如果觉得我的算法分享对你有帮助,请关注我的微信公众号“圆圆的算法笔记”,更多算法笔记和世界万物的学习记录~
在推荐系统中,经常需要进行用户对某商品的点击率预测,来给用户推荐最有可能感兴趣商品。这其中需要用到很多特征,例如商品特征、用户特征、上下文特征等。这其中,用户历史行为序列是一个重要特征,经过很多场景的验证,用户历史行为序列会对模型效果带来较大提升。用户历史行为序列,指的是用户历史曾经点击过的商品,按照点击的时间顺序组成的序列。本文汇总了8篇推荐系统中对用户历史行为序列建模的方法,包括DIN、DIEN等经典模型。
1. DIN系列
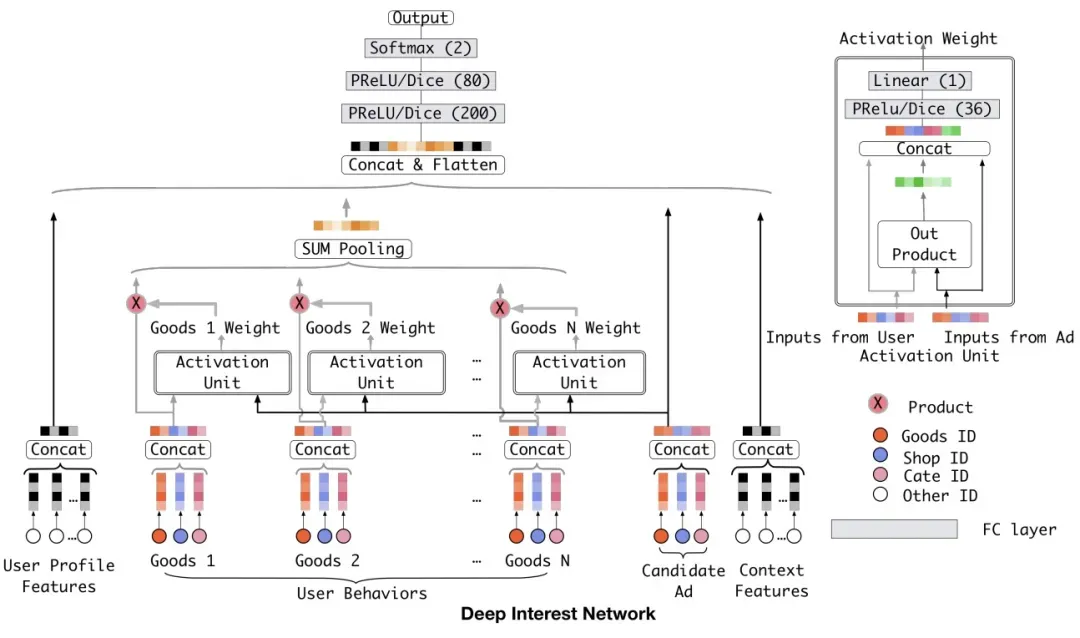
在CTR预估任务中,用户的历史行为序列(例如电商中场景中,一个用户在历史浏览中点击了哪些商品)对于提升预估效果有很大帮助。一种简单的引入用户历史行为的方法为,将用户历史浏览过的商品的embedding进行pooling(例如历史浏览过10个商品,求这10个商品对应embdding的均值)作为特征输入到模型中。Deep Interest Network for Click-Through Rate Prediction(KDD 2018)提出一种基于Attention的用户历史行为序列引入方法,利用当前候选广告去历史浏览过的中查找相关的兴趣商品。具体方法为,利用当前ad的特征和历史每个浏览item的特征做attention计算得分,再用该得分对历史每个浏览item的embedding进行带权重的pooling。相比直接pooling,这种基于attention的pooling方式能够根据当前广告激活历史相关的用户行为,效率更高,且相比pooling每个广告下用户历史行为这一维特征都相同,DIN的方法使每个广告对应生成不同的用户历史行为特征。相比以往的模型需要用一个固定的向量表达用户所有的兴趣,DIN通过兴趣激活模块根据具体的候选广告表达用户与此次预测相关的兴趣,这样的设计降低了模型表达用户兴趣的难度。