一.前言
最近在朋友的介绍下,了解了一个神经网络的调参神器——微软开发的NNI (Neural Network Intelligence),在经过简单尝试之后,发现是真的香。倘若你也苦于每次炼丹都要手动设置超级参数,那你可以选择尝试一下NNI,从此告别繁杂重复的调参参数手动设置。话不多说,直接上干货。
二.NNI怎样帮助调参的?
对于人工智能从业者来说,炼金术可谓是一种看家本领,但炼金术通常是一件非常痛苦的事情。一般来说,我们使用的模型都有很多超参数,那么什么样的超参数组合才能让模型发挥最佳效果呢?我们经常需要做很多尝试,为不同的参数设置不同的值进行组合,对每个组合进行一个实验,然后再设置另一组参数进行实验,如此反复,直到找到理想的一组参数.
那么,我们可以直接一次设置多组参数,然后让程序自动完成一组,然后继续运行下一组吗?
当然可以,直接写个脚本也能做到。或者尝试使用NNI,通过NNI我们可以设置好超级参数的搜索空间,然后使用其实现的超级参数调优算法去探索一组理想的超参。此外,它还提供了可视化的WEB界面,能够让我们实时观测程序的运行状态和搜索空间的搜索状态等等。
2.1 NNI调参的工作流程
那么,NNI是怎样做到帮我们自动的探索超参的搜索空间呢,其工作流程大概如下:
Input: 搜索空间(search space), 实验代码(trial code), 配置文件(config file)
Output: 一组最优的超级参数(hyperparameter)配置
1: For t = 0, 1, 2, ..., maxTrialNum(配置文件设置的最大实验次数),
2: hyperparameter = chose a set of parameter from search space //从搜索空间选择对应的一组参数
3: final result = run_trial_and_evaluate(hyperparameter) //利用这组参数进行实验,并返回最终的结果
4: report final result to NNI //将本组超参的最终结果报告给NNI
5: If reach the upper limit time: // 达到了设置实验运行时间的上限,
6: Stop the experiment //停止实验
7: return hyperparameter value with best final result // 返回最佳的一组超级参数
了解了其工作流程以后,接下来,博主将代领大家利用NNI进行实践了。
三.NNI调参实践
3.1 NNI的安装
NNI支持如下主流的操作系统:
Ubuntu >= 16.04
macOS >= 10.14.1
Windows 10 >= 1809
它的安装命令如下:
# Linux或MacOS
python3 -m pip install --upgrade nni
# Windows
python -m pip install --upgrade nni
安装完成后,如果要验证是否安装成功,可以参考官方提供的示例:
git clone -b v2.6 https://github.com/Microsoft/nni.git
若git clone失败,可以直接把后面的链接贴到浏览器去手动下载。
然后,从官方网站运行示例:
# Linux或MacOS
nnictl create --config nni/examples/trials/mnist-pytorch/config.yml
# Windows
nnictl create --config nni\examples\trials\mnist-pytorch\config_windows.yml
即在–config后面加上trials目录下minst-pytorch目录下的相应配置文件即可。
若运行成功,可以看到命令行输出的Web UI URLs,选择本机IP:8080,即http://127.0.0.1:8080在浏览器打开就可看到Web界面。
3.2 实验代码说明
本次使用的实验代码是一个利用Resnet网络来对一个汽车分类数据集进行分类的Demo。因为只是尝试下NNI,在实验过程中只探索了最常用的三个超级参数:
batch size
epochs
learning rate
由于模型中的超参数需要更新,所以引入可变参数:
import argparse
def get_params():
parser = argparse.ArgumentParser()
parser.add_argument("--batch_size", type=int, default=32)
parser.add_argument("--epochs", type=int, default=50)
parser.add_argument("--lr", type=float, default=0.001)
parser.add_argument("--use_cuda", action='store_true', default=False)
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
args, _ = parser.parse_known_args()
return args
if __name__ == "__main__":
pass
其实也可以直接简单定义一个以超参变量名为键的字典(这里是因为笔者在已有代码上进行修改的缘故才如此)。由于使用NNI,因此只需要将NNI得到的参数名和参数值更新到args中,即:
tuner_params = nni.get_next_parameter()
params = vars(merge_parameter(get_params(), tuner_params))
