【深度学习】-Imdb数据集情感分析之模型对比(2)-LSTM
前言
【深度学习】-Imdb数据集情感分析之模型对比(1)-RNN
数据集介绍部分见前篇,本文主要讲述LSTM模型的构建。
一、LSTM是什么?
算法介绍
我们之前使用RNN的关键点之一就是他们可以用来连接先前的信息到当前的任务上,例如使用过去的视频段来推测对当前段的理解。同时,这也是RNN最大的不足。另外,虽然RNN程序好写,训练却是非常困难,而且网络是根据输入而展开的,输入越多展开越长,就月有可能回导致梯度消失和梯度爆炸。所以循环神经网络对长短期记忆的要求依然没有达到。
LSTM应运而生,它是一种特殊的RNN类型,可以学习长期依赖信息。LSTM由Hochreiter & Schmidhuber (1997)提出,并在近期被Alex Graves 进行了改良和推广。在很多问题上,LSTM都取得了相当巨大的成功,并得到了广泛的使用。
我们首先来了解一下LSTM(long short-term memory)。长短期记忆网络是RNN的一种变体,RNN由于梯度消失的原因只能有短期记忆,LSTM网络通过精妙的门控制将加法运算带入网络中,一定程度上解决了梯度消失的问题。只能说一定程度上,过长的序列还是会出现“梯度消失”(我记得有个老外的博客上说长度超过300就有可能出现),所以LSTM叫长一点的“短时记忆”。其结构如下: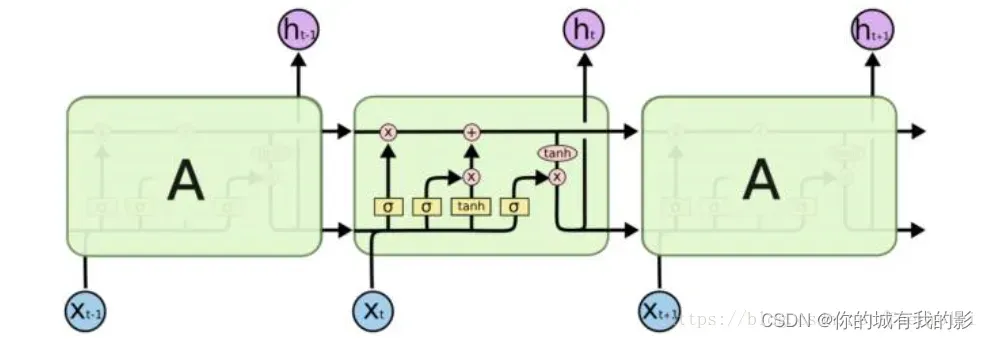
没有详细的描述,我们专注于如何构建它的模型。
二、训练LSTM模型
1.数据预处理
与前文类似,详细请移步【深度学习】-Imdb数据集情感分析之模型对比(1)- RNN
数据预处理部分
2.构建LSTM模型
设置模型参数
max_features = 4000 # 词汇表大小
# cut texts after this number of words (among top max_features most common words)
# 裁剪文本为 maxlen 大小的长度(取最后部分,基于前 max_features 个常用词)
maxlen = 400
batch_size = 32 # 批数据量大小
构建和训练模型
model = Sequential()
# 嵌入层
model.add(Embedding(max_features, 128, dropout=0.2))
# LSTM层
model.add(LSTM(128, dropout_W=0.2, dropout_U=0.2))
model.add(Dense(1)) # 单神经元全连接层
model.add(Activation('sigmoid')) # sigmoid 激活函数层
model.summary() # 模型概述
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
如果想进一步优化模型,可以尝试不同的损失函数和优化器。
训练模型
划分训练集
train_history =model.fit(X_train, y_train, batch_size=batch_size, nb_epoch=10,
validation_data=(X_test, y_test))
开始训练
Epoch 1/10
25000/25000 [==============================] - 729s 29ms/step - loss: 0.4717 - accuracy: 0.7756 - val_loss: 0.3846 - val_accuracy: 0.8360
Epoch 2/10
25000/25000 [==============================] - 757s 30ms/step - loss: 0.4018 - accuracy: 0.8249 - val_loss: 0.3525 - val_accuracy: 0.8562
Epoch 3/10
25000/25000 [==============================] - 722s 29ms/step - loss: 0.3529 - accuracy: 0.8511 - val_loss: 0.3682 - val_accuracy: 0.8457
Epoch 4/10
25000/25000 [==============================] - 727s 29ms/step - loss: 0.3112 - accuracy: 0.8731 - val_loss: 0.3416 - val_accuracy: 0.8574
Epoch 5/10
25000/25000 [==============================] - 735s 29ms/step - loss: 0.2917 - accuracy: 0.8787 - val_loss: 0.3375 - val_accuracy: 0.8654
Epoch 6/10
25000/25000 [==============================] - 774s 31ms/step - loss: 0.2511 - accuracy: 0.8952 - val_loss: 0.2835 - val_accuracy: 0.8844
Epoch 7/10
25000/25000 [==============================] - 770s 31ms/step - loss: 0.1873 - accuracy: 0.9259 - val_loss: 0.2971 - val_accuracy: 0.8794
Epoch 8/10
25000/25000 [==============================] - 733s 29ms/step - loss: 0.1521 - accuracy: 0.9416 - val_loss: 0.3253 - val_accuracy: 0.8796
Epoch 9/10
25000/25000 [==============================] - 729s 29ms/step - loss: 0.1294 - accuracy: 0.9505 - val_loss: 0.3328 - val_accuracy: 0.8786
Epoch 10/10
25000/25000 [==============================] - 732s 29ms/step - loss: 0.1057 - accuracy: 0.9614 - val_loss: 0.3696 - val_accuracy: 0.8832
数据可视化
import matplotlib.pyplot as plt
def show_train_history(train_history,train,validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
show_train_history(train_history,'accuracy','val_accuracy')
show_train_history(train_history,'loss','val_loss')
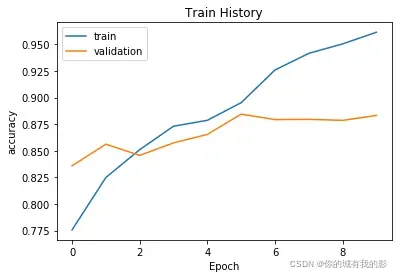
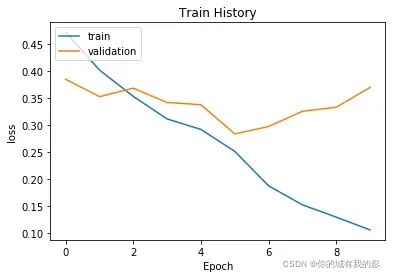
评价模型
score, acc = model.evaluate(X_test, y_test,
batch_size=batch_size)
print('Test score:', score)
print('Test accuracy:', acc)
总结
LSTM模型准确率维持在96.14%,损失率为10.57%,训练时长约为7740s,是几个模型中最慢的。推测可能是对文本进行长短期预测,所以耗时最久,但其一定程度上规避了RNN的梯度消失的问题,准确率得到了提高。
参考
https://blog.csdn.net/keeppractice/article/details/106145451
文章出处登录后可见!