此外,文中提出DIN的attention不使用softmax归一化,而是用非归一化的值代表用户对当前广告的兴趣大小,因为如果一个用户历史行为90%都是衣服,10%是电子产品,那么如果当前广告是和衣服相关的,激活的信息就多,对应的兴趣绝对值也应该更大。
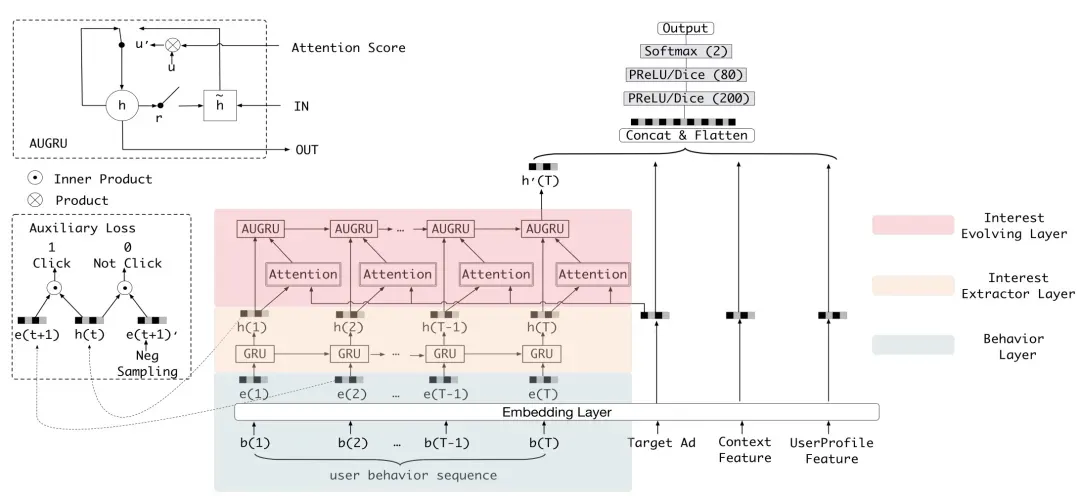
Deep Interest Evolution Network for Click-Through Rate Prediction(AAAI 2019)提出DIEN,对DIN的不足进行了改进。首先,DIN中直接利用历史行为的商品ID作为全部信息输入,但是商品ID只是表象,背后蕴含着品牌、类目等隐性信息,只用商品ID的表象信息是不足的,需要提取内在的隐性信息更充分理解用户历史行为。其次,DIN中提出序列建模(如RNN建模历史行为序列)效果不好,这其实是因为历史行为序列的随机性较大,消费者在电商平台看到的东西同时属于多种类型,序列中不同类型的节点跳变随机性强。而如果能直接筛选出和当前待预测点击率的广告相关的历史行为组成新的序列,那么就能更清晰的描述出用户在这个类型兴趣下的行为演变。
本文的整体结果为采用GRU对用户的历史行为进行编码,每个时间步会产生该消费者对应时间点的兴趣隐状态表示。针对第一个问题,文中引入了一个辅助loss来更好的学习每个时刻的隐状态表示。由于模型预估的是ctr任务,所以在生成每个时间步的状态的时候很难让这个状态表示完全反映用户兴趣。因此DIEN让每个时间步的状态预测下一个时间步会点击哪个商品,同时用非点击商品作为负样本。这相当于约束了每个时间步的状态表示要包含用的兴趣,这样才能预测出后续的点击商品。
