1. 基本信息
| 题目 | 论文作者与单位 | 来源 | 年份 |
|---|---|---|---|
| Template-Based Named Entity Recognition Using BART | Leyang Cui(Zhejiang University),Yu Wu(Microsoft Research Asia),Westlake University | ACL2021 – Findings | 2021 |
18 Citations, 36 References
论文链接: https://aclanthology.org/2021.findings-acl.161.pdf
论文代码: https://github.com/Nealcly/templateNER
2. 要点
| 研究主题 | 问题背景 | 核心方法流程 | 亮点 | 数据集 | 结论 | 论文类型 | 关键字 |
|---|---|---|---|---|---|---|---|
| few-shot NER | 1. Neural NER models require large labeled training data,可是有些领域的数据并不多;希望把比较丰富的领域知识迁移到知识稀疏的领域中(即few-show NER问题); 2. 目前的方法对knowledge transfer的使用不充分; 3. 对于few-show NER,现在的方法是使用距离来衡量的方法(using distance metrics),可是这个方法有多不足。 |
1. 提出了基于模板的NER方法(新方法); 2.把NER问题看成一个seq2seq的语言模型排序问题(生成问题); 3.候选实体span填充的句子与状态模型代表着原序列与目标序列。 |
1. 利用预训练模型好的生成能力,可以使用标注实例子在新领域上微调; 2. 与distance-based methods相比,即使两个领域相关很大,更具强壮性; 3. 相对于传统方法(pre-trained model with a softmax/CRF),使用到任意新的实体类型中不用改变输出层,可继续学习。【1】 4. 第一个使用预训练生式方法去解决few-show 序列 标注问题。 |
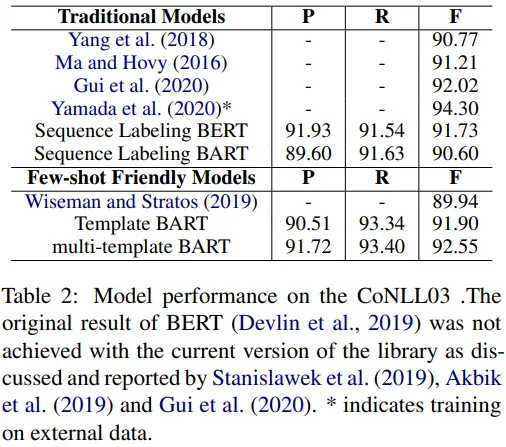
CoNLL2003,MIT Movie Review,MIT Restaurant Review,ATIS | 1. 在一般的rich-resorce任务可获得不错的效果【the proposed method achieves 92.55% F1 score on the CoNLL03((rich-resource task);】 2.在low-resource任务上也可获得不错的效果, 比fifine-tuning BERT的效果要好【10.88%, 15.34%, and 11.73% F1 score on the MIT Movie, the MIT Restaurant, and the ATIS(low-resource task)】 |
Few-shot; NER; Prompt |
3. 模型(核心内容)
3.1 传统模型(a)
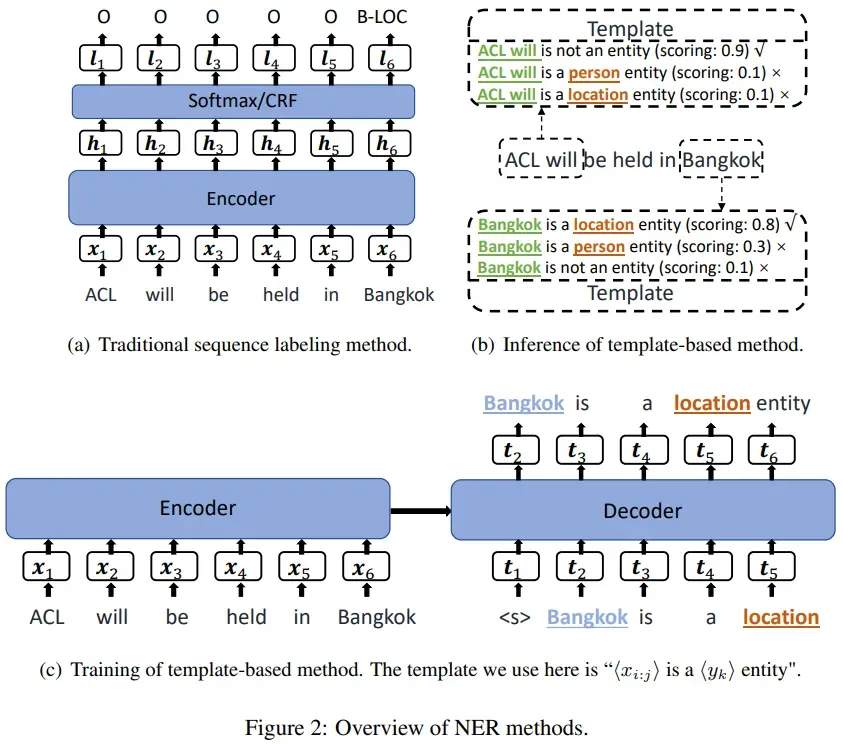
一个模板只能识别一个实体。
3.2 核心内容
We consider NER as a language model ranking problem under a seq2seq framework.
