论文摘要:
文章主旨:在本文中,我们回顾了这些视觉Transformer模型,将它们分为不同的任务,并分析了它们的优缺点。我们探讨的主要类别包括主干网络、高/中级视觉、低级视觉和视频处理。我们还包括有效的Transformer方法,用于将Transformer推进基于设备的实际应用。此外,我们还简要介绍了计算机视觉中的自我注意机制,因为它是Transformer的基本组成部分。在本文的最后,我们讨论了视觉Transformer面临的挑战,并提供了几个进一步的研究方向。
其他章节:
Transformer综述(A Survey on Vision Transformer) 阅读学习笔记(二)
1. Transformer方向与历史
1.1 高/中级视觉处理
高级视觉处理:对图像中所见内容的解释和使用。
中级视觉处理:如何将这些信息组织成我们所体验的物体和表面。
(鉴于在基于DNN的视觉系统中,高级视觉和中级视觉之间的差距变得越来越模糊,这里将它们作为一个单一的类别来对待。)
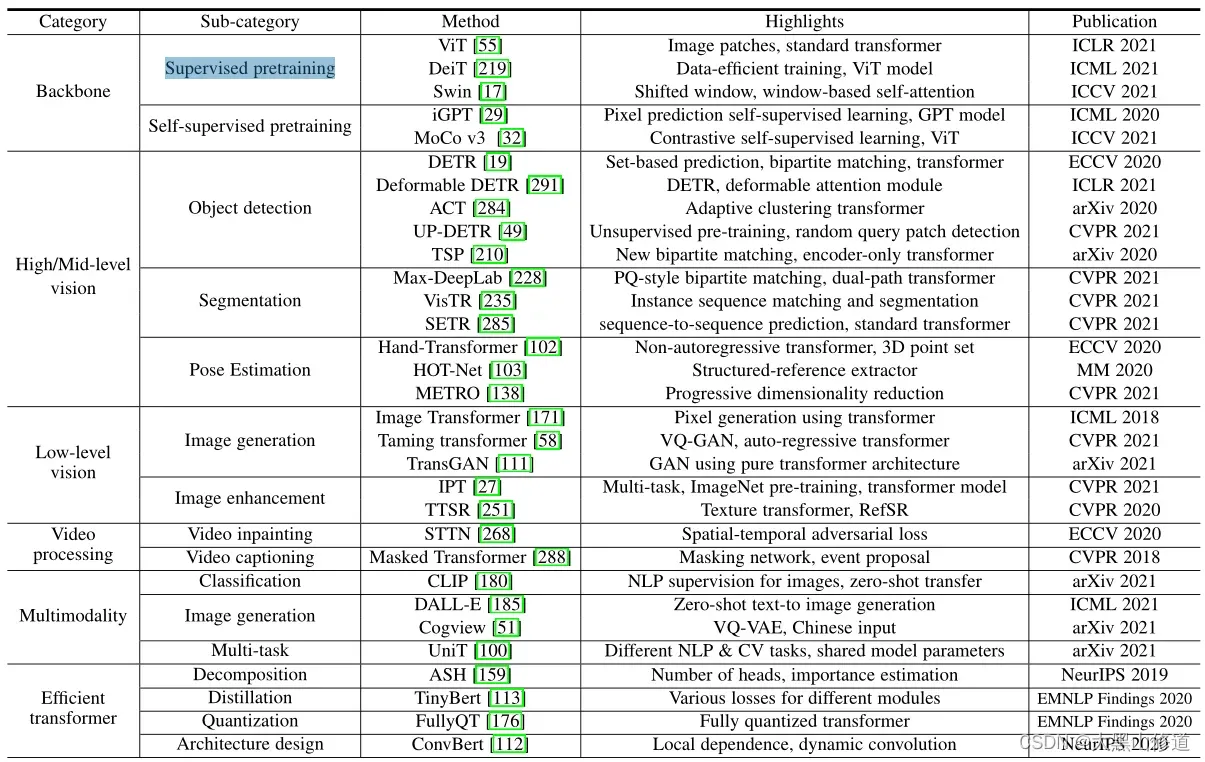
解决这些高/中级视觉任务的几个Transformer模型的例子包括:
用于目标检测的DETR( End-to-end object detection with transformers. InECCV,2020.)、用于目标检测的可变形DETR(Deformable detr: Deformable transformers for end-to-end object detection. InICLR,
2021)和用于分割的Max-DeepLab( Max-deeplab: End-to-end panoptic segmentation with mask transformers. InCVPR)。
1.2 低级图像处理
低级图像处理:主要处理从图像中提取描述(这种描述通常表示为图像本身)
低级图像处理的典型应用包括超分辨率、图像去噪和风格转换。
目前,只有少数作品[27]、[171]在低层视觉中使用了变压器,这就产生了进一步研究的需要。
[27]:Pre-trained image processing transformer. InCVPR, 2021
[171]:Image transformer. InICML
1.3 视频处理
这是计算机视觉和基于图像的任务的重要组成部分。
由于视频的时序性,Transformer本质上很适合用于视频任务[288]、[268],其中它开始与传统的CNN和RNN平起平坐。
[288]:End-to-end dense video captioning with masked transformer. InCVPR,2018
