机器学习—吴恩达_ 第7周_学习总结
21.10.18-21.10.24
👉每周学习任务:
- 100% 回顾吴恩达机器学习前4章节
- 10% 神经网络学习
一、回顾机器学习前4章节
机器学习:使用已知数据集,通过数学模型让程序像人一样思考,然后对未知数据进行预测
1.机器学习分类:有监督学习 & 无监督学习
- 监督学习:有明确的数据,就有明确的答案。常用于分类问题和回归问题。

- 无监督学习:不告诉什么是错什么是对,只是被告知一堆数据,但不知道做什么,不知道类型,让机器自己找到答案。常用的聚类算法。

2.线性回归模型&梯度下降
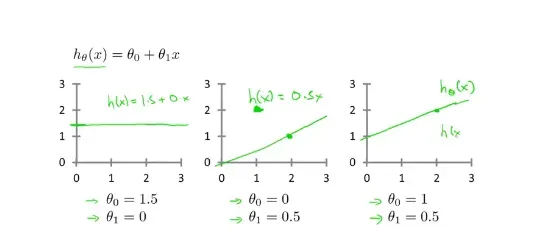
- 回归模型的一般例子: 函数公式:
where ==
和
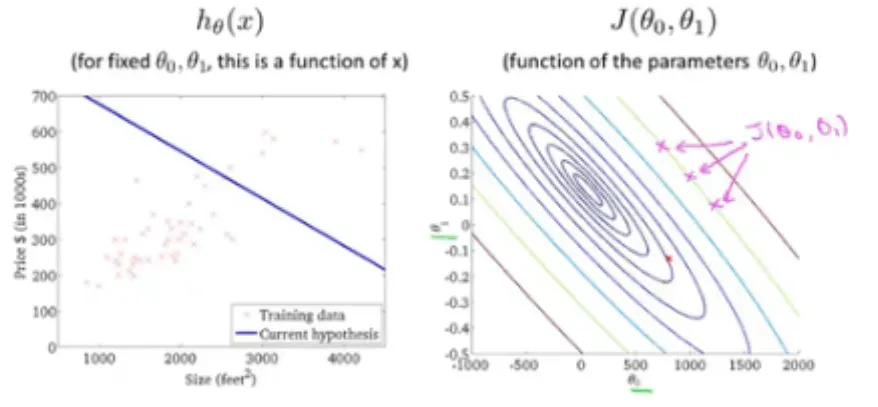
是整个函数中的变量,通过控制这两个变量调整函数的图像,使得输入参数和输出参数能够达到拟合,做出更正确的预测。一般可以使用 for 循环来进行两个参数的选择,但是计算出的值与真实值之间会存在误差,我们需要对误差进行获取以及得到最优的参数值,所以引入了代价函数==进行误差的分析。
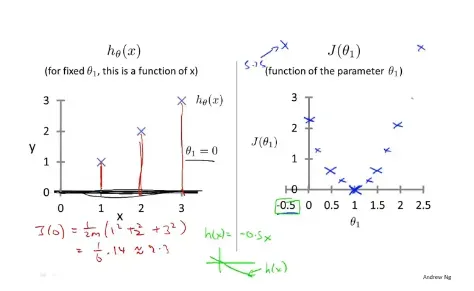
- 代价函数:在回归模型中,使用
来作为其代价函数,如下通过
的变化,求得对应
时有最小的代价函数值。当对下图右边进行求导时
,会发现越靠近最优解时,其偏导数是越靠近0的。
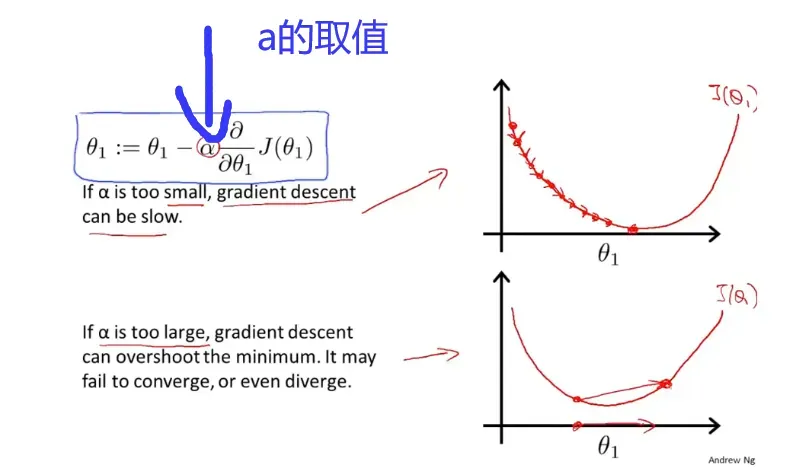
- 梯度下降:为了使得参数变化和代价函数关联起来,使用
对各个参数进行同步改值,其中==
==为学习率,太大太小均不可。梯度下降的过程中,接近最优解的时候,偏导数会越来越接近0,那步长也就会越来越小,最终达到合适的权重值。一下为梯度下降算法的流程。
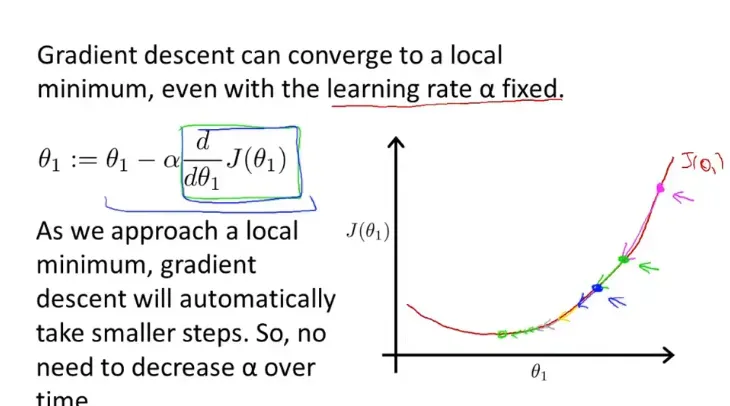
- 多个参数的梯度下降图像(轮廓)
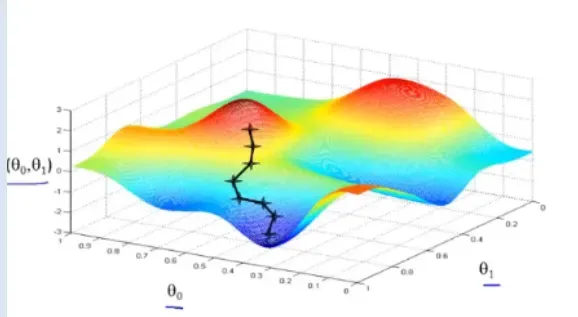
- 回归模型的批量参数梯度下降通常着眼于整个训练集的下降。存在全局最优解。
3.线性回归模型的实践-房价的预测
- 模型训练
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_california_housing as fch #加州房价预测数据