输入:X= {x1, . . . , xn}
标注; T_yk,xi:j = {t1, . . . , tm}
- 模型设计的步骤:Template-Based Method->Inference->Training
- 创建模板(Template)
方法:手动创建模板;
内容:
a. 两个slot—candidate_span与entity_type;
b. 一对一的映射: label集合L到自然语言(natural word)集合Y的一一映射的集合;
c. 使用词去定义模板T_+;(例如:is a location entity.),另外定义负模板T—(e.g.,
h
candidate_span
i
is not a named entity.);得到模板列表: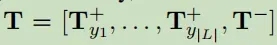
T_yk,xi:j 表示 < x_i:j > is a同理也给出了否的模板:< x_i:j > is not a name enity . - 推理
第一步, 枚举所有的spans, 把每个span填入到模板中;— 论文作了限制,限定为1~8之间的n-grams,所以一个句子就产生8*n(句子长度)个模型;可以理解为生成的实体长度为8个字。
计算模板的概率(因为一个模板对应一个实体的输出,这个概率也是实体的概率):
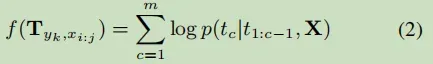
不可以解决overlap的问题。
- 训练
a. 输入: (X,T);负样本是正样本的1.5倍;
b. 过程:
首先用BART的encoder对X进行编码: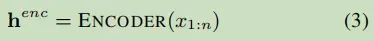
解码: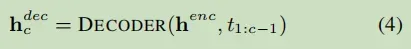
条件概率: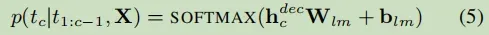
损失函数: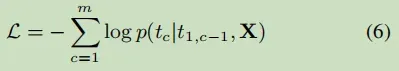
- 迁移学习
只是标签不同,但标签是生成的数据,所以不需要针对任务修改模型。只需更改数据并直接使用即可。
4. 实验与分析
分两实验环境进行对比:resource-rich and few-shot
在few-shot的实验中,是一个跨域的实验,在目标域中存在unseen的标签。
4.1 数据集
- 使用不同模板对结果的影响(CoNLL03)

结论:模板是一个很大的因素。 - CoNLL03 Results
对于unseen的跨域的效果:
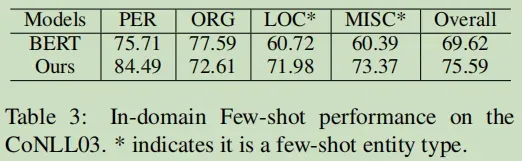
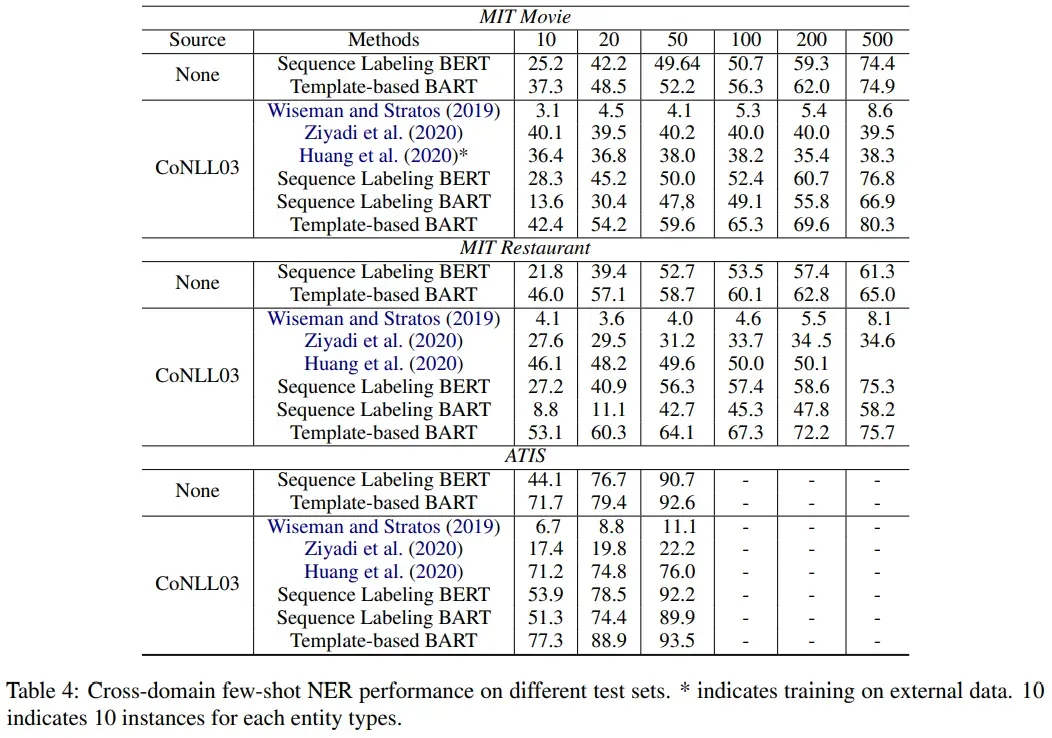
3. Cross-domain Few-Shot NER Result
调查有多少信息迁移到其他域。
5. 代码
没见过
6. 总结
6.1 优
相关工作和相关背景都写得很好;
提出了一种新的思路,在few-shot方面获得好的效果。
6.4 不足
==效率性能是一个问题,一个句子中,首先把span进行了枚举,然后又把所有的枚举span进行了每个模板的构造,一个句子就生成了很多的输入样本。==基于这些,在工程上估计是很难满足的了。
7. 知识整理(知识点,要读的文献,摘取原文)
使用距离度量的方法来解决few-shot NER:
The main idea is to train a similarity function based on instances in the source domain, and then make use of the similarity function in the target domain as a nearest neighbor criterion for few-shot NER.
提取表达式:
Named entity recognition (NER) is a fundamental task in natural language processing, which identi-fifies mention spans from text inputs according to pre-defifined entity categories (Tjong Kim Sang and De Meulder, 2003), such as location, person, or ganization, etc.
NER的方法相关方法:
解决语言任务的模板方法:
- 【2】first use prompt for few-shot learning in text classifification tasks; – 第一个使用prompt去处理few-shot文本分类 问题;
- 【3】rephrase inputs as cloze questions for text classifification. – 对于分类,把输入修改成cloze问题;
- Schick et al. (2020) and Gao et al. (2020) 在【3】 的基础上作了优化;优化为自动生成标注与自动生成模板;
- 【4】采用模板去解决关系抽取问题;
论文提出来的方法跟模板这个方法也是in line with的。不同点是:上面那些方法是基于句子级的;这个论文是定位在一个span上的实体一个分数;
8. 参考文献
【1】Shaofu Lin, Jiangfan Gao, Shun Zhang, Xiaobo He, Ying Sheng, and Jianhui Chen. 2020. A continuous learning method for recognizing named entities
by integrating domain contextual relevance measurement and web farming mode of web intelligence. InWorld Wide Web.
【2】Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu,
Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam Mc Candlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners.
【3】Timo Schick and Hinrich Schütze. 2020. Exploiting cloze questions for few shot text classifification and natural language inference.
【4】Fabio Petroni, Tim Rocktäschel, Sebastian Riedel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, and Alexander Miller. 2019. Language models as knowledge bases? InProceedings of the 2019 Conference on Empirical Methods in Natural LanguageProcessing and the 9th International Joint Conference on Natural Language Processing (EMNLP IJCNLP), pages 2463–2473, Hong Kong, China. Association for Computational Linguistics.
made by happyprince
版权声明:本文为博主happyprince原创文章,版权归属原作者,如果侵权,请联系我们删除!