[268]: Learning joint spatial-temporal transformations for video inpainting. InECCV, 2020.
1.4 Vision Transformer 发展关键里程碑图
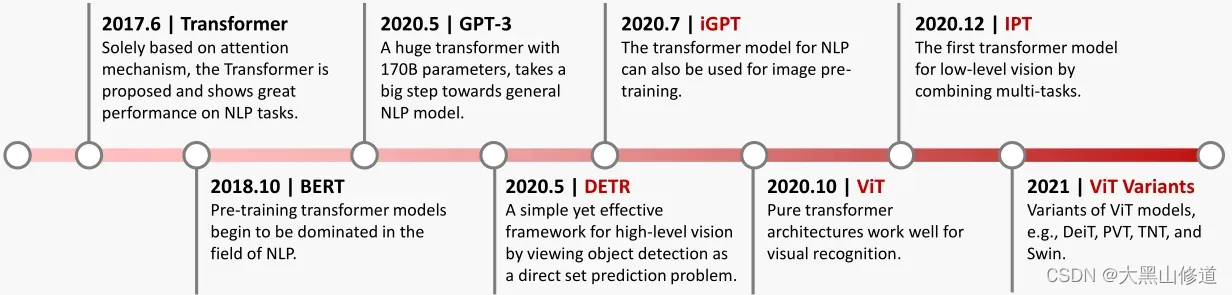
2017.6: 基于注意力机制的Transformer被提出,并在NLP任务中表现出很好的性能。
2018.10: 在NLP领域,预训练Transformer模型开始占据主导地位,代表:BERT。
2020.5:GPT-3,一台具有170B参数的巨型Transformer ,向通用NLP模型迈进了一大步。
2020.5:DETR,通过将目标检测视为直接集合预测问题,为高级视觉提供了一种简单而有效的框架。
2020.7: iGPT,NLP的Transformer模型也可用于图像预训练。
2020.10: ViT,实现纯Transformer架构可以很好地进行视觉识别。
2020.12:IPT,第一个结合多任务的低层视觉Transformer模型。
2021: ViTVariants,VIT模型的变体,例如DeiT、PVT、TNT和Swin。
1.5 Vision Transformer代表作
2. FORMULATION OF TRANSFORMER
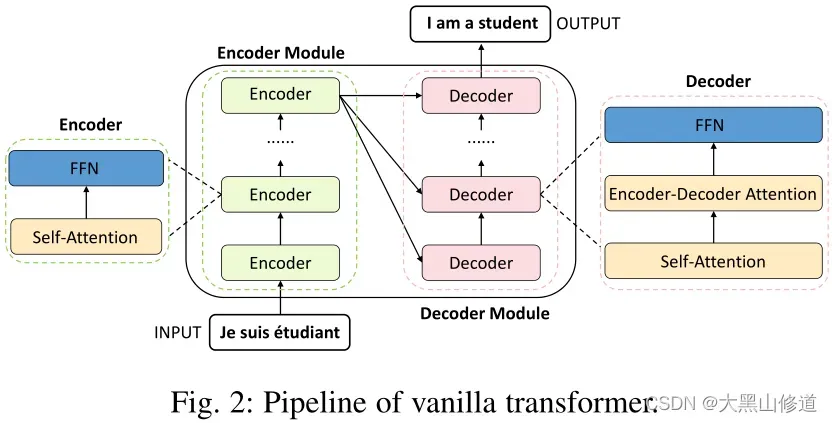
由上图所示,Transformer由一个编码器模块和一个解码器模块组成,其中包含多个相同架构的编码器/解码器。 每个编码器和解码器由一个自注意层和一个前馈神经网络组成,而每个解码器还包含一个编码器-解码器注意层。
2.1 Scaled Dot-product Self-Attention 自注意力
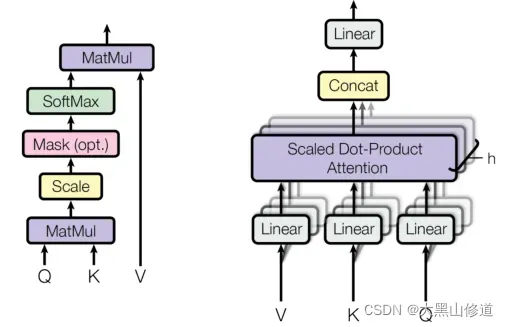
在自我关注层,输入向量首先被转换成三个不同的向量:查询向量Q、关键向量k和维度为 d_q = d_k = d_v = d_model = 512 的值向量v。然后,从不同输入中导出的向量被压缩到三个不同的矩阵中,即Q、K和V。随后,不同输入向量之间的注意函数计算如下(如图3所示):
Step 1:计算不同输入向量之间的分数:
步骤 2:标准化梯度稳定性分数:
第三步:使用softmax将分数转换为概率:
第四步:获取加权值矩阵:
该过程可以统一为一个功能:
第一步计算每对不同向量之间的分数,这些分数决定了我们在当前位置编码单词时对其他单词的关注程度。第2步将分数标准化,以增强梯度稳定性,从而改进训练,第3步将分数转换为概率。最后,将每个值向量乘以概率之和。更大概率的V型载体从以下几层获得额外关注。
