背景
Deep Crossing模型的应用场景是微软搜索引擎Bing中的搜索广告推荐场景。用户在搜索引擎中输入搜索词之后,搜索引擎除了会返回相关结果,还会返回与搜索词相关的广告,这也是大多数搜索引擎的主要赢利模式。尽可能地增加搜索广告的点击率,准确地预测广告点击率,并以此作为广告排序的指标之一,是非常重要的工作,也是Deep Crossing模型的优化目标。
微软于2016年提出了Deep Crossing模型,是深度学习架构在推荐系统中的第一次完整应用。虽然自2014年以来,就陆续有公司透露在其推荐系统中应用了深度学习模型,但直到Deep Crossing模型发布的当年,才有正式的论文分享了完整的深度学习推荐系统的技术细节。Deep Crossing模型完整地解决了从特征工程、稀疏向量稠密化、多层神经网络进行优化目标拟合一系列深度学习在推荐系统中的应用问题,为后续的研究打下了良好的基础。
Deep Crossing模型的网络结构
为完成端到端的训练,Deep Crossing模型要在其内部网络中解决如下问题。
(1)离散类特征编码后过于稀疏,不利于直接输入神经网络进行训练,如何解决稀疏特征向量稠密化的问题。
(2)如何解决特征自动交叉组合的问题。
(3 )如何在输出层中达成问题设定的优化目标。
Deep Crossing模型分别设置了不同的神经网络层来解决上述问题。如下图所示,其网络结构主要包括4层——Embedding层、Stacking层、Multiple Residual Units层和Scoring层。
接下来从下往上介绍各层的功能和实现。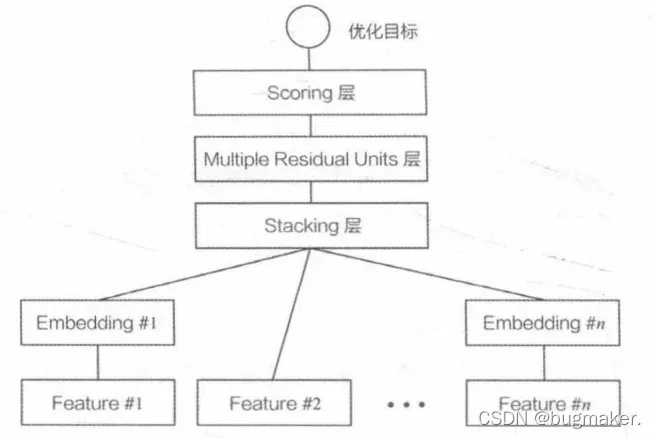
Embedding层:Embedding层的作用是将稀疏的类別型特征转换成稠密的Embedding向量。从图中可以看到,每一个特征经过Embedding层后,会转换成对应的Embedding向量。Embedding层的结构以经典的全连接层(Fully Connected Layer )结构为主, 一般形式为: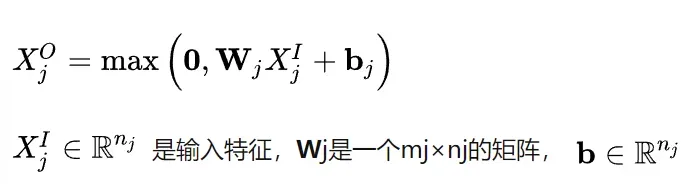
Embedding技术本身作为深度学习中研究非常广泛的话题,已经衍生出了Word2vec、Graph Embedding 等多种不同的 Embedding 方法。一般来说,Embedding向量的维度应远小于原始的稀疏特征向量,几十到上百维一般就能满足需求。
Stacking层:Stacking层(堆叠层)的作用比较简单,是把不同的Embedding特征和数值型特征拼接在一起,形成新的包含全部特征的特征向量,该层通常也被称为连接层。
Multiple Residual Units层:该层的主要结构是多层感知机,相比标准的以感知机为基本单元的神经网络,DeepCrossing模型采用了多层残差网络作为MLP的具体实现。最著名的残差网络是在 ImageNet大赛中由微软研究员何恺明提出的152层残差网络。在推荐模型中的应用,也是残差网络首次在图像识别领域之外的成功推广。通过多层残差网络对特征向量各个维度进行充分的交叉组合,使模型能够抓取到更多的非线性特征和组合特征的信息,进而使深度学习模型在表达能力上较传统机器学习模型大为增强。
Scoring层:Scoring层作为输出层,就是为了拟合优化目标而存在的。对于CTR预估这类二分类问题,Scoring层往往使用的是逻辑回归模型,利用之前处理得到的特征预测最终的点击率。
具体流程如下:
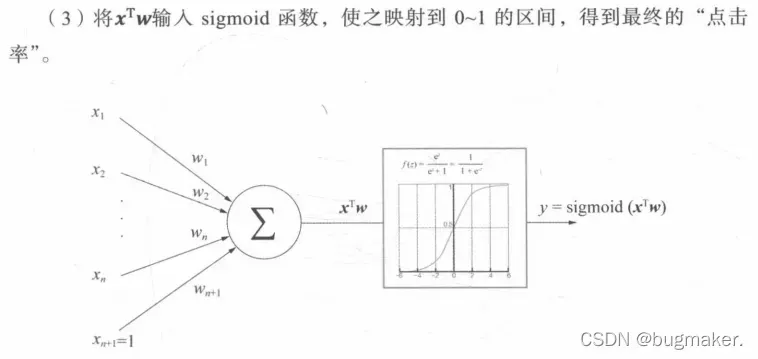
训练方式选择梯度下降法,损失函数采用log损失函数。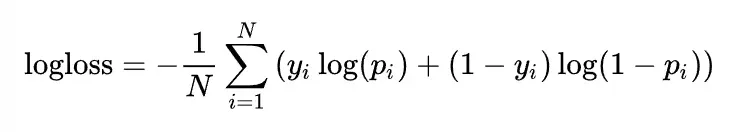
以上就是Deep Crossing的模型结构,最终得到基于Deep Crossing的CTR预估模型。
Deep Crossing模型对特征交叉方法的革命