针对第二个问题,本文使用GRU每个时间步输出的隐状态表示和待预测广告的表示做Attention得到Attention score,这个score反映了哪些状态是和当前广告相关的,筛选掉了不相关的历史行为,减弱不想管历史行为隐藏状态的更新强度,实现了与广告更相关的那些兴趣态能够更大力度的更新演化序列的隐状态表示的目的。具体的模型方面,本文对比了AIGRU(score直接和隐状态表示相乘)、AGRU(score代替GRU中的更新门)、AUGRU(score影响更新门向量)三种方式。DIEN模型结构如下:
2. 多维度提取历史行为信息
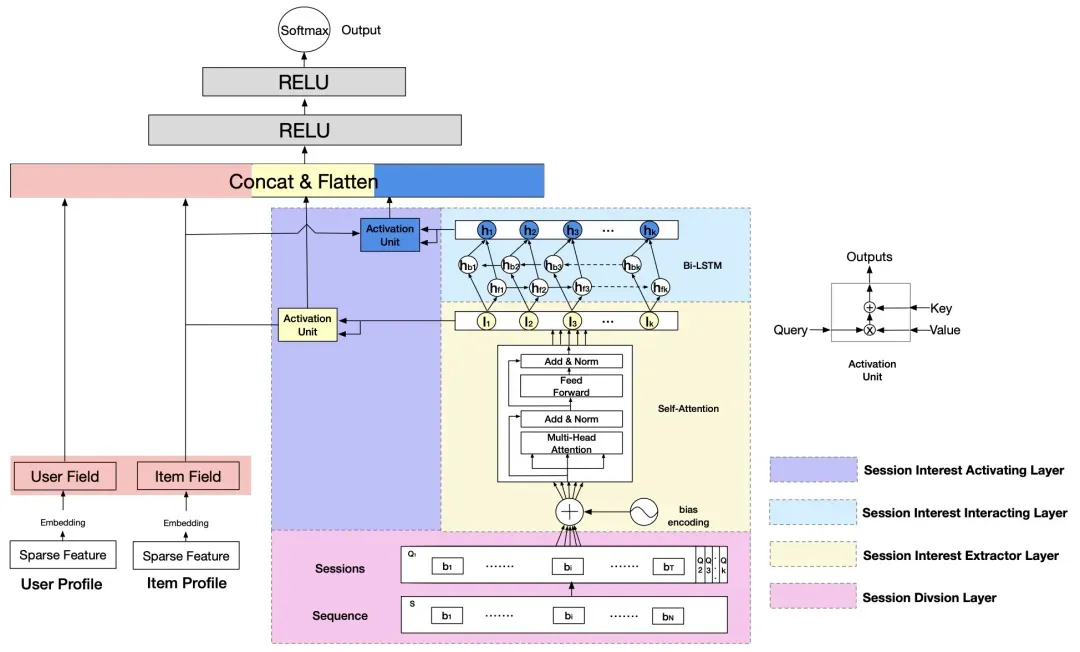
Deep Session Interest Network for Click-Through Rate Prediction(2019)提出了DSIN模型。DSIN的主要思路是利用session的概念,同一个session内部的用户行为往往是更加同质的,而不同session之间的用户行为往往是异质的。因此本文首先将用户的历史行为按照session进行分块,每个session内的用户行为相关性较强,DSIN在每个session内部的历史行为使用Multi-head Attention进行建模,最后求平均得到每个session块的兴趣表示。进一步使用双向LSTM,以每个session的兴趣表示作为输入,对session之间的关系进行建模。最后根据当前的待预测信息使用Attention进行一步对齐操作(类似DIN),最后拼接到其它特征上。DSIN相比DIN的改进主要是对用户历史行为部分的建模更加精细化了,分session建模,得到的每个兴趣的表示更加丰富,而不像DIN只使用商品的ID embedding。
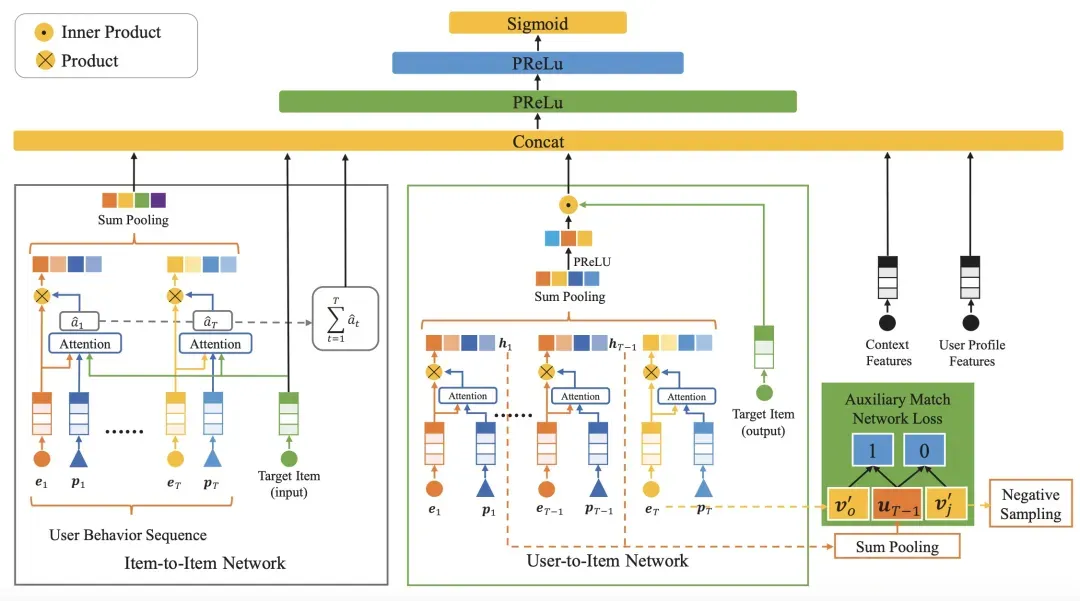
