目前很多情感聚类都是细分到逐词分析,而对于逐句的情感分析可以通过将文本转化为数字矩阵从而采用传统的聚类方法来实现,这里以K均值为例进行演示:
import pandas as pd
import codecs
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
if __name__ == "__main__":
corpus = []
#读取预料,去除首位缩进,一行预料为一个文档
for line in open('data.txt', 'r',encoding='UTF-8').readlines():
corpus.append(line.strip())
#将文本中的词语转换为词频矩阵 矩阵元素a[i][j] 表示j词在i类文本下的词频
vectorizer = CountVectorizer(min_df=5)
#该类会统计每个词语的tf-idf权值
transformer = TfidfTransformer()
#第一个fit_transform是计算tf-idf 第二个fit_transform是将文本转为词频矩阵
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
#获取词袋模型中的所有词语
word = vectorizer.get_feature_names()
#将tf-idf矩阵抽取出来,元素w[i][j]表示j词在i类文本中的tf-idf权重
weight = tfidf.toarray()
#打印特征向量文本内容
resName = "Tfidf_Result.txt"
result = codecs.open(resName, 'w', 'utf-8')
for j in range(len(word)):
result.write(word[j] + ' ')
result.write('\r\n\r\n')
#每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重
for i in range(len(weight)):
for j in range(len(word)):
result.write(str(weight[i][j]) + ' ')
result.write('\r\n\r\n')
result.close()
print( 'Start Kmeans:')
from sklearn.cluster import KMeans
clf = KMeans(n_clusters=6) #聚类数k值
s = clf.fit(weight)
#每个样本所属的簇
label = []
i = 1
while i <= len(clf.labels_):
label.append(clf.labels_[i-1])
i = i + 1
y_pred = clf.labels_
from sklearn.decomposition import PCA
pca = PCA(n_components=2) #输出两维
newData = pca.fit_transform(weight) #载入N维
xs, ys = newData[:, 0], newData[:, 1]
#设置颜色
cluster_colors = {0: 'r', 1: 'yellow', 2: 'b', 3: 'chartreuse', 4: 'purple', 5: '#FFC0CB', 6: '#6A5ACD', 7: '#98FB98'}
#设置类名
cluster_names = {0: u'类0', 1: u'类1',2: u'类2',3: u'类3',4: u'类4',5: u'类5',6: u'类6',7: u'类7'}
df = pd.DataFrame(dict(x=xs, y=ys, label=y_pred, title=corpus))
groups = df.groupby('label')
fig, ax = plt.subplots(figsize=(8, 5)) # set size
ax.margins(0.02)
for name, group in groups:
ax.plot(group.x, group.y, marker='o', linestyle='', ms=10, label=cluster_names[name], color=cluster_colors[name], mec='none')
plt.show()聚类效果如下:
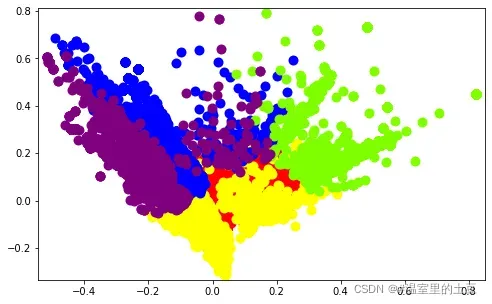
这里值得注意的是,聚类的原始语料是去停后以单词为基本单元的分词和干净评论。当然,以评论为基本处理单元逐句分析,难免会导致信息重叠和缺失,比如“这手机的屏幕好刺眼,用久了也没有卡住,但是它有点贵”和“手机很贵”。积分但值得。”这两条评论无论是归类为“手机性能”还是“商品价格”,也可能同时被处理为“手机价格”,但其余信息被抹去,从某种意义上说,它们不能完全是同一主题的评论。
版权声明:本文为博主#温室里的土豆原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/m0_52488320/article/details/123314467