论文链接:https://arxiv.org/pdf/1606.09549.pdf
论文代码:复制
摘要:传统上,任意目标跟踪的问题是通过专门在线学习目标外观的模型来解决的,使用视频本身作为唯一的训练数据。尽管这些方法取得了成功,但他们的纯在线方法固有地限制了他们可以学习的模型的丰富性。最近,有人试图利用深层卷积网络的表达能力。然而,当要跟踪的目标事先未知时,需要在线执行随机梯度下降以适应网络的权重,这严重影响了系统的速度。在本文中,我们在ILSVRC15数据集上为视频中的目标检测配备了一个基本的跟踪算法和一个新的端到端训练的孪生神经网络。我们的跟踪器以超过实时的帧速率运行,尽管极其简单,但在多个基准测试中实现了最先进的性能。
1. 论文精华
1.1 Introduction
在单目标跟踪任意物体的问题中,物体只被第一帧框住,后续的跟踪通过算法完成。由于可能需要该算法来跟踪任意对象,因此不可能收集数据并训练特定的检测器。
最近的几项工作旨在通过使用预训练的深度卷积网络来克服这一限制,该网络是为一项不同但相关的任务学习的。这些方法要么应用“浅层”方法(如相关滤波器),将网络的内部表示作为特征,要么执行SGD(随机梯度下降)来微调网络的多层。各有利弊,使用浅层方法无法充分利用端到端学习,应用SGD以获得最先进结果的方法无法实时运行。
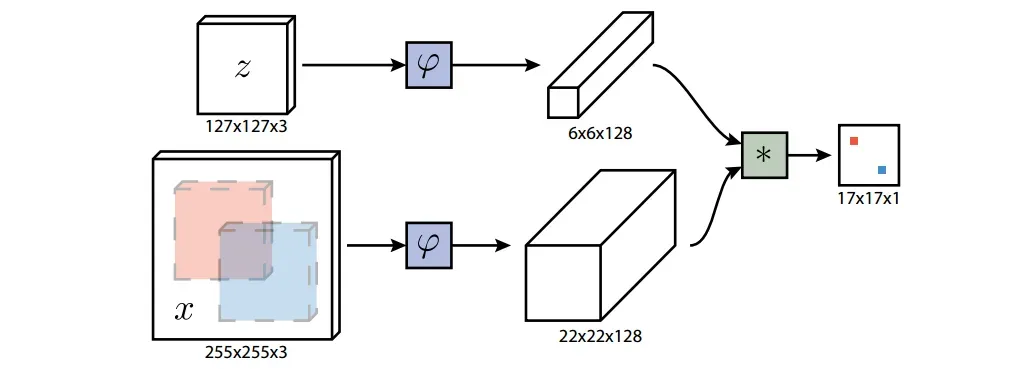
我们提倡另一种方法,即在初始离线阶段训练一个深度卷积网络来解决更普遍的相似性学习问题,然后在跟踪期间简单地在线评估函数。本文的主要贡献是证明这种方法在现代跟踪基准上实现了非常有竞争力的性能,远远超过了帧速率要求。具体来说,我们训练了一个连体神经网络来在更大的搜索图像中定位样本图像。另一个贡献是与搜索图像完全卷积的新连体结构:通过计算两个输入的互相关的双线性层实现密集且高效的滑动窗口评估。
我们认为,相似性学习方法已相对被忽视,因为追踪社区无法访问大量标记的数据集。事实上,直到最近,可用的数据集只包含几百个带注释的视频。然而,我们认为,用于视频中目标检测的ILSVRC数据集[10](此后称为ImageNet视频)的出现,使训练这样一个模型成为可能。此外,train和test使用同域视频进行跟踪的深度模型的公平性是一个争议点,VOT委员会最近禁止了这种做法。我们的模型从ImageNet视频域推广到ALOV/OTB/VOT域,使得跟踪基准的视频可以用于测试。
1.2 用于跟踪的深度相似性学习
使用相似性学习可以解决学习跟踪任意对象的问题。我们建议学习一个函数,该函数将样本图像z与相同大小的候选图像x进行比较,如果两个图像描述相同的对象,则返回高分,否则返回低分。为了在新图像中找到物体的位置,我们可以彻底测试所有可能的位置,并选择与物体过去外观最相似的候选位置。在实验中,我们将简单地使用对象的初始外观作为示例。函数f将从带有标记对象轨迹的视频数据集中学习。
整体可以用这个公式表示:
当函数g是一个简单的距离或相似性度量时,函数可以被视为嵌入
1.3 全卷积孪生网络结构
使用卷积嵌入函数,使用互相关层组合输出特征图
我们采用了一种判别性方法,对网络进行正负配对训练,并采用logistic loss作为损失函数。
2. 说人话环节