Deep Match to Rank Model for Personalized Click-Through Rate Prediction(AAAI 2020,DRM)提出直接利用历史行为序列建模user-item和item-item关系,核心是user-item network和item-item network。对于user-item network,首先利用Attention对历史行为item序列进行加权pooling得到用户的兴趣表示向量,然后用兴趣表示向量和目标商品计算点积相似度来衡量这个用户和当前item的相关性,使用是否点击作为相关性的label。同时为了让模型训练更容易,在user-item network上增加了一个辅助任务,该辅助任务类似于DIEN中提出的使用历史T-1个行为预测下一个行为(即前面T-1个商品预测第T个商品),也是利用了负采样的方法进行训练。对于item-item network,使用历史行为序列的每个商品和目标商品分别进行Attention计算相似度,然后再加权pooling到一起,从商品角度衡量历史行为和待预测商品的关系。整体来看,DRM实际上是直接从底层的user和item的关系入手,通过引入更多的相关性任务约束user和item的表示学习过程
一些文章提出使用Transformer结构进行用户历史行为序列建模。在BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer(CIKM 2019)中,针对预测每个时刻用户可能感兴趣的商品这个任务,设计了用Transformer代替原来如RNN等单向建模的方法。在训练阶段,BERT4Rec采用了类似于Bert的Mask Language Model的训练方式,从用户行为序列中随机mask掉一些商品,然后用双向信息进行预测。然而,由于在预测阶段是单向预测未来的,这种mask方式导致了训练和预测的不一致性。为了缓解这个问题,本文提出在预测阶段在用户行为序列末尾加上mask符号预测,同时训练阶段也增加一定量的尾部为mask的训练样本,以此缩小训练阶段和预测阶段的gap。
3. 多用户行为序列关系建模
