一、原理
1.定义
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
来源:KNN算法最早是由Cover和Hart提出的一种分类算法
2. 距离公式
两个样本之间的距离可以通过以下公式计算,也称为欧几里得距离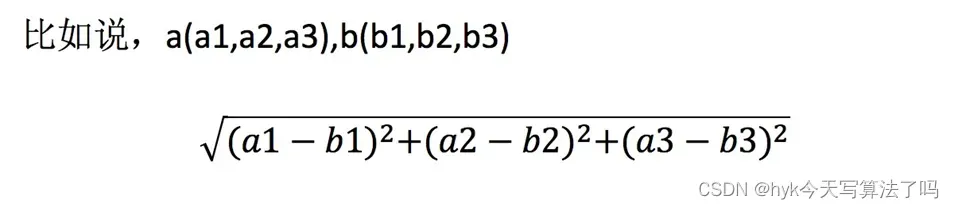
3.举例分析
电影类型分析假设我们有几部电影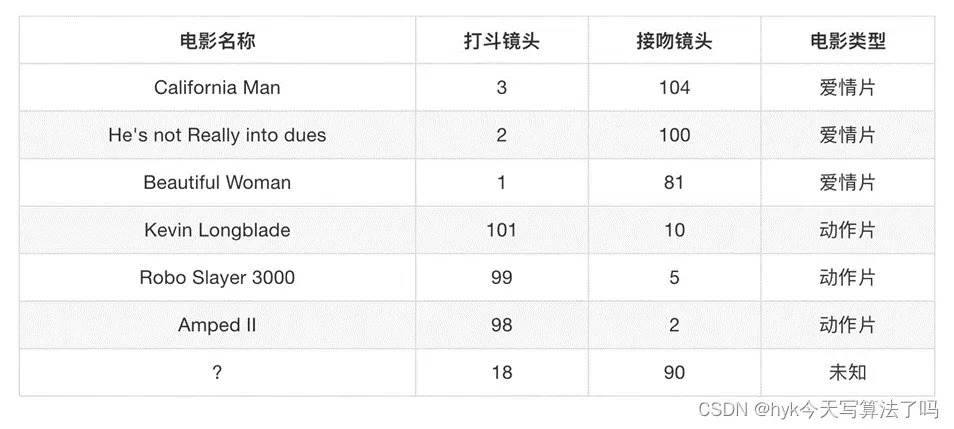
其中? 号电影不知道类别,如何去预测?我们可以利用K近邻算法的思想, 利用对应特征与已知几个电影特征的距离来判断属于哪一类别。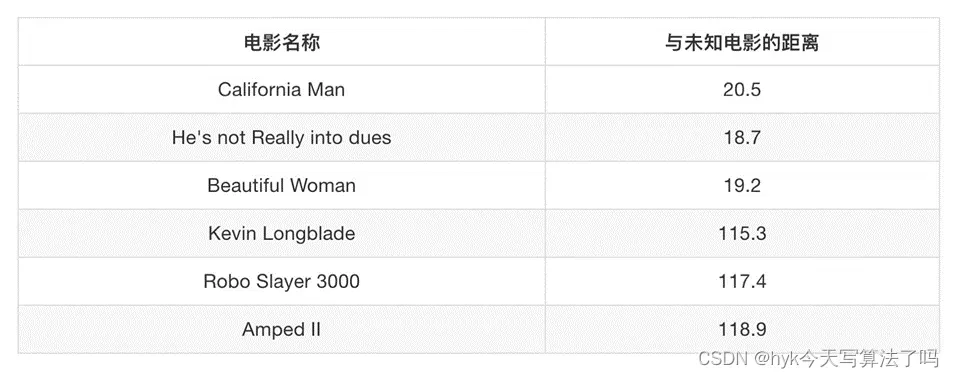
二、API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
部分参数说明:
n_neighbors:int,可选(默认= 5),KNN算法查询默认使用的邻居数
algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},可选用于计算最近邻居的算法:‘ball_tree’将会使用 BallTree,‘kd_tree’将使用 KDTree。‘auto’将尝试根据传递给fit方法的值来决定最合适的算法。 (不同实现方式影响效率)
3. 实际案例:预测签到位置
1.题目要求

数据介绍:会根据用户的位置、准确率和时间戳来预测用户正在查看的业务。
train.csv,test.csv
row_id:登记事件的ID
xy:坐标
精度:定位精度
时间:时间戳
place_id:业务的ID,这是您预测的目标
官网:https://www.kaggle.com/navoshta/grid-knn/data
2.分析
对数据做一些基本的处理(这里做的一些处理可能不会达到很好的效果,我们只是简单的尝试,有些特征可以按照一些特征选择的方法来处理)
1、缩小数据集范围 DataFrame.query()
2、 删除没用的日期数据 DataFrame.drop(可以选择保留)
3、 将签到位置少于n个用户的删除
3.代码

四、K近邻方法总结
优势:
简单,易于理解,易于实施,无需培训
缺点:
懒惰算法,对测试样本分类时的计算量大,内存开销大必须指定K值,K值选择不当则分类精度不能保证
使用场景:
小数据场景,几千到几万个样本,具体场景具体服务去测试
版权声明:本文为博主hyk今天写算法了吗原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/m0_52000372/article/details/123307409