1.激活函数
1.1 Sigmoid函数
Sigmoid是常用的非线性激活函数,表达式如下:
- 特点:可以将输入的连续实数值转换为
和
之间的输出。特别是如果是一个很大的负数,输出是
- 缺点:梯度爆炸和梯度消失是在深度神经网络中梯度反向传递时引起的。梯度爆炸的概率很小,而梯度消失的概率比较大。
1.2 tanh函数
tanh 该函数也是非线性函数,其解析公式为:tanh读作Hyperbolic Tangent,解决了Sigmoid函数不zero-centered输出的问题,但梯度消失问题(gradient vanishing)和求幂问题依然存在。
1.3 Relu函数
Relu 该函数实际上是取最大值的函数,其解析公式如下:
- Relu是目前最常用的激活函数,一般搭建人工神经网络时推荐优先尝试
- Relu并非全区间可导,但我们可以取 sub-gradient
- 解决了 gradient vanishing 问题 (在正区间)
- 计算速度很快,只需要判断输入是否大于
- 收敛速度远快于 Sigmoid 和 tanh
- ReLU的输出不是 zero-centered
- Dead ReLU Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。有两个主要原因可能导致这种情况产生: (1) 非常不幸的参数初始化,这种情况比较少见 (2) learning rate 太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。解决方法是可以采用Xavier初始化方法,以及避免将 learning rate 设置太大或使用 adagrad 等自动调节 learning rate 的算法。
1.4 Leaky ReLU函数(PReLU)
函数表达式:
人们为了解决Dead ReLU Problem,提出了将ReLU的前半段设为而非
,通常
。另外一种直观的想法是基于参数的方法,即
,其中
它可以通过定向传播算法来学习。理论上,Leaky ReLU具有ReLU的所有优点,加上Dead ReLU没有问题,但在实践中,并没有完全证明Leaky ReLU总是优于ReLU。
1.5 ELU(Exponential Linear Units) 函数
函数表达式:ELU不会有Dead ReLU问题输出的均值接近、
zero-centered。但是计算量太大,在目前的实际应用中并没有证明它总是优于ReLU。
1.6 UnitStep 阶跃函数
函数表达式:
激活函数一般用于感知器。但是感知器最好通过梯度下降来解决。
2.感知机模型(神经元模型)
设输入空间(特征空间)为,输出空间为
输入是实例的特征向量,输出
是实例的类别
以下从输入空间到输出空间的函数称为感知器:
其中,和
为模型参数,
称为权重,
称为偏差。
