Dropout 的学习笔记,主要参考文章:
- 12种主要的Dropout方法:如何应用于DNNs,CNNs,RNNs中的数学和可视化解释
- 【科普】神经网络中的随机去激活方法
1. 简介
深度学习中训练模型的主要挑战之一是协同适应,这意味着神经元是相互依赖的,即它们相对于输入的独立性不够,而且往往存在预测能力更重要的神经元,这可能是结果,模型将过度依赖单个神经元的输出。
但这种情况应该要避免,权重必须具有一定的分布,从而防止过拟合。通常可以采用正则化的方法来避免过拟合,正则化能调节某些神经元的协同适应和高预测能力。最常用的一种正则化方法就是 Dropout。
Dropout,中文是随机失活,是一个简单又机器有效的正则化方法,可以和L1正则化、L2正则化和最大范数约束等方法互为补充。
接下来将介绍不同的 Dropout 方法,并且在不同深度网络结构上也会有区别,比如在 CNN,还是在 RNN 上:
- 标准的 Dropout 方法
- 标准 Dropout 的变体
- 用在CNNs上的dropout方法:标准的 Dropout 对卷积层的效果并没有很好,原因是因为每个特征图的点都对应一个感受野范围,只是随机丢弃某个像素不能降低特征图学习的特征范围,网络还可以通过失活位置相邻像素学习对应的语义信息;
- 用在RNNs上的dropout方法
- 其他的dropout应用(蒙特卡洛和压缩)
2. 标准的 Dropout 方法
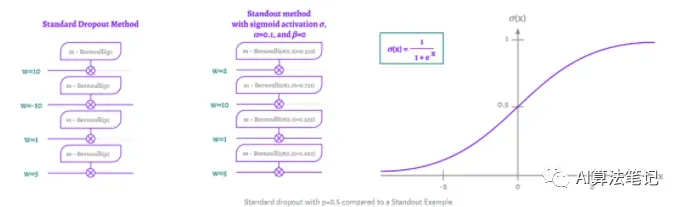
最常用的dropout方法是 Hinton 等人在 2012 年推出的Standard dropout。通常简单地称为“Dropout”,由于显而易见的原因,在本文中我们将称之为标准的Dropout。
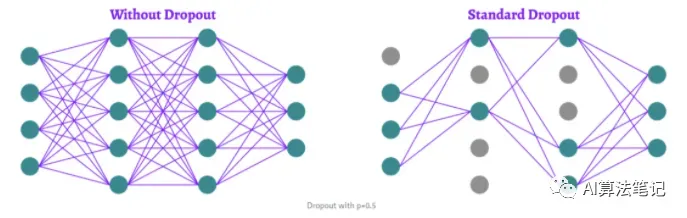
标准的 Dropout 方法主要应用在训练阶段,避免该阶段的过拟合问题,而且通常设置一个概率 p,表示每次迭代中,每个神经元被去掉的概率,如上图所示,设置的 p=0.5。在 Hinton 论文中建议输入层的 p=0.2,隐藏层的 p=0.5,然后输出层是不需要采用 Dropout,毕竟需要的就是输出层的结果。
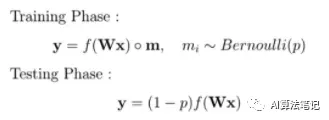
数学上表示如上所示,每个神经元丢弃概率遵循概率为 p 的伯努利分布,所以用一个 mask 对神经元向量进行了一个元素级操作,其中每个元素都是遵循伯努利分布的随机变量。
在训练过程中,Dropout会随机失活,可以被认为是对完整的神经网络的一些子集进行训练,每次基于输入数据只更新子网络的参数。
在测试阶段则是没有采用 Dropout。所有的神经元都是活跃的。为了补偿与训练阶段相比较的额外信息,用出现的概率来平衡加权权重。所以神经元没有被忽略的概率,是“1 – p”。
在论文中,作者通过实验表明了 Dropout 的有效性原因是在两方面:
- Dropout 可以破坏神经元之间的协同适应性,使得在使用Dropout后的神经网络提取的特征更加明确,增加了模型的泛化能力;
- 从神经元之间的关系来说,则是 Dropout 能够随机让一些神经元临时不参与计算,这样的条件下可以减少神经元之间的依赖,权值的更新不再依赖固有关系的隐含节点的共同作用,这样会迫使网络去学习更加鲁棒的特征。