2.1 单目标跟踪
单目标跟踪中,通常对第一帧待跟踪目标框出来,算法后续自动框出当前帧目标。SiamFC就是属于这种。
2.2 网络结构
- 首先,对于第一帧的待跟踪目标,我们在目标中心将其crop出来,得到
的search image和
的exemplar image。
- 网络仅有一个backbone,即不要全连接层的Alexnet。当Alexnet输入图像为
;当Alexnet输入图像为
。因此网络是分两次分别输入search image和exemplar image。这也就是文章所说的权值共享,根本上就只有一个网络。
- 对于得到的search image的特征图和exemplar image的特征图,进行互卷积操作。我们都知道,卷积操作就是利用卷积核去提取和自己相似的特征,是一个模板匹配的过程,而当卷积核为exemplar image时,那其意义就变成了:在图像中找到和自己相似的区域,提取出来。
- 卷积后得到
的特征图,称为响应图。卷积后,如果区域与自身非常相似,则数值上会更大。如果两个区域描述的是同一个对象,那么得分就会很高。 ,否则为低分。然后我们可以将这个特征图上的最大值映射到原始图像上,从而找到要跟踪的目标并对其进行构图。
2.3 数学描述
- 网络提取特征:我们得到search image和exemplar image后,用
表示exemplar image,用
表示search image,用
表示网络Alexnet,数学表示为
- 互卷积操作:对特征图进行互卷积操作,
为卷积核,
为卷积图。卷积用
表示,输出响应图用
表示,数学表示为
- 响应图调整:在卷积之后为了让loss function得到更高的值,在输出响应图之后,统一调整响应图的大小。当特征图统一乘以或加上某一个数时,对预测响应图中的最大值没有影响,但是对loss的计算——这是作者的原话。数学表示为
即响应图同时乘以一个数,同时加上一个数
,对输出结果做压缩或放大。在代码中,这里的
和
则用
的卷积核实现,即input_channels=1,output_channels=1,stride=[1,1],没有padding。初始化时,将卷积核的值初始化为1e-3,bias初始化为0,即
,
。这也是原文的设置方法。
2.4 网络结构——pytorch实现
class SiamFCNet(nn.Module):
def __init__(self, cfg):
super(SiamFCNet, self).__init__()
self.fea_extract = Backbone(cfg)
self.xcorr = XCorr()
self.adjust = nn.Conv2d(1, 1, kernel_size = (1, 1), stride = (1, 1))
def forward(self, x):
img_x, img_z = x
# 1. 网络提取特征
fea_z = self.fea_extract(img_z)
fea_x = self.fea_extract(img_x)
# 2. 互卷积操作
score_map = self.xcorr(fea_x, fea_z)
# 3. 响应图调整
score_map = self.adjust(score_map)