是一个符号函数。
假设我们当前的任务是通过感知器对具有维特征的向量进行分类。我们可以将感知器模型视为神经元模型。
维向量(
)对应于神经元的
输入。
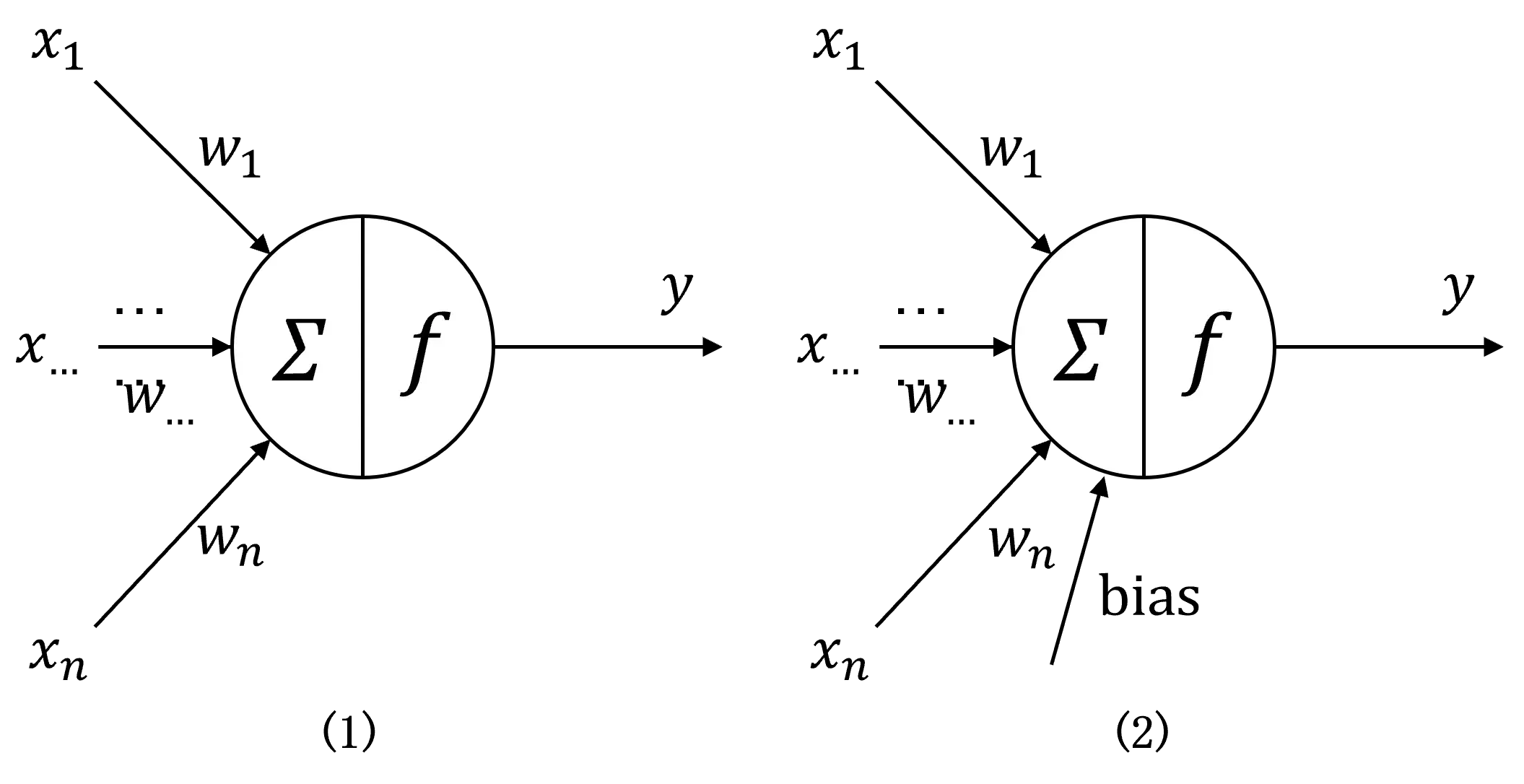
我们将这些输入乘以它们对应的权重并求和,通过激活函数后得到分类结果。
但是,我们注意到当神经网络的输入向量为时,会发生激活失败和错误分类。为了避免这种情况,我们给它加上一个偏置项,然后进入激活函数,也就是感知机模型。
。
我们先将输入向量乘以对应的权重并加上偏置项得到,通过激活函数后与标签进行比较,根据是否等于标签更新参数的值:
其中,为步长,也称为学习率。对所有训练数据进行一次上述过程后,经过一轮训练即可得到
和
。
显然,由于权重参数对应于维特征向量,所以
的维数必然与输入向量的特征维数相关。
这里给出了基于Python实现的感知器模型。
import numpy as np
import matplotlib.pyplot as plt
class ActivateFunction(object):
@staticmethod
def Sigmoid(x):
return (1 / (1 + np.exp(-x)))
@staticmethod
def ReLu(x):
if x <= 0: return 0
else: return x
#return np.max(0, x)
@staticmethod
def Softmax(x):
return np.exp(x) / np.sum(np.exp(x))
@staticmethod
def UnitStep(x):
return 1 if x > 0 else 0
class Perceptron(object):
#初始化一个具有n维特征的感知机
def __init__(self, input_num, activator):
self.activator = activator
self.size = input_num
self.weights = [0.0 for i in range(input_num)]
self.bias = 0.0
#预测值
def Predict(self, input_vec):
return self.activator(np.dot(input_vec, self.weights) + self.bias)
#单轮训练
def SingleIteration(self, input_vecs, labels, rate):
samples = zip(input_vecs, labels)
for (input_vec, label) in samples:
output = self.Predict(input_vec)
delta = label - output