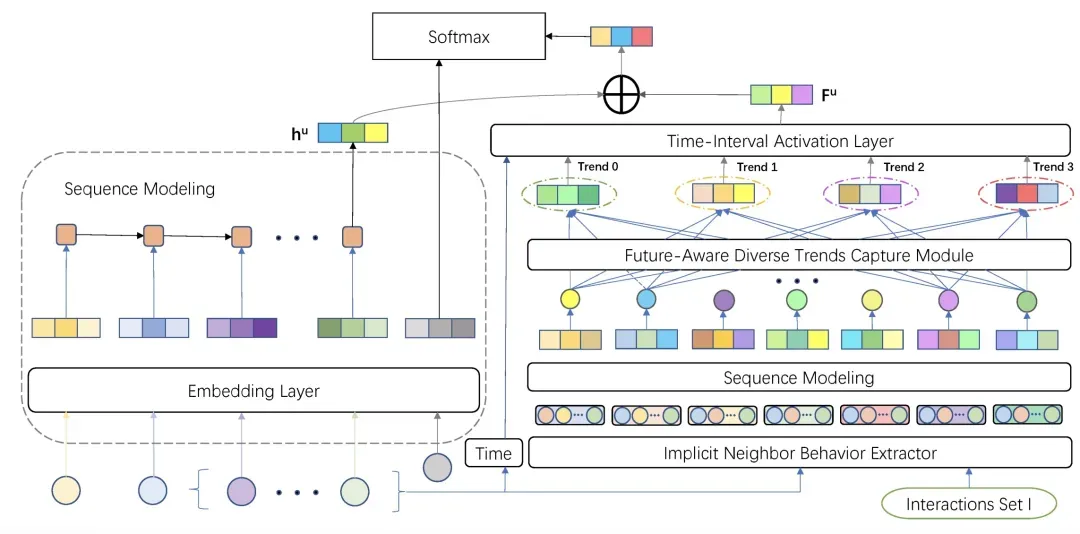
Future-Aware Diverse Trends Framework for Recommendation(WWW 2021)提出除了当前用户的历史行为外,也引入其他兴趣相似的用户的序列辅助预测。具体做法为,对于当前用户,会利用协同过滤的思路(如用户对商品打分的皮尔逊系数)选择一部分和当前用户兴趣接近的其他用户。接下来,获取这些其他用户的历史行为序列,选择查找这些用户的历史行为序列中是否包含当前待打分商品。如果包含,就选取这个商品之后的一段序列,这段序列其实表示了其他类似的用户,当看到当前候选商品后,在未来会继续看哪些商品,这是一个user->user->item的过程,利用user找相似user,再利用相似user找其他相关的商品。通过这种未来行为的序列信息扩展进一步提升预测效果。在对这部分相似用户行为序列的建模中,采用了胶囊网络的方法,将多个相似用户的序列聚类得到多个质心表示,这样相比所有用户用一个向量表示能更丰富的表达出这些相似用户行为序列的信息。
4. 长周期行为序列建模
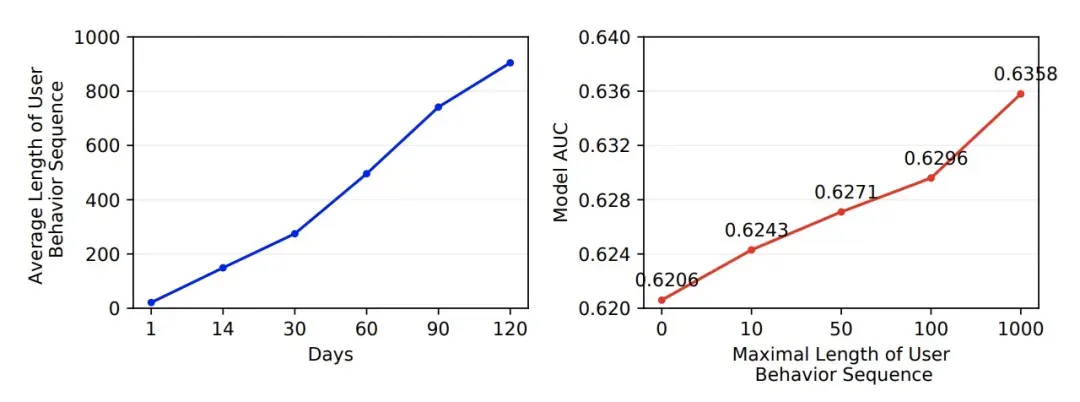
Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction(KDD 2019)介绍了如何进行更长周期的用户行为序列引入。实验首先对比了引入不同长度的用户历史行为序列对模型效果的影响(如下图),发现随着引入序列长度的增加,模型效果会持续提升。而引入更长的历史行为序列会带来较大的存储压力和计算延迟。为了解决这个问题,本文提出了一种基于Memory的长周期用户历史行为序列建模方法,主要包括User Intereset Center和Memory Induction Unit两部分。
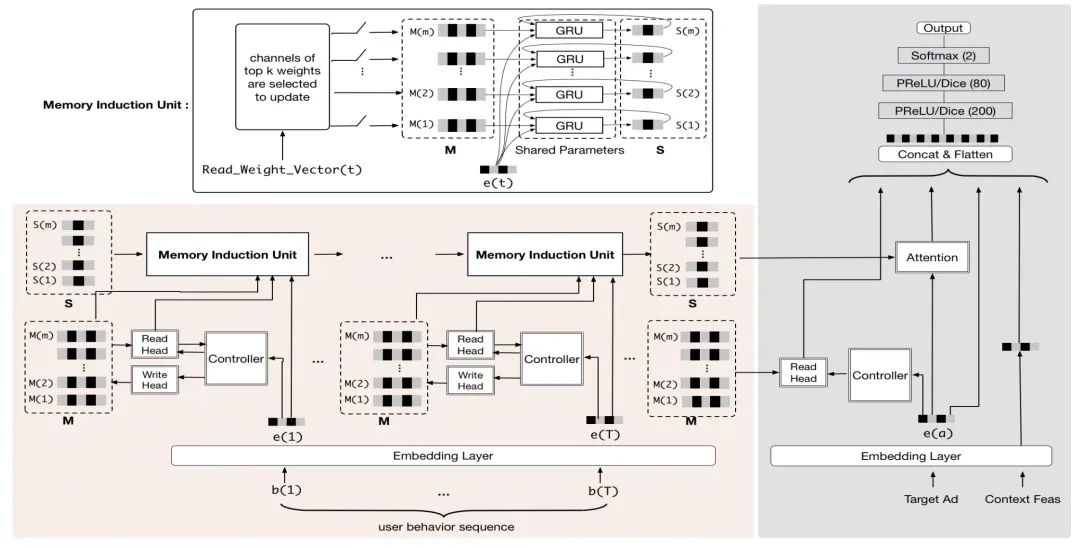