在pytorch中对应的Dropout实现如下:
>>> m = nn.Dropout(p=0.2)
>>> input = torch.randn(20, 16)
>>> output = m(input)
torch.nn.Dropout(p=0.5, inplace=False)
- p– probability of an element to be zeroed. Default: 0.5
- inplace– If set to True , will do this operation in-place. Default: False
对input没有任何要求,也就是说Linear可以,卷积层也可以。
3. Dropout 变体
3.1 DropConnect
L. Wan等人介绍的DropConnect没有直接在神经元上应用dropout,而是应用在连接这些神经元的权重和偏置上。
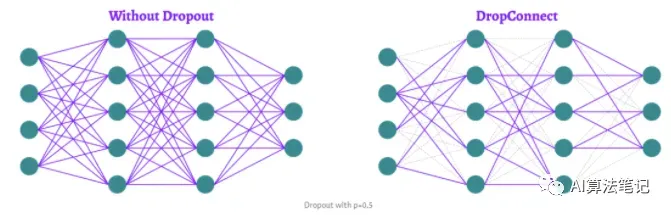
DropConnect 和 Dropout 的区别主要在于使用的掩码是用在权重和偏置,而非神经元本身,此外就是 Dropout 可以用在卷积层和全连接层上,DropConnect 只能用在全连接层,其数学表示如下:
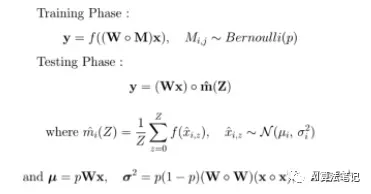
测试阶段也是可以采用和 Dropout 相同的逻辑,即乘以出现的概率,不过在DropConnect 论文中采用的是一个有趣的随机方法,使用 DropConnect的高斯近似。然后由从这个高斯表示中随机采样样本。
3.2 Standout
L. J. Ba和B. Frey介绍的Standout是一个标准的Dropout方法,基于一个Bernoullimask(这是根据它们遵循的分布来命名这些mask,这样会更简单)。不同点在于神经元被遗漏的概率 p 在这一层中并不恒定。根据权重的值,它是自适应的。

这里可以采用任何一个 g 激活函数,或者是一个单独的神经网络。类似地,对于 Ws ,也可以是一个 W 的函数,然后在测试阶段再根据存在的可能性进行平衡。
一个例子如下:
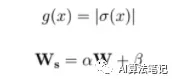
如下图所示,权重越大,神经元被丢弃的概率就越高,这会在一定程度上限制部分神经元的高预测能力。
3.3 Gaussian Dropout
举几个例子,Fast Dropout,变分Dropout或Concrete Dropout是从贝叶斯角度解释Dropout的方法。具体地说,我们没有使用伯努利mask,而是使用了一个mask,它的元素是遵循高斯分布的随机变量**(**正态分布)。
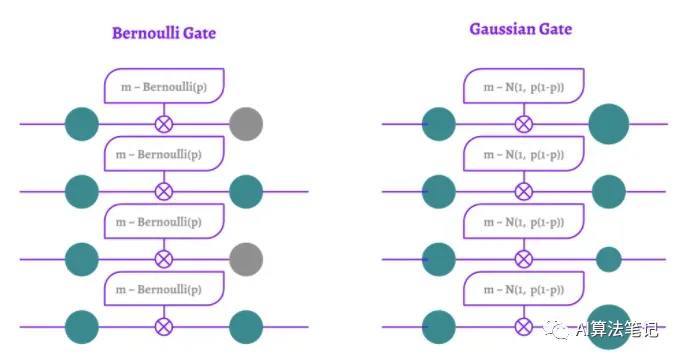
如上图所示,采用高斯分布来进行 dropout,实际上跟之前使用伯努利分布的区别在于它并不会改变神经元的协同适应与预测能力这两种能力和过拟合的相关性,改变的主要是训练阶段所需要的执行时间。
逻辑上来说,对于在训练前向阶段随机丢弃部分神经元,它们在反向传播的时候就不会进行更新,相当于不存在了,所以训练阶段是”放慢“了,而采用 Gaussian Dropout 方法,在每次迭代中,所有神经元都会采用,也就不会减速了。