解码器模块中的编码器-解码器注意层与编码器模块中的自我注意层类似,但以下例外情况除外:密钥矩阵和值矩阵V源自编码器模块,查询矩阵Q源自前一层。
注意,前面的过程对于每个单词的位置是不变的,这意味着自注意力层缺乏捕获句子中单词位置信息的能力。然而,语言中句子的顺序性要求我们将位置信息合并到编码中。为了解决这个问题并获得单词的最终输入向量,在原始输入嵌入中添加了具有维度模型的位置编码。具体来说,该位置使用以下等式编码:
其中pos表示单词在句子中的位置,i表示位置编码的当前维度。通过这种方式,位置编码的每个元素对应于一个正弦波,并且它允许变压器模型学习通过相对位置参与,并在推理期间外推到更长的序列长度
2.1.1 Multi-Head Attention 多头注意力
多头注意是一种机制,可以用来提高vanilla自我注意层的性能。请注意,对于一个给定的参考词,我们在通读句子时通常希望关注其他几个词。一个单一的自我关注层限制了我们专注于一个或多个特定位置的能力,同时又不影响对其他同等重要位置的关注。这是通过赋予注意层不同的表示子空间来实现的。具体地说,不同的头部使用不同的查询矩阵、键矩阵和值矩阵,由于随机初始化,这些矩阵可以在训练后将输入向量投影到不同的表示子空间。
为了更详细地说明这一点,在给定输入向量和Headsh数量的情况下,首先将输入向量转换为三个不同的向量组:查询组、键组和值组。每组中有h个向量,维度为: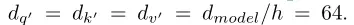
然后将来自不同输入的向量打包成三组不同的矩阵: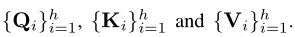
多头注意力过程如下:
2.2 Transformer其他关键概念
2.2.1 Residual Connection in the Encoder and Decoder 编解码器中的残余连接
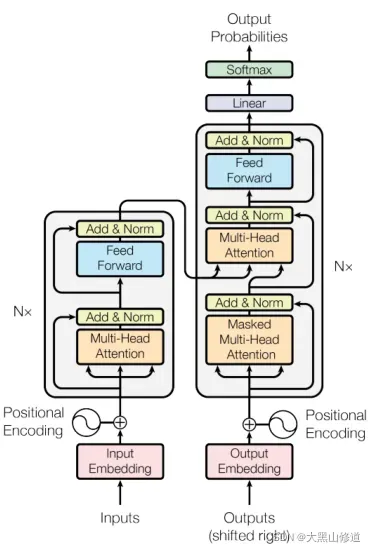
上面,残差连接被添加到编码器和解码器中的每个子层。这增强了信息流以获得更高的性能。在剩余连接之后执行层规范化。这些操作的输出可以描述为:
这里,X用作自我关注层的输入,并且查询、关键字和值矩阵Q、K和V都从相同的输入矩阵X导出。对于归一化层,存在诸如批归一化[107]之类的若干备选方案。批量归一化(batch normalization)在应用于Transformer时通常表现较差,因为特征值变化很大[198]。还提出了一些其他归一化算法[249]、[198]、[5]来改进Transformer的训练。