UIC模块主要负责用户行为信息的读和写,采用了Neural Turning Machine的思想。UIC对于每个用户维护一个固定长度的向量,这个向量表示了用户的兴趣信息。UIC模块主要负责维护每个user的兴趣向量,包括读操作和写操作。每个用户的兴趣信息在每个时刻t对应一个矩阵[m, d](memory),这个矩阵包括m个slots,每个slots是一个对应的向量。当t时刻来了一个新的用户行为时,会将该行为对应的embedding经过controller(如一个全连接)输出3个向量,分别对应key(查找)、add(增加)、earase(删除)。对于读操作,会利用key和每个slot进行类似attention的计算,得到各个slots的权重并进行slots的加权求和得到输出;对于写操作,也是同样的方法计算出每个slot写入的attention score,并根据add和earase向量对memory进行更新。
基础的UIC只能对信息进行简单的存储,没有考虑用户历史行为的演化关系,因此本文提出在UIC基础上增加MIU模块对用户历史行为进行建模。具体做法为,MIU也维护一个和UIC类似的memory,首先根据UIC的read操作生成的attention score选择分数最高的几个channel(也就是slot),然后对每个选中的slot使用GRU结合当前行为、memory中的行为进行MIU memory的更新,可以理解为对UIC的基础memory进行了一步高阶信息提取,仍然和UIC类似的方式进行保存。
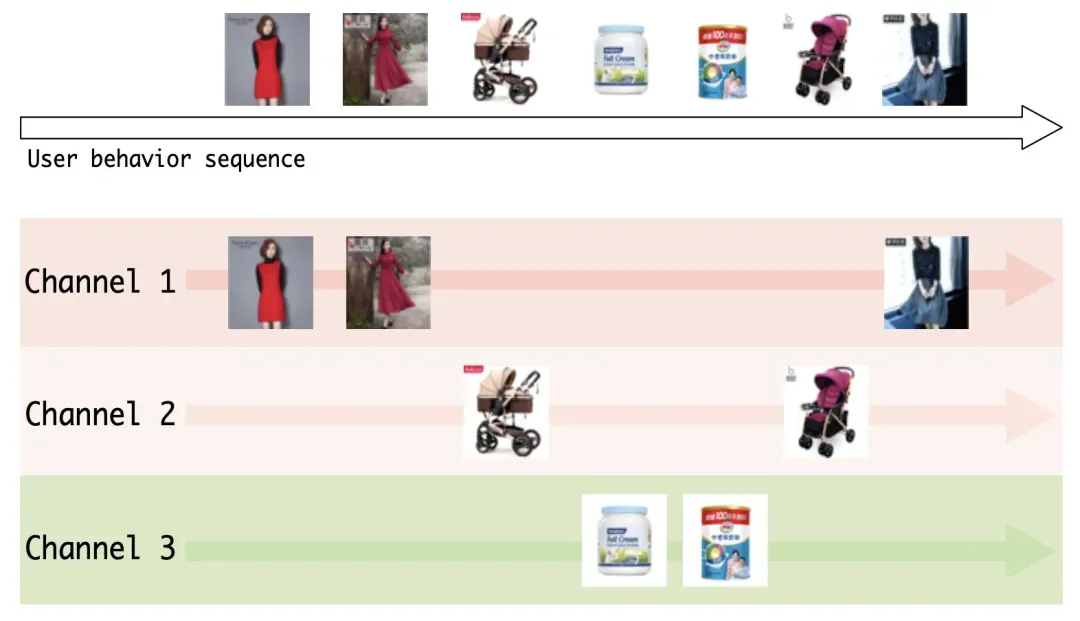
整个过程可以理解为将用户的历史行为根据兴趣类型分成了多个channel(多个slot),并利用GRU对相同类型的slot进行行为序列建模,memory的每个slot就是在记录用户的一组相似历史行为,如下图所示。
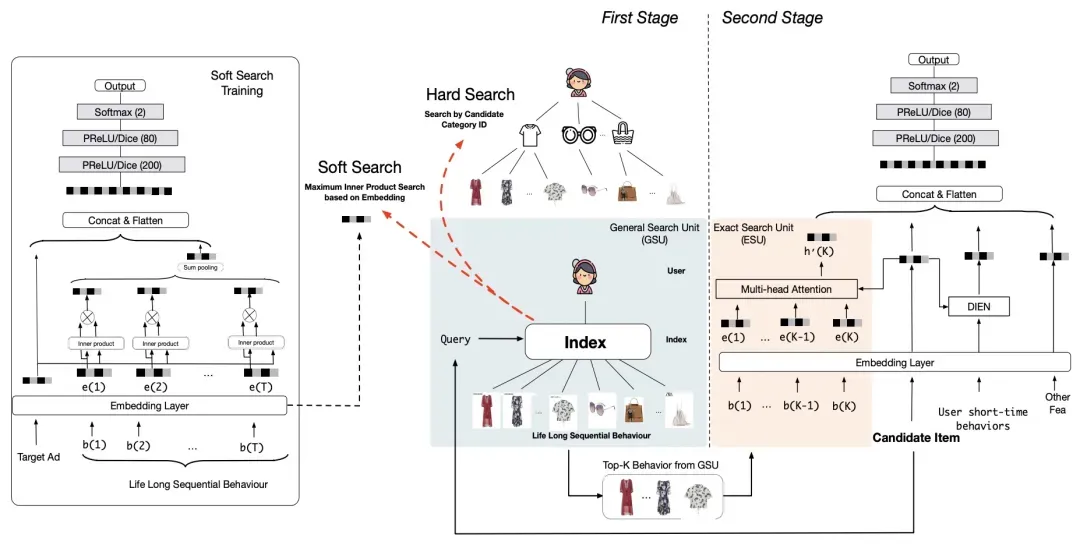
