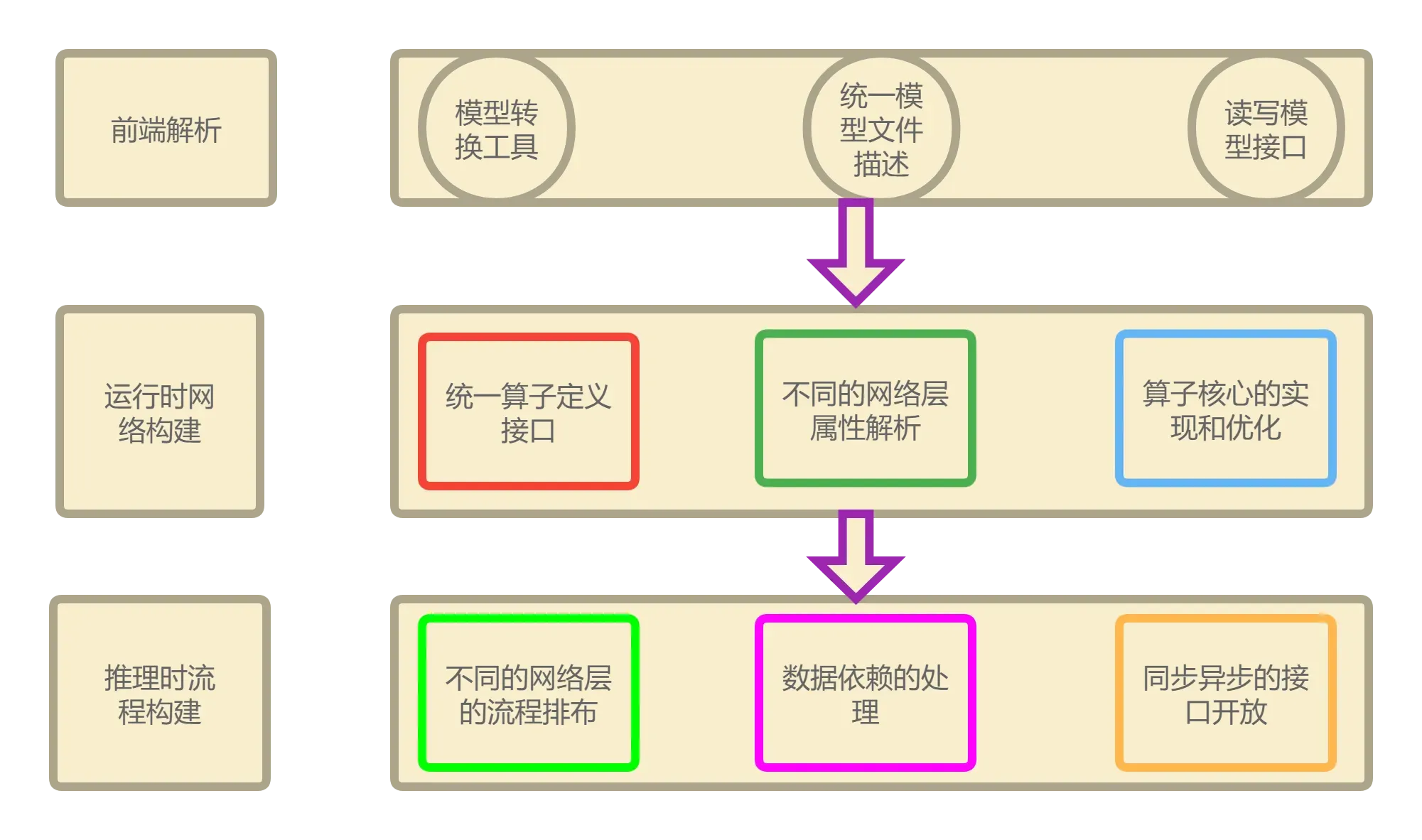
《推理部署》系列文章的主要目的是实现以上三个方面的模块。以上前端分析已经完成。本文主要针对运行时网络搭建和推理过程搭建。
2. 运行时网络建设
目的:从前端解析出来的模型的所有信息,我们需要利用这些信息来生成各个网络层的运行时核,优化这些核,最后持久化这些优化的核算子。这样就可以重复调用对应的核心算子,无需后续推理的开销,从而达到加速的目的。
// 通过PzkM来创建一个OCL后端运行时
bool CreateNetWork(PzkM model){
// 1.首先构建所有的Tensor
for(size_t i = 0; i < model.rTensors.size(); i++){
if(CreateClMem(&model.rTensors[i]) == false){
printf("create clmem faided in id = %d\n", model.rTensors[i].id);
return false;
}
}
// 2.设置Tensor作为输入
std::vector<struct TensorsS*> inputs;
for(size_t i = 0; i < model.model_runtime_input_id.size(); i++){
for(size_t j = 0; j < model.rTensors.size(); j++){
if (model.rTensors[j].id == model.model_runtime_input_id[i]){
inputs.push_back(&(model.rTensors[j]));
}
}
}
SetAsInputs(inputs);
for(size_t i = 0; i < inputs.size(); i++){
input_tensors[inputs[i]->id] = *inputs[i];
}
// 3.进行网络层的运行时构建
if(BuildLayers(model) == false){
printf("failed build runtime layers\n");
}
// 4.设置Tensor作为输出
std::vector<struct TensorsS*> outputs;
for(size_t i = 0; i < model.model_runtime_output_id.size(); i++){
for(size_t j = 0; j < model.rTensors.size(); j++){
if (model.rTensors[j].id == model.model_runtime_output_id[i]){
outputs.push_back(&(model.rTensors[j]));
}
}
}
SetAsOutputs(outputs);
for(size_t i = 0; i < outputs.size(); i++){
output_tensors[outputs[i]->id] = *outputs[i];
}
return true;
}上述的代码通过注释的方式来说了如何把一个PzkM(这是前端解析好的包含了模型信息的类实例)构建其运行时网络。而其中最为重要的是3.进行网络层的运行时构建,下面的代码展示了BuildLayers()函数的主要代码(目前只写了两种类型的网络层的核心代码,分别是img2col和conv2d):
// 构建运行时的网络层
bool BuildLayers(PzkM model){
for (size_t i = 0; i < model.rLayers.size(); i++){
// 进行各种不同类型的选择
layer_maker onelayer = model.rLayers[i];
if (onelayer.type == "img2col"){