上述代码中merge_parameter()方法可以将nni中的参数”添加“到args中去,然后通过vars()函数,可以使得我们在实验代码中像用字典一样取对应的超参,例如:
for epoch in range(args['epochs'])
根据2.1节,在使用NNI时,我们还需要向NNI报告当前结果以及报告最终结果,即:
nni.report_intermediate_result(test_acc)
nni.report_final_result(test_acc)
完成主程序的代码仅供参考:
import nni
import torch
import torch.nn as nn
import torch.utils.data as data
import torch.optim as optim
from data_loader import CarDataset
from model.resnet18 import Resnet18
from configuration import get_params
from nni.utils import merge_parameter
import logging
logger = logging.getLogger('resnet_AutoML')
def train(model,train_iter,loss_fn,optimizer,device):
"""
功能:训练模型
"""
model.train()
train_l_sum, train_acc_sum, n, c = 0,0,0,0
for x,y in train_iter:
x,y = x.float().to(device),y.to(device)
y_hat = model(x)
l = loss_fn(y_hat,y)
# 梯度清零
optimizer.zero_grad()
# 反向传播
l.backward()
# 更新参数
optimizer.step()
train_l_sum += l.item()
train_acc_sum += (y_hat.argmax(dim = 1) == y).sum().item()
n += y.shape[0]
c += 1
return train_acc_sum / n, train_l_sum / c
def evaluate_accuracy(model,test_iter,loss_fn,device):
"""
功能:在测试集上进行测评
"""
model.eval()
test_l_sum,test_acc_sum,n,c = 0.0,0,0,0
with torch.no_grad():
for x,y in test_iter:
x,y = x.float().to(device),y.to(device)
y_hat = model(x)
test_l_sum += loss_fn(y_hat,y)
test_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()
n += y.shape[0]
c += 1
return test_acc_sum / n, test_l_sum / c
def main(args):
# 是否启用GPU加速
use_cuda = args['use_cuda'] and torch.cuda.is_available()
torch.manual_seed(args['seed'])
# 定义GPU设备
device = torch.device("cuda:0" if use_cuda else "cpu")
# 加载数据
train_dataset = CarDataset(data_path="car3/train")
test_dataset = CarDataset(data_path="car3/test")
train_iter = data.DataLoader(
dataset=train_dataset,
batch_size=args['batch_size'],
shuffle=True,
num_workers=4
)
test_iter = data.DataLoader(
dataset=test_dataset,
batch_size=args['batch_size'],
shuffle=False,
num_workers=4
)
# 加载Resnet模型
model = Resnet18(class_num=3).to(device)
# 设定交叉熵作为损失函数
loss_fn = nn.CrossEntropyLoss()
# 选择Adam优化器
optimizer = optim.Adam(params=model.parameters(), lr=args['lr'])
for epoch in range(args['epochs']):
train_acc, train_loss = train(model, train_iter, loss_fn, optimizer, device)
test_acc, test_loss = evaluate_accuracy(model, test_iter, loss_fn, device)
print("Epoch {}: train_acc: {:.6} train_loss: {:.4} test_acc: {:.6} test_loss: {:.4}".format(
epoch, train_acc, train_loss, test_acc, test_loss))
nni.report_intermediate_result(test_acc)
logger.debug('test accuracy {:.4f}'.format(test_acc))
logger.debug('Pipe send intermediate result done.')