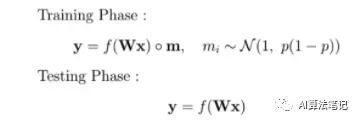
数学上的表示如上所示,有一个高斯mask的乘法(例如以1为中心的伯努利定律的标准差p(1-p))。通过在每次迭代中保持所有的神经元都是活跃的,从而随机地对其预测能力进行加权,从而模拟了dropout。这种方法的另一个实际优势集中在测试阶段,与没有dropout的模型相比,不需要进行任何修改。
3.4 Pooling Dropout
图像和特征图的问题在于像素非常依赖于它们的邻居。简单地说,在一张猫的照片上,如果你取一个与其外观对应的像素,那么所有相邻的像素都会对应相同的外观。两者几乎没有区别。
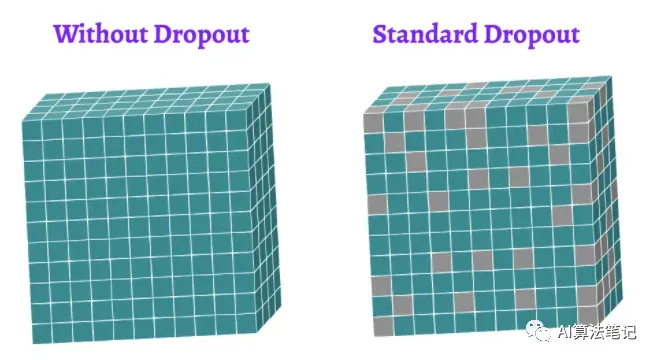
这就是标准 Dropout 方法的限制,实际上如果随机丢弃图像上的像素,那么几乎没有信息被删除,丢弃的像素几乎和其邻居相同,也就是说防止过拟合性能并不好,反而增加了额外的计算时间。
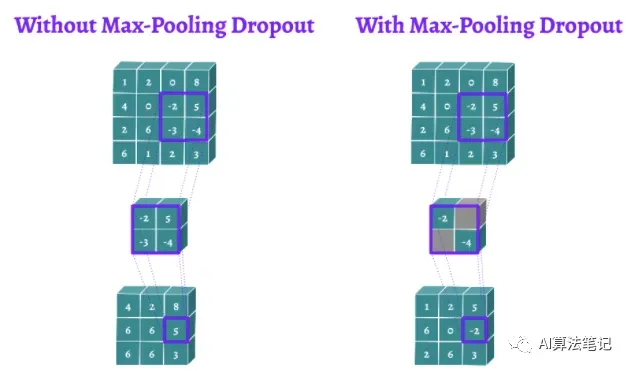
Max-Pooling Dropout是H. Wu和X. Gu提出的一种用于CNNs的Dropout方法。它在执行池化操作之前,直接将伯努利mask应用到最大池化层的内核上。直观地说,这允许对具有高激活的pooling结果最小化。这是一个限制某些神经元的高预测能力的很好的观点。在测试阶段,你可以根据出现的概率来确定前面方法的权重。
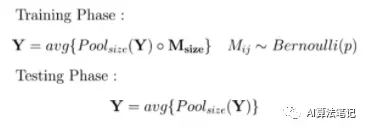
3.5 Spatial Dropout
在 CNN 中可以利用池化层,但也可以采用 J. Tompson等人提出的Spatial Dropout方法。他们提出用经典的dropout方法来解决这个问题,因为相邻像素高度相关,其思路是相比在单个像素上进行 Dropout 的操作,可以考虑在特征图上进行 Dropout,如下所示,比如还是以猫作为例子,可以从图像中移除红色通道,并强迫它总结图像中的蓝色和绿色通道,然后在下一次迭代中随机防止其他的特征图。
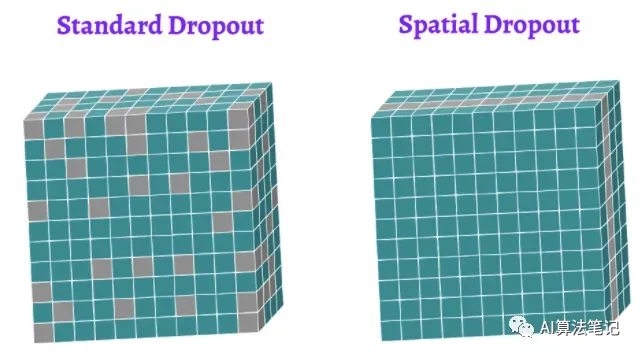
一般很少用普通的Dropout来处理卷积层,这样效果往往不会很理想,原因可能是卷积层的激活是空间上关联的,使用Dropout以后信息仍然能够通过卷积网络传输。而 Spatial Dropout 直接随机选取 feature map 中的 channel 进行 dropout,可以让 channel 之间减少互相的依赖关系。
在训练阶段,对每个feature map应用Bernoulli mask,其丢弃概率为p。然后在测试阶段,没有dropout,只有一个概率为1-p的加权。
在pytorch中对应Spatial Dropout实现如下:
torch.nn.Dropout2d(*p=0.5*, *inplace=False*)
- p (
python:float
*,*
optional
) – probability of an element to be zero-ed. - inplace (
bool
*,*
optional