[107]:Batch normalization: Accelerating deep network training by reducing internal covariate shift. InICML, 2015.
[198]:Powernorm: Rethinking batch normalization in transformers.PMLR, 2020.
[249]:Understanding and improving layer normalization. NeurIPS, 2019.
[5]:Rezero is all you need: Fast convergence at large depth.arXiv preprint arXiv:2003.04887, 2020.
2.2.2 Feed-Forward Network 前馈网络
在每个编码器和解码器中的自我注意层之后应用前馈网络(FFN)。它由两个线性变换层和其中的一个非线性激活函数组成,可以表示为以下函数:
其中W1和W2是两个线性变换层的两个参数矩阵,σ表示非线性激活函数,如GELU。隐藏层的维数为dh=2048。
2.2.3 Final Layer in the Decoder 解码器的最后一层
解码器的最后一层用于将向量堆栈转换回一个字。这是由线性层和softmax层实现的。线性层将向量投影到具有dword维度的logits向量中,其中dword是词汇表中的单词数。然后使用softmax层将logits向量转换为概率。
当用于CV任务时,大多数变压器采用原始Transformer的编码器模块。这种Transformer可以被视为一种新型的特征抽取器。与只关注局部特征的CNN相比,transformer可以捕捉远距离特征,这意味着它可以轻松地获取全局信息。与RNN相比,transformer的效率更高,因为自关注层和完全连接层的输出可以并行计算,并且易于加速,所以RNN的隐藏状态必须按顺序计算。由此,我们可以得出结论,进一步研究在计算机视觉中使用transformer以及NLP将产生有益的结果。
以下章节见:Transformer综述(A Survey on Vision Transformer) 阅读学习笔记(二)
3. VISION TRANSFORMER 视觉Transformer
3.1 Backbone for Representation Learning 表征学习的主干网
3.1.1 Pure Transformer 纯Transformer
版权声明:本文为博主大黑山修道原创文章,版权归属原作者,如果侵权,请联系我们删除!