从目前的时间节点上看,Deep Crossing模型是平淡无奇的,因为它没有引入任何诸如注意力机制、序列模型等特殊的模型结构,只是采用了常规的 “Embedding+多层神经网络”的经典深度学习结构。但从历史的尺度看,Deep Crossing模型的出现是有革命意义的。Deep Crossing模型中没有任何人工特征工程的参与,原始特征经Embedding后输入神经网络层,将全部特征交叉的任务交给模型。相比FM、FFM模型只具备二阶特征交叉的能力,Deep Crossing模型可以通过调整神经网络的深度进行特征之间的“深度交叉”,这也是Deep Crossing名称的由来。
补充
1. 残差神经网络
残差神经网络的出现主要是为了解决以下问题:
- 神经网络是不是越深越好?对于传统的基于感知机的神经网络,当网络加深之后,往往存在过拟合现象,即网络越深,在测试集上的表现越差。而在残差神经网络中,由于有输入向量短路的存在,很多时候可以越过两层ReLU网络,减少过拟合现象的发生。
- 当神经网络足够深时,往往存在严重的梯度消失现象。梯度消失现象是指在梯度反向传播过程中,越靠近输入端,梯度的幅度越小,参数收敛的速度越慢。为了解决这个问题,残差单元使用了 ReLU激活函数取代原来的 sigmoid激活函数。此外,输人向量短路相当于直接把梯度毫无变化地传递到 下一层,这也使残差网络的收敛速度更快。
大意:
在残差神经网络中,使用了一种全新的残差结构单元,如下图所示。可以看到,残差单元的输出由多个卷积层级联的输出和通过一条段落得到的输入元素相加(保证卷积层输出和输入元素维度相同),再经过ReLU激活函数得到最后的输出结果。将这种结构级联起来,就得到了残差网络。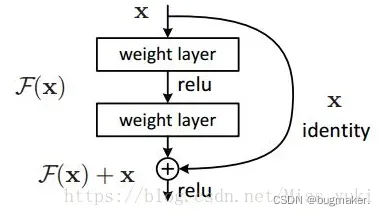 在传统的神经网络中,一层网络的数据源只能是上一层的网络,数据一层一层往下流。在残差神经网络中,前一层的输出数据将与进一步处理的数据一起作为后续数据输入。没有加入这种“短路”设计的传统网络缺乏这部分数据的参考,是一种信息缺失现象。
在传统的神经网络中,一层网络的数据源只能是上一层的网络,数据一层一层往下流。在残差神经网络中,前一层的输出数据将与进一步处理的数据一起作为后续数据输入。没有加入这种“短路”设计的传统网络缺乏这部分数据的参考,是一种信息缺失现象。
在传统的网络中,一个由2层网络组成的映射关系我们可以使用F(x)的这样一个期望函数来拟合。而现在,我们希望用H(x)=F(x)+x来拟合,这样就引入了更为丰富的参考信息或者说更为丰富的维度,网络就可以学到更为丰富的内容。
2. 为什么要做特征交叉
在仅使用单个特征而不是相交特征进行判断的情况下,会造成信息丢失的问题,有时甚至会得出错误的结论。也就是说,在对一个样本集进行分组研究时,在分组比较中具有优势的一方有时是整体评价中的输家。这种违反直觉的现象被称为“辛普森悖论”。
举例如下:假设表2-1和表2-2所示为某视频应用中男性用户和女性用户点击视频的数据。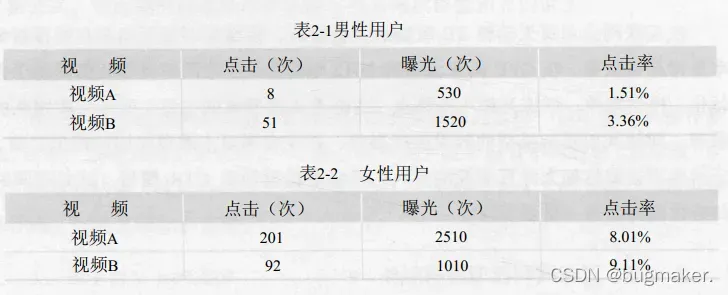
从以上数据中可以看出,无论男性用户还是女性用户,对视频B的点击率都高于视频A,显然推荐系统应该优先考虑向用户推荐视频B。
但是,如果忽略性别这个维度将数据汇总,视频A的点击率居然比视频B高。如果据此进行推荐, 将得出与之前的结果完全相反的结论,这就是所谓的“辛普森悖论”。
在“辛普森悖论”的例子中,分组实验相当于使用“性别”+“视频id”的组合特征计算点击率,而汇总实验则使用“视频id”这一单一特征计算点击率。汇总实验对高维特征进行了合并,损失了大量的有效信息,因此无法正确刻画数据模式。所以,对单一特征进行交叉处理,可以使模型能够抓取到更多的非线性特征和组合特征的信息,进而使深度学习模型在表达能力上较传统机器学习模型大为增强。
版权声明:本文为博主bugmaker.原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_42385782/article/details/123306389