本系列的上一篇博文最后提出了一个问题,是有关如何通过torch来实现给定的神经网络的,这里公布一下我自己的回答:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.layer12 = nn.Linear(784, 200)
self.layer23 = nn.Linear(200, 100)
self.layer34 = nn.Linear(100, 10)
def forward(self, input):
output = self.layer12(input)
output = torch.relu(output)
output = self.layer23(output)
output = torch.relu(output)
output = self.layer34(output)
output = nn.functional.softmax(output)
return output
是不是感觉很简单?不用担心,构建神经网络很容易,但是训练其中的参数非常麻烦。
此篇博文将以sklearn中的手写数字图像作为数据集,来讲述一个神经网络是如何训练和测试的。
介绍数据集
Python scikit-learn库中有一个datasets模块,此模块中收录了很多经典的训练模型用到的数据集,mnist(手写数字图像,分辨率8*8)便是其中之一。本篇博文便是基于此数据集对图片中的手写数字进行识别和分类,此数据集是神经网络初学者的必经之路。
加载这些数字图像的方式非常简单,具体见以下代码:
def preprocess_digit():
data = load_digits()
x, y = data.data, data.target
## Input Normalization
x = MinMaxScaler().fit_transform(x)
return train_test_split(x, y, test_size=0.1)
一般来说,在训练分类型神经网络模型时,输入的数据是要进行标准化的,这在以上代码中的“x = MinMaxScaler().fit_transform(x)”有所体现。本人在此之前未对数据进行标准化的预处理,造成了训练时参数的爆炸…(沉痛的教训,宝贵的经验)
调用上述函数并执行以下代码获取相关数据集的信息:
xtrain, xtest, ytrain, ytest = preprocess_digit()
print(xtrain.shape)
print(xtest.shape)
print(ytrain.shape)
print(ytest.shape)
这段代码可以检查数据量的大小:
说明训练集数据有1617张图像,测试集有180张图像,所有图像的大小为88,但是载入的数据是164的行向量。
神经网络的构建
之前讲过这种代码怎么写,不多说,直接上代码:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.layer12 = nn.Linear(64, 50)
self.layer23 = nn.Linear(50, 25)
self.layer34 = nn.Linear(25, 10)
def forward(self, input):
output = self.layer12(input)
output = torch.relu(output)
output = self.layer23(output)
output = torch.relu(output)
output = self.layer34(output)
output = nn.functional.softmax(output)
return output
培训过程
这里通过实例代码来阐述torch是如何进行网络的训练的,首先先贴出我训练成功时所用的代码:
def train():
network = Net()
optimizer, loss_func = optim.SGD(network.parameters(), lr=0.5), nn.MSELoss()
for epoch in range(len(y_train)):
x = Variable(torch.tensor(x_train[epoch], dtype=torch.float32)).reshape([1, 64])
y = torch.zeros([1, 10])
y[0, y_train[epoch]] = 1.0
for i in range(10):
prediction = network(x)
loss = loss_func(prediction, y)
optimizer.zero_grad() ## Clear to zero for the devitation of loss(loss-weight)
loss.backward()
optimizer.step()
逐行:
- 此Python函数中第一行的“network = Net()”表示建立一个Net类的对象,Net就是之前定义的此神经网络的类,继承于父类nn.Module;
- 语句optim.SGD(network.parameters(), lr=0.5)表示我们定义了一个优化器optimizer,并采用随机梯度下降法优化模型参数,设置每一层网络参数优化时的学习率为0.5。optim是torch中的模块,专门用于优化学习模型中的参数的,SGD是“随机梯度下降”的英文简写。此时我们设置SGD方法中的两个参数:(1)待优化的对象(network.parameters(),.parameters()表示取其网络参数);(2)学习率learn_rate(简写为lr)。
