一个深度学习入门的菜鸟,希望通过做笔记的方式记录下自己学到的东西,希望对同样入门的人有所帮助。希望大佬们帮忙指正错误~侵权立即删除。
内容
一、NNLM的网络结构分析
二、NNLM的代码实现
一、NNLM的网络结构分析
神经网络语言模型NNLM是概率语言模型,它通过神经网络来计算概率语言模型中每个参数。
模型如图
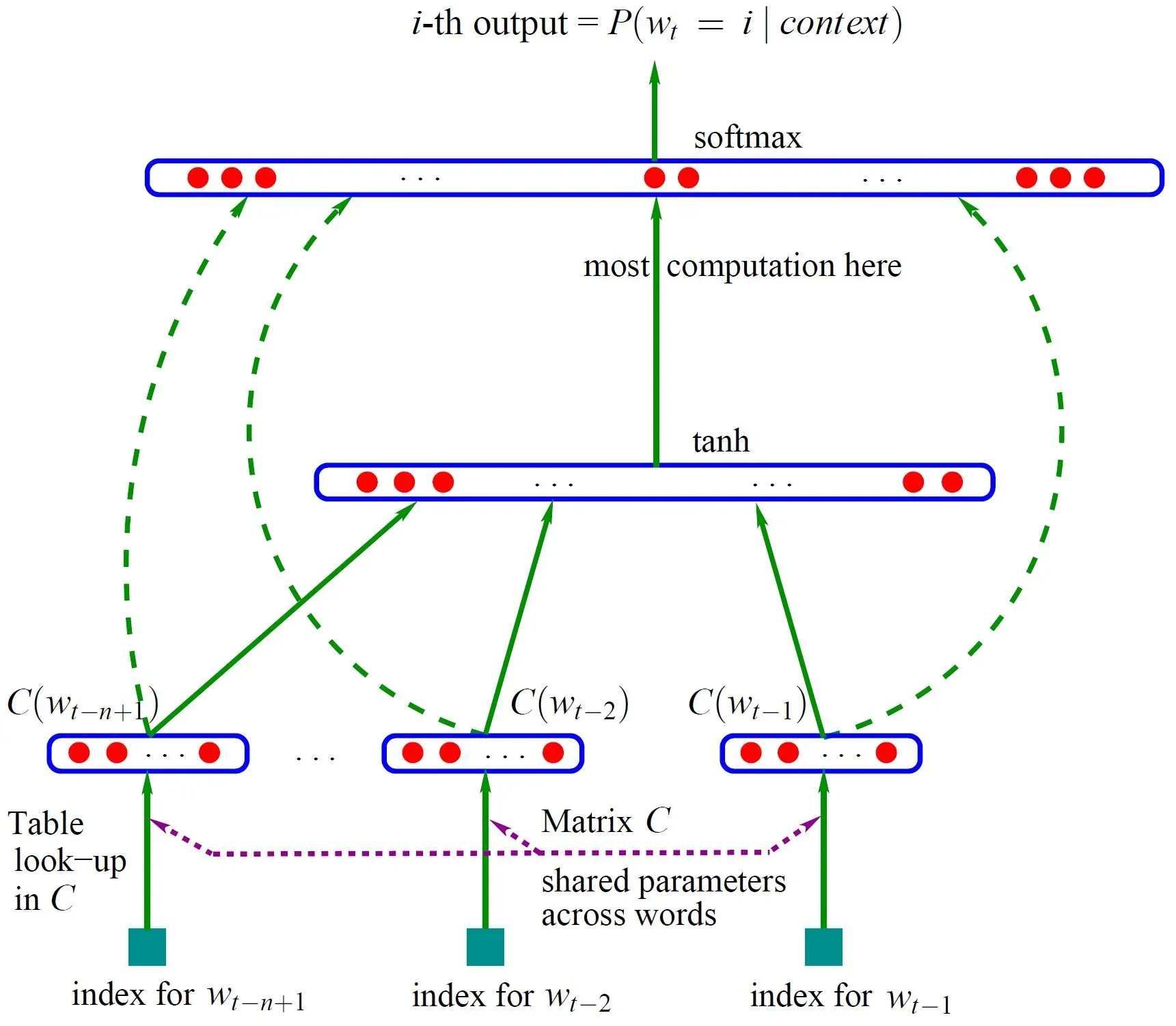
模型输入:,即输入的是
的前n-1个词
模型输出:根据这已知的 n – 1 个词预测下一个词
上图:
语料库的词向量表示:矩阵C —— 大小为 |V| * m ,V表示语料中的总词数,m为词向量的维度
C(w)指w所对应的词向量,即在C中取w对应的一行
🌳网络的第一层(即输入层):将这 n – 1 个向量首尾拼接起来形成一个 m * (n – 1) 的向量x
🌳网络的第二层(即隐藏层):首先使用一个全连接层: d + Hx 计算得到(d表示偏置,H表示对应向量的权重)。通过全连接层后再使用tanh激活函数进行激活。
🌳网络的第三层(即输出层):本质上这也是个全连接层。一共有 V 个结点,每个输出节点yi(其中 i 为索引)表示下一个词语为 i 的log概率,最后使用 softmax 激活函数将输出的 yi 进行归一化处理。
🌳 整个事情是:
y = softmax[log(U * tanh( d + Hx ) + Wx + b)]
在:
U是 | V | * h 的矩阵,是隐藏层到输出层的参数;
W是 | V | * (n – 1) * m 的矩阵,主要是将输入层的数据结果也放到输出层进行计算的线性变换,称为直连边(若不需要直连边,则令W = 0)
二、NNLM的代码实现
待处理的文件(1.txt)内容
I have a pen.I love this pen.I have an apple.I love eating apples.
