



学习目标:
1.掌握数据结构分析、索引操作和高级索引
二、掌握算术运算和数据对齐、数据排序
三、掌握统计计算和描述,分层索引
四、掌握读写数据的操作
学习内容:
1.Pandas的数据结构分析
Series:类似一维数组的对象,它能够保存任何类型的数据,主要由一组数据和与之相关的索引两部分构成。
构造函数创建:
class pandas.Series(data = None,index = None,dtype = None, name = None,copy = False,fastpath = False)
# 创建Series类对象
ser_obj = pd.Series([1, 2, 3, 4, 5])
# 创建Series类对象,并指定索引
ser_obj = pd.Series([1, 2, 3, 4, 5], index=['a', 'b', 'c', 'd', 'e'])
#使用dict进行构建
year_data = {2001: 17.8, 2002: 20.1, 2003: 16.5} ser_obj2 = pd.Series(year_data)
# 获取ser_obj的索引
ser_obj.index
# 获取ser_obj的数据
ser_obj.values
# 获取位置索引3对应的数据
ser_obj[3]DataFrame:是一个类似于二维数组或表格(如excel)的对象,它每列的数据可以是不同的数据类型。
注:DataFrame的索引不仅有行索引,还有列索引,数据可以有多列。
构造函数创建:
pandas.DataFrame(data = None,index = None,columns = None, dtype = None,copy = False )
# 创建数组
demo_arr = np.array([['a', 'b', 'c'],
['d', 'e', 'f']])
# 基于数组创建DataFrame对象
df_obj = pd.DataFrame(demo_arr)
#按照指定索引的顺序进行排列
df_obj = pd.DataFrame(demo_arr, columns=['No1', 'No2', 'No3'])
# 通过列索引的方式获取一列数据
element = df_obj['No2']
# 查看返回结果的类型
type(element)
# 通过属性获取列数据
element = df_obj.No2
# 查看返回结果的类型
type(element)
# 增加No4一列数据
df_obj['No4'] = ['g', 'h']
# 删除No3一列数据
del df_obj['No3']2.Pandas索引操作及高级索引
Pandas中的索引都是Index类对象,又称为索引对象,该对象是不可以进行修改的,以保障数据的安全。
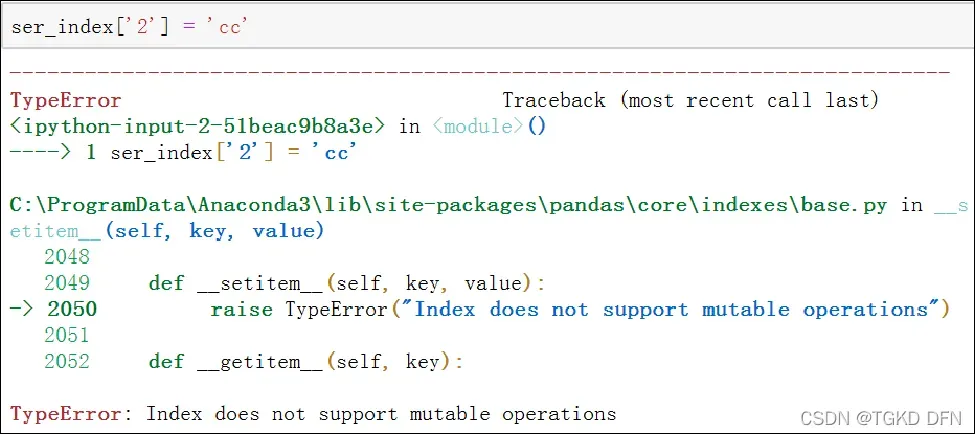
Pandas还提供了很多Index的子类,常见的有如下几种:
(1)Int64Index:针对整数的特殊Index对象。
(2)MultiIndex:层次化索引,表示单个轴上的多层索引。
(3)DatetimeIndex:存储纳秒寄时间戳。
reindex()作用是对原索引和新索引进行匹配,也就是说,新索引含有原索引的数据,而原索引数据按照新索引排序。
注:如果新索引中没有原索引数据,那么程序不仅不会报错,而且会添加新的索引,并将值填充为NaN或者使用fill_vlues()填充其他值。
reindex()方法的语法格式如下:
#index:用作索引的新序列。
#method:插值填充方式。
#fill_value:引入缺失值时使用的替代值。
#limit:前向或者后向填充时的最大填充量。
DataFrame.reindex(labels = None,index = None,
columns = None,axis = None,method = None,
copy = True,level = None,fill_value = nan,limit = None,tolerance = None )