此后,Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction(2020)针对MIMN中无法根据候选商品对超长用户行为序列进行针对性选择的问题进行优化。模型主要包括General Search Unit和Exact Search Unit两个部分,前者用于从长历史行为序列中选出和当前候选商品最相关的几个子序列,后者用于更精细的匹配,可以采用类似DIEN等的方法。对于General Search Unit有hard search和soft search两种。Hard search比较简单,直接选择和候选商品相同类目的历史行为;Soft search采用向量检索的方式计算历史行为和候选商品的匹配分,其中商品向量采用一个辅助CTR任务来学习长期数据和候选广告之间的相关性得到。
5. 总结
本文我们介绍了8篇推荐系统或广告系统中的用户历史行为建模方法。从这些工作来看,attention是主要的模型结构,大部分工作都依赖利用attention从历史行为序列中筛选相关的信息用于预测。同时,用户历史行为序列的长度也在影响其效果,引入越长的历史行为序列,意味着包含的用户信息更多,在合理的建模方法下可以取得更优的效果。除了使用用户本身的行为序列进行建模外,使用一些相似用户的行为序列辅助学习,也会进一步取得不错的效果。
如果觉得我的算法分享对你有帮助,请关注我的微信公众号“圆圆的算法笔记”,更多算法笔记和世界万物的学习记录~
【历史干货算法笔记,更多干货公众号后台查看】
从ViT到Swin,10篇顶会论文看Transformer在CV领域的发展历程
Meta-learning核心思想及近年顶会3个优化方向
12篇顶会论文,深度学习时间序列预测经典方案汇总
一文读懂CTR预估模型的发展历程
Domain Adaptation:缺少有监督数据场景下的迁移学习利器
多任务学习建模方法论文总结
文章出处登录后可见!