add_img2col_layer(onelayer);
}else if (onelayer.type == "conv2d"){
add_conv2d_layer(onelayer);
}
else{
printf("unknown type = %s layer, cant't finish it\n", onelayer.type.c_str());
return false;
}
}
return true;
}上述的BuildLayers中,我们可以知道网络层的主要思想就是:在排布好网络层的顺序之后,按照不同的网络层实行不同的构建函数,依次构建出整个网络。
3. 在推理时构建
目的:在执行运行时构建的网络层的核心功能时,我们需要处理它们之间的依赖关系;另外,我们需要做好同步和异步接口的封装。
原因:很多推理和部署平台都与硬件密切相关,尤其是内核主要用低级编程语言编写的超快平台;更通用的平台更异构(多处理器,异步操作)。我们需要对并行编程和同步机制有非常深入的了解,才能为这一步构建框架。
特别的,我们这次使用到了OpenCL并行编程语言来作为加速手段(PS:其实在上述的算子核心编写的时候就是用OpenCL来构建的,特别是采用了OpenCL的核心运行时编译优化手段)。在推理时借助OpenCL主要完成了核心命令队列的数据依赖、同步异步的接口实现。
// 进行推理的接口
bool Inference(){
// 首先input:cpu->device
for(size_t i = 0; i < input_tensors.size(); i++){
if(WriteCLMem(&input_tensors[i], cpu_mem[input_tensors[i].id]) == false){
printf("write CLmem in inference, which id = %d\n", input_tensors[i].id);
return false;
}
}
// 然后进行推理
for(size_t i = 0; i < AllLayers.size(); i++){
AllLayers[i]->run();
}
// 最后ouput:device->cpu
for(size_t i = 0; i < output_tensors.size(); i++){
if(ReadCLMem(&output_tensors[i], cpu_mem[output_tensors[i].id]) == false){
printf("read CLmem in inference, which id = %d\n", output_tensors[i].id);
return false;
}
}
return true;
}上述的Inference接口说明了推理的一般流程:把数据从cpu内存送入到异构设备;往命令推理队列中不断地下发推理指令;最后把推理结果从异构设备传到cpu内存上。
那么我们如何实现了数据依赖、以及同步异步的接口呢?答案在OpenCL的命令队列中:
// opencl推理引擎的命令空间
// 想要通过效仿acl-opencl的推理流程来构建自己的推理引擎
/*
1、希望opencl平台的设备管理等方面由命令空间管理
2、提供了对CLmem的操作手段,包括创建、读写等
3、提供了CLKernel排对进入命令队列的操作、以及对CLKernel的管理
4、命令队列查询、以及等待操作等
*/
namespace OCLEngine {
/*---------------------------------为了能够进行事件同步而设置前向链表结构--------------------------*/
struct wait_event{
cl_uint num = 0;
cl_event* event = NULL;
wait_event* next = NULL;
};
// 事件同步产生的变量
wait_event* wehead = NULL; // 链表头