) – If set to True , will do this operation in-place
输入输出有一定的要求:
- input shape: (N, C, H, W)
- output shape: (N, C, H, W)
>>> m = nn.Dropout2d(p=0.2)
>>> input = torch.randn(20, 16, 32, 32)
>>> output = m(input)
此外对3D feature map中也有对应的torch.nn.Dropout3d函数,和以上使用方法除输入输出为(N, C, D, H, W)以外,其他均相同。
3.6 Cutout
T. DeVries和G. W. Taylor提出的Cutout方法选择的是另一个做法,在不同区域中应用伯努利 mask,如下所示:
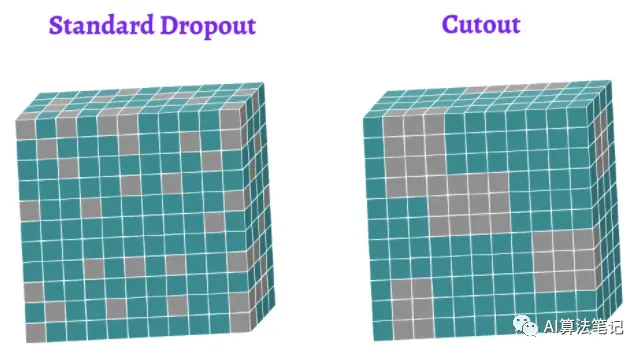
还是以之前的猫图像为例:该方法可以通过对图像的隐藏区域进行泛化从而限制过拟合。我们最后看到的是猫的头丢弃掉的画面。这迫使CNN了解到可以描述猫的不太明显的属性。
论文中的实验结果表明在使用了Cutout后可以提高神经网络的鲁棒性和整体性能,并且这种方法还可以和其他正则化方法配合使用。不过如何选取合适的Patch和数据集有非常强的相关关系,如果想用Cutout进行实验,需要针对Patch Length做一些实验。
3.7 Max-Drop
S. Park和N. Kwak提出的Max-Drop方法是Pooling Dropout 和高斯 Dropout 的混合,dropout是在最大池化层上执行的,但使用的是贝叶斯方法。
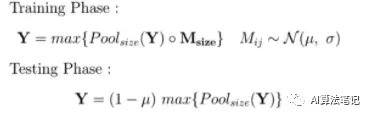
在他们的论文中,他们表明这种方法给出的结果与 Spatial Dropout一样有效。除此之外,在每次迭代中,所有的神经元都保持活跃,这限制了训练阶段的减速。这些结果都是用µ = 0.02和σ² = 0.05的数据得到的。
3.8 RNNDrop
上述的方法主要是应用在 DNNs 和 CNNs 中,但RNN 也是常用的深度模型结构,所以也有一些学者研究如何在 RNN 上采用 Dropout,不过在 RNN 上应用 dropout 是危险的,原因在于 RNN 的目的是长期保存事件的记忆。但传统的dropout方法效率不高,因为它们会产生噪音,阻止这些模型长期保存记忆。下面这些方法可以长期保存记忆。
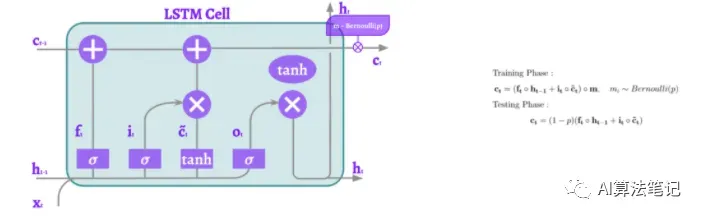
T. Moon等人提出的RNNDrop是最简单的方法。一个伯努利mask只应用于隐藏的单元格状态。但是这个掩码从一个序列到另一个序列保持不变。这称为dropout的逐序列采样。它只是意味着在每个迭代中我们创建一个随机掩码。然后从一个序列到另一个序列,这个掩码保持不变。所以被丢弃的元素一直被丢弃而留下来的元素一直留着。所有的序列都是这样。
3.9 循环 Droput
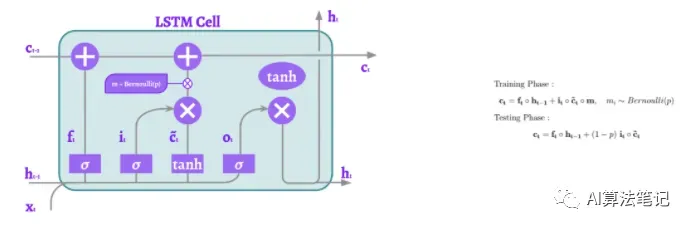
S. Semeniuta等人提出的循环Dropout是一个有趣的变体。单元格状态保持不变。dropout只应用于更新单元格状态的部分。所以在每次迭代中,伯努利的mask使一些元素不再对长期记忆有贡献。但是记忆并没有改变。