#使用fill_value参数来指定缺失值
ser_obj.reindex(['a', 'b', 'c', 'd', 'e', 'f'],
fill_value = 6)
如果期望使用相邻的元素值进行填充,则可以使用method参数,该参数对应的值有多个。


Series有关索引的用法类似于NumPy数组的索引,只不过Series的索引值不只是整数。如果我们希望获取某个数据,既可以通过索引的位置来获取,也可以使用索引名称来获取。
ser_obj = pd.Series([1, 2, 3, 4, 5], index=['a', 'b', 'c', 'd', 'e'])
ser_obj[2] # 使用索引位置获取数据
ser_obj['c'] # 使用索引名称获取数据
ser_obj[2: 4] # 使用位置索引进行切片
ser_obj['c': 'e'] # 使用索引名称进行切片
# 通过不连续位置索引获取数据集
ser_obj[[0, 2, 4]]
# 通过不连续索引名称获取数据集
ser_obj[['a', 'c', 'd']]
# 创建布尔型Series对象
ser_bool = ser_obj > 2
# 获取结果为True的数据
ser_obj[ser_bool]虽然DataFrame操作索引能够满足基本数据查看请求,但是仍然不够灵活。为此,Pandas库中提供了操作索引的方法来访问数据,具体包括:
loc:基于标签索引(索引名称),用于按标签选取数据。当执行切片操作时,既包含起始索引,也包含结束索引。
iloc:基于位置索引(整数索引),用于按位置选取数据。当执行切片操作时,只包含起始索引,不包含结束索引。
3.算术运算与数据对齐
Pandas执行算术运算时,会先按照索引进行对齐,对齐以后再进行相应的运算,没有对齐的位置会用NaN进行补齐。
如果希望不使用NAN填充缺失数据,则可以在调用add方法时提供fill_value参数的值,fill_value将会使用对象中存在的数据进行补充。
# 执行加法运算,补充缺失值
obj_one.add(obj_two, fill_value = 0)4.数据排序
Pandas中按索引排序使用的是sort_index()方法,该方法可以用行索引或者列索引进行排序。
#axis:轴索引,0表示index(按行),1表示columns(按列)。
#level:若不为None,则对指定索引级别的值进行排序。
#ascending:是否升序排列,默认为True表示升序。
sort_index(axis = 0,level = None,ascending = True,inplace = False,kind =' quicksort ',na_position ='last',sort_remaining = True )
#按索引对Series进行分别排序
ser_obj = pd.Series(range(10, 15), index=[5, 3, 1, 3, 2])
# 按索引进行升序排列
ser_obj.sort_index()
# 按索引进行降序排列
ser_obj.sort_index(ascending = False)
#按索引对DataFrame进行分别排序
df_obj = pd.DataFrame(np.arange(9).reshape(3, 3),
index=[4, 3, 5])
# 按行索引升序排列
df_obj.sort_index()
# 按行索引降序排列
df_obj.sort_index(ascending=False)Pandas中用来按值排序的方法为sort_values(),该方法的语法格式如下。
sort_values(by,axis=0, ascending=True, inplace=False, kind='quicksort',na_position='last')
#by参数表示排序的列,na_position参数只有两个值:first和last,若设为first,则会将NaN值放在开头;若设为False,则会将NaN值放在最后。
#按值的大小对Series进行排序