return score_map
def init_weights(self):
for idx, m in enumerate(self.modules()):
if isinstance(m, nn.Conv2d):
tmp_layer_idx = idx + 1
if tmp_layer_idx < 6:
nn.init.kaiming_normal_(m.weight.data, mode = 'fan_out', nonlinearity = 'relu')
else:
# 4. 初始化adjust layer
m.weight.data.fill_(1e-3)
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
class XCorr(nn.Module):
def __init__(self):
super(XCorr, self).__init__()
def forward(self, fea_x, fea_z):
N, C, H, W = fea_x.shape
fea_x = fea_x.view(1, -1, H, W)
score_map = F.conv2d(fea_x, fea_z, groups = N)
return score_map.transpose(0, 1)
3. 复现细节及注意事项
3.1 数据处理阶段:
- search image和exemplar image是从物体中心提取出的,需要在训练时通过groundtruth提取出图像中的目标。此网络是为了得到两张图片的相似情况,因此目标类别可以忽视。
- exemplar image为[127, 127, 3]大小,search image为[255, 255, 3]大小。
- 如何crop出exemplar image:crop目标前,我们有目标当前帧image和bbox。
- 根据bbox得到目标中心cx,cy,长宽w,h
- 根据公式
- 从cx,cy处中心裁剪,其中
,
表示目标crop出的size
- 将crop出的图像resize到127*127的大小,那么s表示缩放因子,
- 先计算,后crop,再resize,若超出图像边界,填充各通道平均值
- 如何crop出search image:crop目标前,我们有目标当前帧image和bbox,以及缩放因子s
- search image最终需要resize到255*255,为了保持缩放比例一致,因此有
,那么search image需要crop的size为
- 先计算,后crop,再resize,若超出图像边界,填充各通道平均值
3.2 训练阶段
loss采用pytorch中带权重的BCEWithLogitsLoss,并除以batch size,个人理解除以batch size是为了控制反向传播的大小。loss输入为网络输出的score map和label。
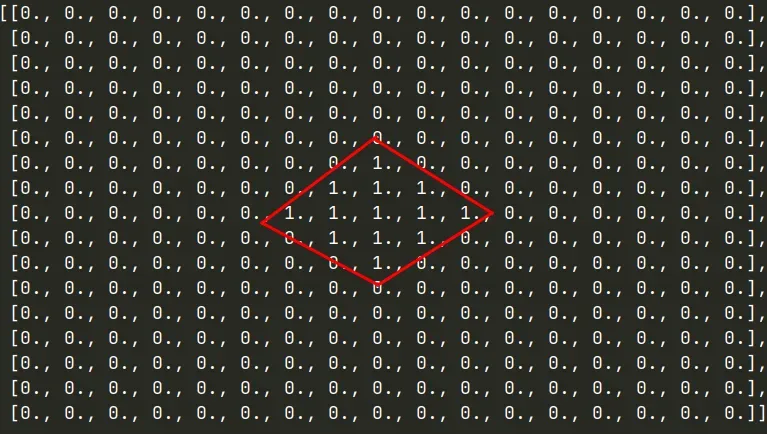
label输出如下:
重量输出如下:
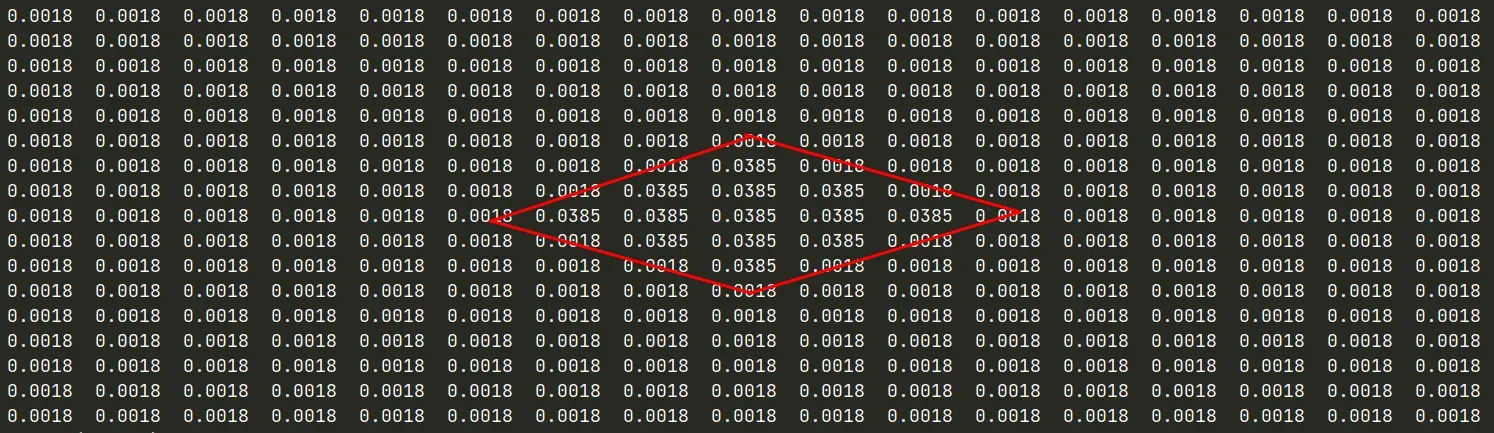
响应图输出类似于以下内容:
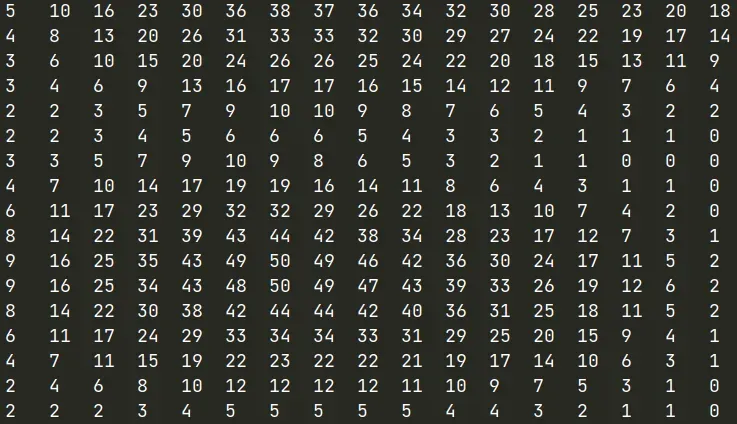
或类似的东西:
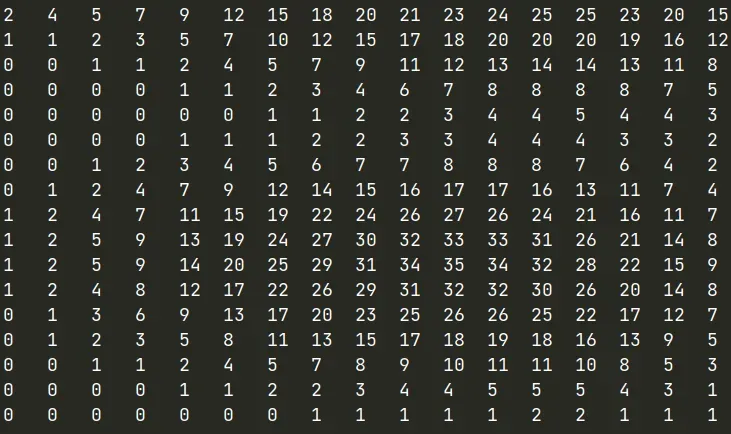
看得到
- label只在中心出现,这是由于我们的图像都是从目标中心crop的
- 带权重的loss保证loss兼顾正负样本
- 输出响应图显示有不同的响应区域,值越高,目标出现的可能性越大。
3.3. 跟踪阶段
3.3.1 响应图上采样
跟踪阶段需要将得到的响应图映射回272272大小的响应图,采用双三次插值方法。问:为啥不映射到255255的大小?
We found that upsampling the score map using bicubic interpolation, from 17 × 17 to 272 × 272, results in more accurate localization since the original map is relatively coarse
因为输出响应图比较粗糙的缘故,我们发现,将响应图利用双三次插值方法上采样到272*272可以获得更精确的定位
3.3.2 图像金字塔
在跟踪时,为了处理比例变化,搜索五个比例的search image,即得到search image的crop size后,搜索五个比例的search image
即一共有五个音阶
3.3.3 连续跟踪
- 第一帧手动框出图像后,得到第一帧的exemplar image,在后续的论文中也叫做模板。

- 根据上一帧的物体的cx,cy和w,h,得到当前帧的多个尺度的search image

- 将search image和exemplar image送入网络,得到响应图
- 根据响应图的响应位置,改变cx,cy,w,h沿用上一帧,这样第二帧的cx,cy,w,h都有了

- 重复2-4步骤
4. 优点和不足
4.1优点
- 将跟踪方法从以往的在线更新网络参数,转变为一对图片的相似性比较问题,siamese network in VOT的开山之作!!!!!!!!!!!!!!!!!!!!!!!!!!!
- 快速跟踪,全卷积网络,轻量级
- 端到端跟踪
4.2 不足
- 模板仅用第一帧,未更新模板。时间尺度下由于光照、畸变、角度等原因,目标会发生变化(DSiam、UpdateNet等后续论文正在做的事)
- 跟踪边框大小仅用第一帧,未更新w,h。由于目标离摄像头的远近,目标的大小也会发生变化。
- 网络得到的响应图还需要自己上采样并得到cx,cy,能不能用统一的框架直接输出目标和边框(siamFC++、SiamRPN等后续论文正在做的事)
- 采用图像金字塔,运行慢,在目前的技术看来,能不能采用特征金字塔方式(C-RPN、SiamRPN++等后续论文正在做的事)
5. 发展
从现在看来,后续的论文依据此范式,在模板更新、网络一体化、以及加入anchor based、anchor free方法、提高网络提取特征能力上都做足了改进。并且仍然有很大的发展空间。
版权声明:本文为博主Matorch原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_43913124/article/details/123403727