# 报告最终结果
nni.report_final_result(test_acc)
logger.debug('Final result is %g', test_acc)
logger.debug('Send final result done.')
if __name__ == "__main__":
try:
tuner_params = nni.get_next_parameter()
logger.debug(tuner_params)
params = vars(merge_parameter(get_params(), tuner_params))
# print(type(params))
main(params)
except Exception as exception:
logger.exception(exception)
raise
3.4 搜索空间配置
使用NNI时,我们需要创建一个搜索空间配置文件,可以为YAML文件或JSON文件,在其中我们可以设置我们使用的超级参数的取值,展示采用JSON格式定义的搜索空间:
{
"batch_size": {"_type":"choice", "_value": [16, 32, 64]},
"epochs":{"_type":"choice","_value":[20, 30]},
"lr":{"_type":"choice","_value":[0.0001, 0.001, 0.01]}
}
3.5 实验配置
除了搜索空间外,还可以指定实验的关键信息,例如实验文件、调参算法等,配置可以采用YAML文件,对应的示例如下:
experimentName: CIFAR10
searchSpaceFile: search_space.json # 指定搜索空间文件
trialCommand: python main.py --use_cuda # 实验运行shell命令
experimentWorkingDirectory: nni-experiments # NNI记录实验日志的目录
trialConcurrency: 1
tuner: # 指定调参算法
name: TPE
classArgs:
optimize_mode: maximize
trainingService: # 本地运行
platform: local
3.5 运行结果展示
进入命令行,切换到实验代码所在目录,输入如下命令:
nnictl create --config exp_config.yaml
可以看到命令行的输出如下:
在浏览器输入localhost:8080便可以看到如下主界面:
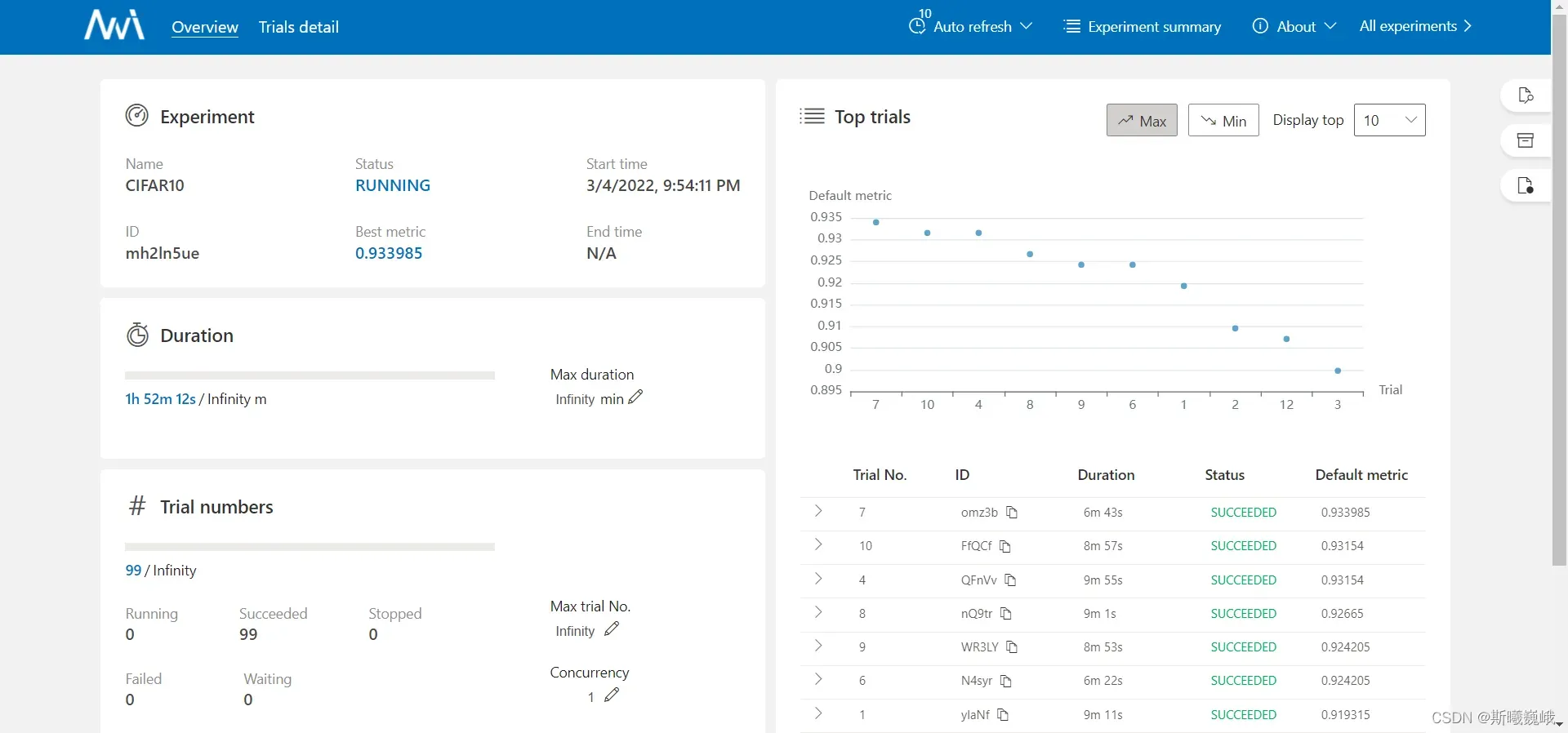
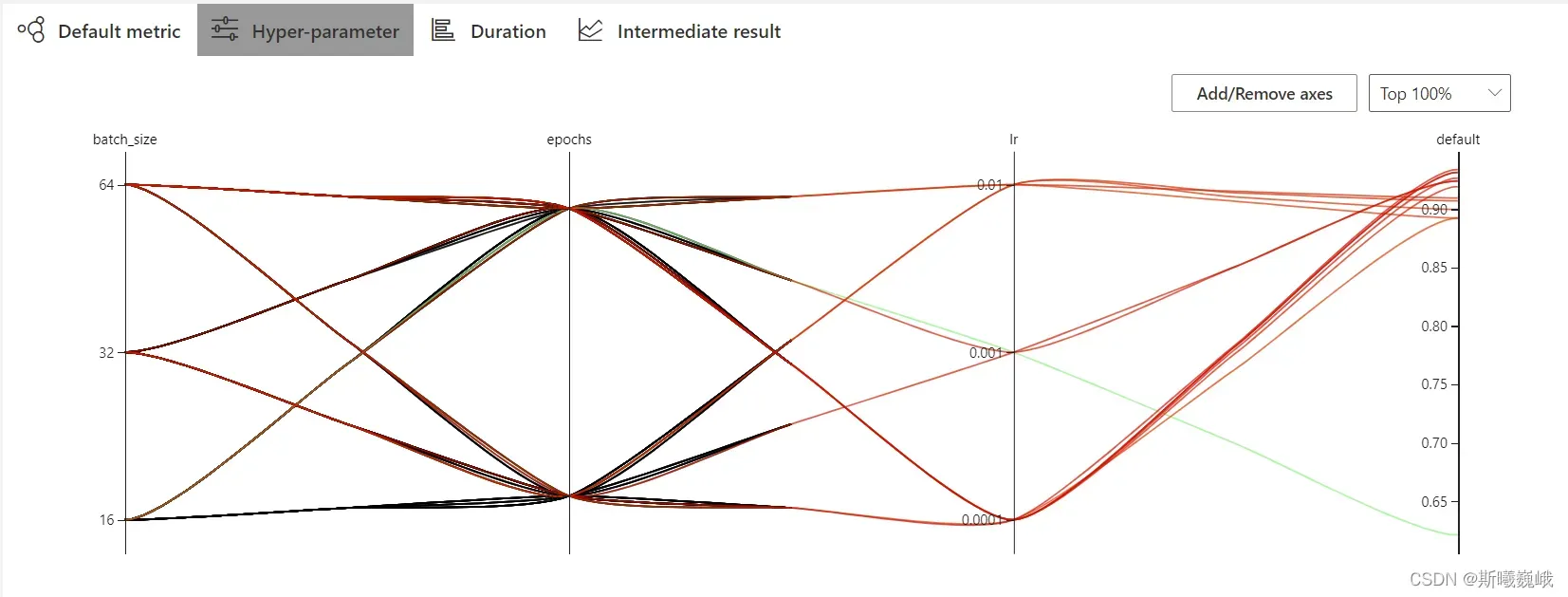
点击Trials detail即可看到具体的实验细节,包括有实验参数的超参组别:
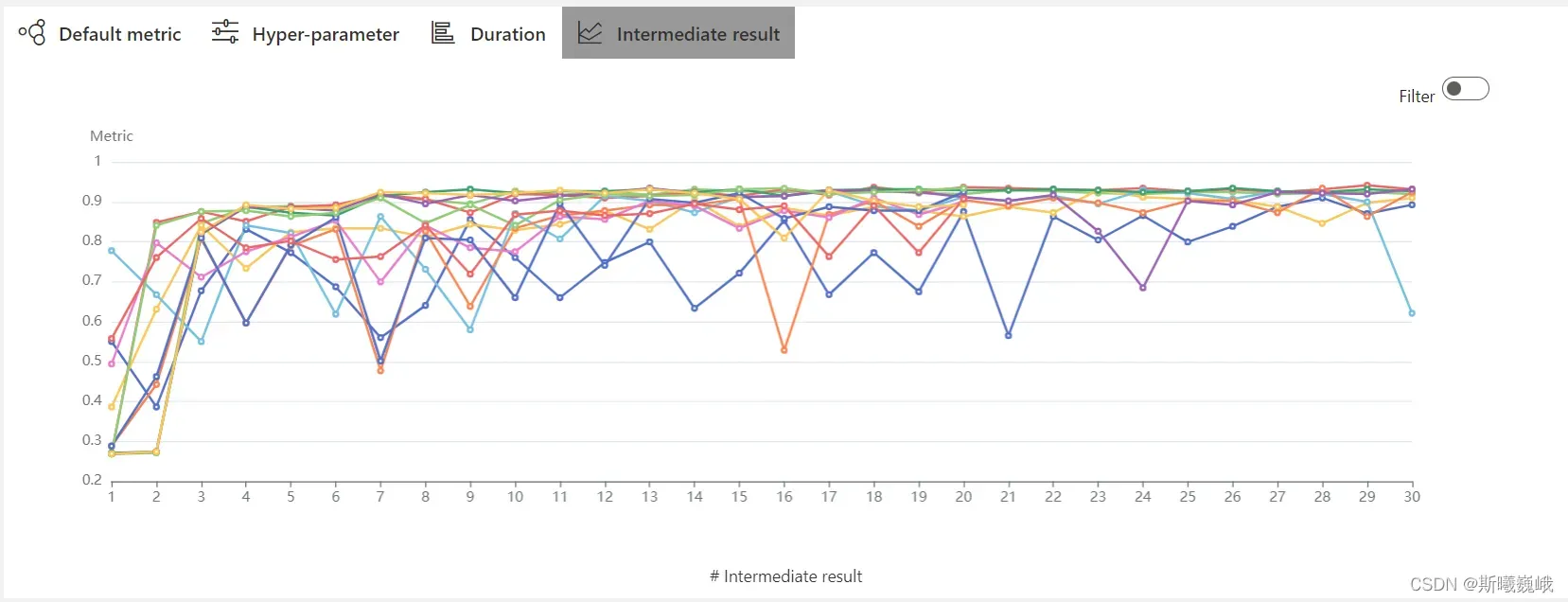
以及每个实验报告的中间结果(这里是测试集上的准确率):
四.结语
本文只是NNI调参的入门,具体细节请参见如下资源:
- NNI 微软官方Github地址
- NNI使用官方教程
项目的完整源码地址:NNI自动调参示例程序(有条件的支持一下)
以上就是本文的全部内容。如果觉得不错,可以点个赞或者关注博主。以后还会继续带来各种干货。当然,如果您有任何问题,请批评和指正! ! !
版权声明:本文为博主斯曦巍峨原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_42103091/article/details/123287865