ser_obj = pd.Series([4, np.nan, 6, np.nan, -3, 2])
# 按值升序排列
ser_obj.sort_values()
#sort_values()方法可以根据一个或多个列中的值进行排序
df_obj = pd.DataFrame([[0.4, -0.1, -0.3, 0.0],
[0.2, 0.6, -0.1, -0.7],
[0.8, 0.6, -0.5, 0.1]])
# 对列索引值为2的数据进行排序
df_obj.sort_values(by=2)5.统计计算与描述
Pandas为我们提供了非常多的描述性统计分析的指标方法,比如总和、均值、最小值、最大值等。
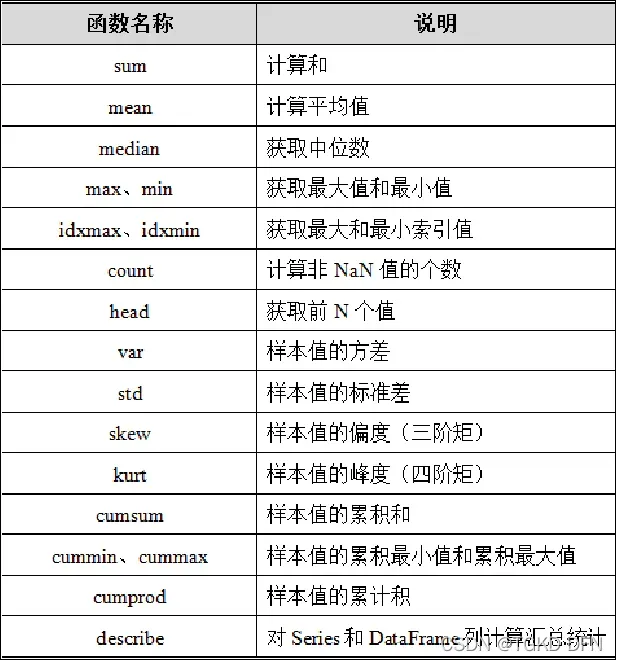

如果希望一次性输出多个统计指标,则我们可以调用describe()方法实现,语法格式如下。
describe(percentiles=None, include=None, exclude=None)
#percentiles:输出中包含的百分数,位于[0,1]之间。如果不设置该参数,则默认为[0.25,0.5,0.75],返回25%,50%,75%分位数6. 层次化索引
定义:层次索引可以理解为单级索引的扩展,即一个轴方向的多级索引。
对于两级索引结构,可以分为内索引和外索引。
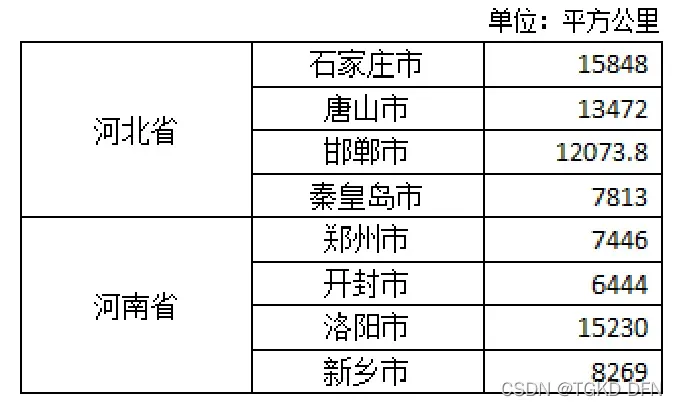

Series和DataFrame均可以实现层次化索引,最常见的方式是在构造方法的index参数中传入一个嵌套列表。
mulitindex_series = pd.Series([15848,13472,12073.8,7813,
7446,6444,15230,8269],
index=[['河北省','河北省','河北省','河北省',
'河南省','河南省','河南省','河南省'],
['石家庄市','唐山市','邯郸市','秦皇岛市',
'郑州市','开封市','洛阳市','新乡市']])注:在创建层次化索引对象时,嵌套函数中两个列表的长度必须是保持一致的,否则将会出现ValueError错误。
还可以通过MultiIndex类的方法构建一个层次化索引,该类提供了3种创建层次化索引的方法:
MultiIndex.from_tuples():将元组列表转换为MultiIndex。
MultiIndex.from_arrays():将数组列表转换为MultiIndex。
MultiIndex.from_product():从多个集合的笛卡尔乘积中创建一个MultiIndex。
from_tuples()方法可以将包含若干个元组的列表转换为MultiIndex对象,其中元组的第一个元素作为外层索引,元组的第二个元素作为内层索引
list_tuples = [('A','A1'), ('A','A2'), ('B','B1'),('B','B2'), ('B','B3')]
# 根据元组列表创建一个MultiIndex对象
multi_index = MultiIndex.from_tuples(tuples=list_tuples,
names=[ '外层索引', '内层索引'])from_arrays()方法是将数组列表转换为MultiIndex对象,其中嵌套的第一个列表将作为外层索引,嵌套的第二个列表将作为内层索引。
multi_array = MultiIndex.from_arrays(arrays =[['A', 'B', 'A', 'B', 'B'],
['A1', 'A2', 'B1', 'B2', 'B3']],
names=['外层索引','内层索引'])from_product()方法表示从多个集合的笛卡尔乘积中创建一个MultiIndex对象
numbers = [0, 1, 2]
colors = ['green', 'purple']
multi_product = pd.MultiIndex.from_product(iterables=[numbers, colors],