3.10 变分 RNN dropout
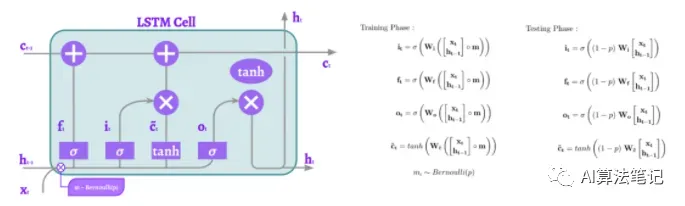
由Y. Gal和Z. Ghahramani介绍的RNN Dropout是在internal gates前的基于序列的Dropout的应用。这将导致LSTM在不同的点进行dropout,这个方法简单而有效。
3.11 Monte Carlo Dropout
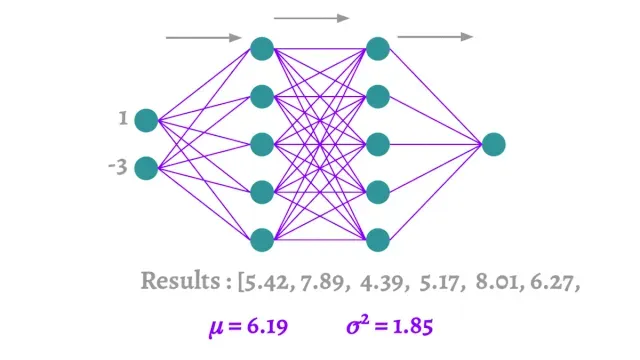
Dropout方法也可以提供一个模型不确定性的指标。这是因为对于相同的输入,经历了dropout的模型在每次迭代中会有一个不同的架构。这将导致输出中的方差。
如果网络相当泛化并且协同适应受到限制,那么预测将分布在整个模型中。当每次迭代使用相同的输入时,这将导致输出的方差较小。
研究这个方差可以给出一个可以分配给模型的置信度的概念。这可以从Y. Gal和Z. Ghahramani的方法中看出。
3.12 模型压缩
K. Neklyudov等人提出了利用变分dropout来剪枝DNNs和CNNs的方法,即对模型进行压缩。直观上说是因为通过随机应用 dropouts,可以看到给定神经元对预测是否有效,根据这个观察结果,就可以通过减少参数的数量,即对预测无效的神经元是可以删除的,从而实现模型压缩。
3.13 Stochastic Depth
这是一种在 DenseNet 前提出的,用在 ResNet 中,随机将一部分 Res Block 失活,实际操作和 Dropout 类似,也就是训练过程随机丢失一部分 Res Block,但是测试阶段是所有 ResBlock 都采用。这种方法在训练的时候可以采用较浅的深度(随机丢失 ResBlock,相当于随机跳过一些层),测试则使用了较深的深度,这可以减少训练时间,提高训练性能。
详细可以参考文章:卷积神经网络学习路线(十一)| Stochastic Depth(随机深度网络)
3.14 DropBlock
这个方法和 Cutout 比较相似,其思路就是在每个feature map上按spatial块随机设置失活。
DropBlock有三个重要的参数:
- block size控制block的大小
- γ
控制有多少个channel要进行DropBlock - keep prob类别Dropout中的p,以一定的概率失活
经过实验,可以证明block size控制大小最好在7×7, keep prob在整个训练过程中从1逐渐衰减到指定阈值比较好。
推荐阅读学习笔记
11.神经网络不收敛怎么办?看看是不是这些原因
AI 算法面试资料推荐
12. 7 个有用的 PyTorch 技巧
在公众号后台回复这些关键词,可以得到相应的信息:
- 回复”入门书籍“,获取机器学习入门资源,包括书籍、视频以及 python 入门书籍;
- 回复”数据结构“,获取数据结构算法书籍和 leetcode 题解;
- 回复”多标签“,获取使用 keras 实现的多标签图像分类代码和数据集
- 回复“pytorch 迁移学习”,获取 pytorch 的迁移学习教程代码
- 回复“py_ml”,获取初学者的机器学习入门教程代码和数据集
欢迎评论指正文章中的错误,谢谢!
文章出处登录后可见!