- 语句nn.MSELoss()意思是指定网络的损失函数loss_func为均方差(MSE)损失函数;
- 接下来便是两层循环,本人在此训练的逻辑是:对于每一个训练数据集中的样本,都送入网络中进行随机梯度下降法的训练,每个样本反复进行10次BP算法;
- 外层循环中有三句话,这三句话的含义分别为:(1)将每一个到来的样本输入转化为torch型张量(torch.Tensor),并将其维度调整为一个长度为64的行向量(此处可依据实际情况,判断是否需要维度调整);(2)后两句话含义是,针对此数据的标签Label,制作一个标准输出向量y,此向量将在内层循环中参与计算生成损失函数loss。
- 语句prediction = network(x),表示把x作为变量输入网络Net对象network中,最终得到的输出向量作为预测变量prediction;
- 语句loss = loss_func(prediction, y)声明loss函数与prediction和y有关,其作用和Loss的定义式
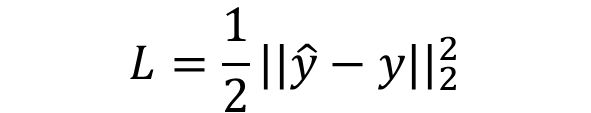
相当,等效于在此定义了Loss函数的形式。(yhat意思是y的估计,Loss函数是y估计与y差值的二范数平方)
- 语句optimizer.zero_grad()意思是将优化器中的梯度清零,因为每开始此BP算法,网络的初始梯度都是0;
- 语句loss.backward()意思是执行反向传播过程,在之前定义的model类里,我们只定义了前向传播过程forward,此时反向传播过程backward就已经确定了,所以无需自己再去定义(除非网络有特殊需要);
- 语句***optimizer.step()意思是开始一次迭代优化的步骤***。之前的过程都只是自定义训练的步骤,而非真正让机器执行,只有当调用optimizer.step()之后,程序才会开始优化,否则等于没干。
以上便是利用torch训练一个神经网络的相关步骤,在数据集很大的情况下,训练的步骤耗时很大,建议程序运行时做点别的事~
保存网络参数
保存网络参数很简单,直接上代码
if not os.path.isdir('model'):
os.mkdir('model')
torch.save(network, './model/full_connected.cpkt')
代码的逻辑很容易看懂,当model文件夹不存在时,创建model文件夹,然后在这个文件夹里面保存网络参数。
torch.save()可以保存的参数种类有很多,除了上面代码里面的类类型network以外,还有torch.Tensor、字典、参数列表network.parameters()等。
网络参数保存为文件后,再次使用时需要使用以下代码读取模型参数:
network = torch.load('./model/full_connected.cpkt')
network.eval()
也很容易理解,在torch.load中添加文件的路径即可,但是你事先要知道这个文件中存储的参数类型,并且要用正确的变量类型来接收参数读取的结果。
模型测试
直接给代码:
for epoch in range(len(y_test)):
x = Variable(torch.tensor(x_test[epoch], dtype=torch.float32)).reshape([1, L])
prediction = network(x)
max = torch.max(prediction).detach().numpy()
if max == prediction[0, y_test[epoch]].detach().numpy():
count += 1
print("The accuracy of the testSet(%s) : %2.2f\n" % (set, (count/len(y_test))))
和训练时的做法类似,只是此时没有了反向传播步骤,当我们得到最终的预测向量prediction作为输出时,prediction中最大元素所在的下标便是预测的结果,例如,如果最大元素所在下标为8,则程序识别出来的数字是8。prediction是一个长度为10的向量,原因就是0~9包含了10个数字,prediction本质上存储的是每个数字被识别的概率,其中概率最大的就是机器识别的结果,这是神经网络用于分类问题时普遍采用的策略。
显示结果



上图给出了一个识别正确号码的例子。
这里打印的是模型识别数字的准确率,可以发现,识别的准确率还算可以,由于本人在这里采用的是随机梯度下降法进行参数更新,所以网络有点过拟合。一般的情况下,在训练网络时都是优先采用批量梯度下降(BGD)法进行网络训练,这里只是做训练的简单演示,所以未考虑此问题。
代码集成
所有与全连接前馈神经网络有关的代码都在下列的Gitee链接中,本人在今后还会向此代码库增加与神经网络相关的内容。
神经网络代码Gitee链接
题
如果要使用神经网络进行非线性回归,代码应该怎么写?你有一个大概的想法吗?
版权声明:本文为博主Donald_Shallwing原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/Donald_Shallwing/article/details/123450830