You have a book.
🎈 首先导入需要的库
import torch
import torch.nn as nn
import torch.optim as optim🎈 然后对文件的数据进行处理,变成以句子划分的列表
path = "1.txt"
f = open(path, 'r', encoding= 'utf-8', errors= 'ignore')
text = []
piece = ''
for line in f:
for uchar in line:
if uchar == '\n':
continue
if uchar == '.' or uchar == '?' or uchar == '!':
text.append(piece)
piece = ''
else:
piece = piece + uchar此时的text为:
[‘I have a pen’, ‘I love this pen’, ‘I have an apple’, ‘I love eating apples’, ‘You have a book’]
🎈 带出句子中的单词并去重
word_list = " ".join(text).split()
word_list = list(set(word_list))🎈 索引词
word_dict = {w:i for i, w in enumerate(word_list)} #单词-索引
number_dict = {i:w for i, w in enumerate(word_list)} #索引-单词🎈一些参数设置
nlen = len(word_dict) #获得词典长度
step = len(text[0].split())-1 #步长,即用前几个单词来预测下一个单词(这里是预测最后一个词是什么)
hidden = 2#隐藏层的参数量(即节点数)
m = 2#嵌入词向量的维度
🎈 网页设计
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(num_embeddings = nlen, embedding_dim = m) # 词表
#nn.Embedding:即给一个编号,嵌入层就能返回这个编号对应的嵌入向量,嵌入向量反映了各个编号代表的符号之间的语义关系。即输入为一个编号列表,输出为对应的符号嵌入向量列表。
#index为(0,nlen-1)
self.H = nn.Parameter(torch.randn(step * m, hidden).type(torch.FloatTensor)) # 输入层到隐藏层的权重
self.d = nn.Parameter(torch.randn(hidden).type(torch.FloatTensor)) # 隐藏层的偏置
#nn.Parameter: 作为nn.Module中的可训练参数使用
#torch.randn: 用来生成随机数字的tensor,这些随机数字满足标准正态分布(0~1)
self.U = nn.Parameter(torch.randn(hidden, nlen).type(torch.FloatTensor)) # 隐藏层到输出层的权重
self.W = nn.Parameter(torch.randn(step * m, nlen).type(torch.FloatTensor)) # 输入层到输出层的权重
self.b = nn.Parameter(torch.randn(nlen).type(torch.FloatTensor)) # 输出层的偏置
def forward(self, input):
'''
input: [batchsize, n_steps]
x: [batchsize, n_steps*m]
hidden_layer: [batchsize, n_hidden]
output: [batchsize, num_words]
'''
x = self.C(input) # 获得一个batch的词向量的词表
x = x.view(-1, step * m)
hidden_out = torch.tanh(torch.mm(x, self.H) + self.d) # 获取隐藏层输出
#torch.mm(a, b)是矩阵a和b矩阵相乘
output = torch.mm(x, self.W) + torch.mm(hidden_out, self.U) + self.b # 获得输出层输出
return output🎈 处理网络的输入
def make_batch(text):
'''
input_batch:一组batch中前steps个单词的索引
target_batch:一组batch中每句话待预测单词的索引
这里是为了预测句子的最后一个词是啥
'''
input_batch = []
target_batch = []
for piece in text:
word = piece.split()
input = [word_dict[w] for w in word[:-1]]
target = word_dict[word[-1]]
input_batch.append(input)
target_batch.append(target)
return torch.LongTensor(input_batch), torch.LongTensor(target_batch)转移
input_batch, target_batch = make_batch(text)🎈培训
model = NNLM()
criterion = nn.CrossEntropyLoss() # 使用cross entropy作为loss function
optimizer = optim.Adam(model.parameters(), lr = 0.001) # 使用Adam作为optimizer
for epoch in range(2000):
optimizer.zero_grad()# 梯度清零
output = model(input_batch)
loss = criterion(output, target_batch)
if (epoch + 1) % 100 == 0:
print("Epoch:{}".format(epoch+1), "Loss:{:.3f}".format(loss))
# 反向传播
loss.backward()
# 更新权重参数
optimizer.step()🎈输出设置:先得到预测的索引,再组合输出
#取出预测的索引
predict = model(input_batch).data.max(1, keepdim=True)[1]
print([t.split()[:step] for t in text], '->', [number_dict[n.item()] for n in
predict.squeeze()])
#第一部分是取出待预测的句子的那些词语;后面的部分是为了取出预测索引对应的词语🎈 输出结果
[[‘I’, ‘have’, ‘a’], [‘I’, ‘love’, ‘this’], [‘I’, ‘have’, ‘an’], [‘I’, ‘love’, ‘eating’], [‘You’, ‘have’, ‘a’]] -> [‘pen’, ‘pen’, ‘apple’, ‘apples’, ‘book’]
欢迎大家在评论区批评指正,谢谢~
版权声明:本文为博主tt丫原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_55073640/article/details/123299442