input_vec = np.array(input_vec)
self.weights += rate * delta * input_vec
self.bias += rate * delta
#多轮训练入口
def fit(self, input_vecs, labels, iteration, rate):
input_vecs, labels = np.array(input_vecs), np.array(labels)
for i in range(iteration):
self.SingleIteration(input_vecs, labels, rate)
#获取训练后的得到参数
def GetParameters(self):
return self.weights, self.bias
if __name__ == "__main__":
data, label = [], []
file = open(r'.\Python\x.txt')
for line in file.readlines():
line_data = line.strip().split(',')
data.append([float(line_data[0]), float(line_data[1])])
file.close()
file = open(r'.\Python\y.txt')
for line in file.readlines():
line_data = line.strip().split(',')
label = list(map(int, line_data))
file.close
p = Perceptron(2, ActivateFunction.UnitStep)
p.fit(data, label, 1000, 0.1)
w, b = p.GetParameters()
x1 = np.arange(-5, 10, 0.1)
x2 = (w[0] * x1 + b) / (-w[1])
data = np.array(data)
label = np.array(label)
idx_p = np.where(label == 1)
idx_n = np.where(label != 1)
data_p = data[idx_p]
data_n = data[idx_n]
plt.scatter(data_p[:, 0], data_p[:, 1], color='red')
plt.scatter(data_n[:, 0], data_n[:, 1], color='blue')
plt.plot(x1, x2)
plt.show()
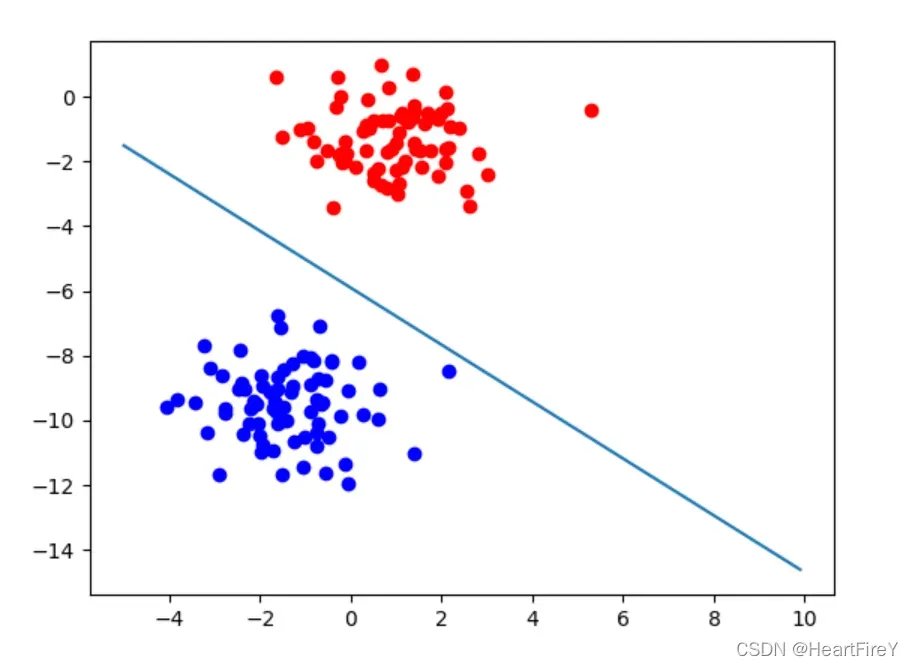
上面显示了分类效果的一个示例。
文章出处登录后可见!