names=['number', 'color'])在Pandas中,交换分层顺序的操作可以使用swaplevel()方法来完成。
# 交换外层索引与内层索引位置
ser_obj.swaplevel()要想按照分层索引对数据排序,则可以通过sort_index()方法实现。
sort_index(axis = 0,level = None,ascending = True,inplace = False,kind =' quicksort ',na_position ='last',
sort_remaining = True,by = None )7. 读写数据操作
to_csv()方法的功能是将数据写入到CSV文件中
to_csv(path_or_buf=None,sep=',',na_rep='',float_format=None,columns=None,header=True, index=True, index_label=None, mode='w‘, ...)read_csv()函数的作用是将CSV文件的数据读取出来,转换成DataFrame对象展示。
read_csv(filepath_or_buffer,sep=',', delimiter=None, header='infer', names=None, index_col=None, usecols=None, prefix=None, ...)注:read_csv()与read_table()函数的区别在于使用的分隔符不同,前者使用“,”作为分隔符,而后者使用“\t”作为分隔符。
to_excel()方法的功能是将DataFrame对象写入到Excel工作表中。
to_excel(excel_writer,sheet_name='Sheet1',na_rep='',
float_format=None, columns=None, header=True, index=True, ...)read_excel()函数的作用是将Excel中的数据读取出来,转换成DataFrame展示。
pandas.read_excel(io,sheet_name=0,header=0,names=None,index_col=None, **kwds)对于网页中的表格,可以使用read_html()函数进行读取,并返回一个包含多个DataFrame对象的列表。
pandas.read_html(io, match='.+', flavor=None,header=None, index_col=None,skiprows=None, attrs=None)Pandas的io.sql模块中提供了常用的读写数据库函数。
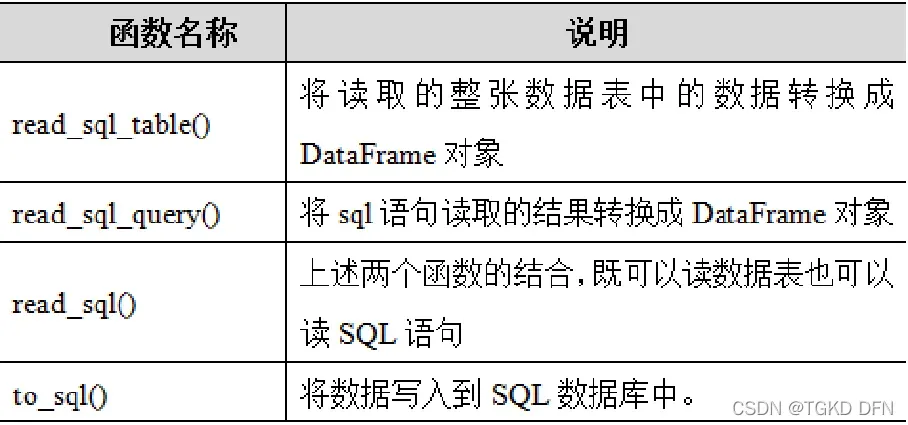

注:在连接mysql数据库时,这里使用的是mysqlconnector驱动,如果当前的Python环境中没有改模块,则需要使用pip install mysqlconnector命令安装该模块。
read_sql()函数既可以读取整张数据表,又可以执行SQL语句。
pandas.read_sql(sql,con,index_col=None,coerce_float=True,params=None,parse_dates=None, columns=None, chunksize=None)
注:通过create_engine()函数创建连接时,需要指定格式如下:’数据库类型+数据库驱动名称://用户名:密码@机器地址:端口号/数据库名’。
to_sql()方法的功能是将Series或DataFrame对象以数据表的形式写入到数据库中。
to_sql(name,con,schema = None,if_exists ='fail',index = True,index_label = None,chunksize = None,dtype = None )
版权声明:本文为博主TGKD DFN原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_59336423/article/details/123296635