wait_event* wenow = NULL; // 目前的链表
wait_event* weend = NULL; // 链表尾
std::unordered_map<uint32_t, cl_event*> event_of_tensor;
// 添加节点
void add_wait_event_node(cl_uint event_num){
if(wehead == NULL){
wehead = (wait_event*)malloc(sizeof(wait_event));
wehead->num = event_num;
wehead->event = (cl_event*)malloc(sizeof(cl_event) * wehead->num);
weend = wehead;
}
else{
weend->next = (wait_event*)malloc(sizeof(wait_event));
weend = weend->next;
weend->num = event_num;
weend->event = (cl_event*)malloc(sizeof(cl_event) * wehead->num);
}
}
// 清除事件同步链表
void CleanEvent(){
wait_event* ptr = wehead;
while(ptr != NULL){
struct wait_event* ptr1 = ptr->next;
if(ptr->event != NULL && ptr->num > 0){
for(size_t i = 0; i < ptr->num; i++){
clReleaseEvent(*(ptr->event + i));
}
free(ptr->event);
}
free(ptr);
ptr = ptr1;
}
return;
}
// 只是单纯释放
void ReleaseEvent(){
struct wait_event* ptr = wehead;
while(ptr != NULL){
struct wait_event* ptr1 = ptr->next;
if(ptr->event != NULL && ptr->num > 0){
for(size_t i = 0; i < ptr->num; i++){
clReleaseEvent(*(ptr->event + i));
*(ptr->event + i) = NULL;
}
}
ptr = ptr1;
}
return;
}
/*---------------------------------------------opencl基本变量------------------------------------*/
// opencl平台持久化变量
cl_context context = 0;
cl_command_queue commandQueue = 0;
// cl_program program = 0;
cl_device_id device = 0;
// cl_kernel kernel = 0;
std::unordered_map<uint32_t, cl_mem> clmem;
cl_int errNum;
/*后续代码没有放出来*/
}是的,这里的想法是将每个网络层绑定到一个事件。网络层运行成功后,该事件将被标记为成功;而网络层核心计算的开始需要将上一层的事件标记为 成功后才能开始操作。这样,就可以形成一个顺序的操作链。
如此,我们针对那个专AI模的来开发的推理引擎的大体框架就完成了。后续的任务就是算子的具体优化和开发,也就是所谓的算子开发了。
版权声明:本文为博主慷仔原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/Pengcode/article/details/123299302