#数据的提取
feature=fch().data
target=fch().target
#数据的拆分
x_train,x_text,y_train,_y_test=train_test_split(feature,target,test_size=0.1,random_state=2021)
linear=LinearRegression() #模型初始化
#模型的训练
linear.fit(x_train,y_train)
#得到权重参数值 linear.coef_
#打印权重参数名以及参数值
[*zip(fch().feature_names,linear.coef_)]
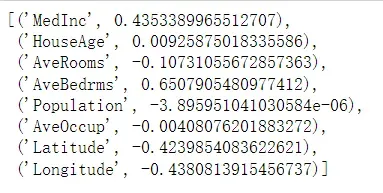
可以看出,值较小的参数对最终预测值的影响较小。
- 模型的评估:使用MSE(均方误差)来衡量真实值和预测值之间的差异from sklearn.metrics import mean_squared_error y_true=y_test #将真实值存到y_true中y_pred=linear.predict(x_test) #通过模型对测试数据集中的数据进行预测mean_squared_error(y_true,y_pred)#MSE值0.5253224455144776#使用交叉验证中的均方误差from sklearn.model_selection import cross_val_scorecross_val_score(linear,x_train,y_train,cv=5,scoring=’neg_mean_squared_error’).mean() #loss(损失值)-0.5284704303001286正数就为MSE
- 拟合图#绘制拟合图%matplotlib inlineimport matplotlib.pyplot as plty_pred=linear.predict(x_test)plt.plot(range(len(y_test)),sorted(y_test),c=”black”,label=”y_true”)plt.plot(range(len(y_pred)),sorted(y_pred),c=”red”,label=”y_predict”)plt.legend()plt.show
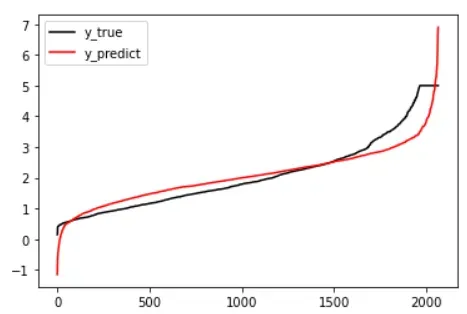
当mse越接近0的时候,数据将会更加的拟合
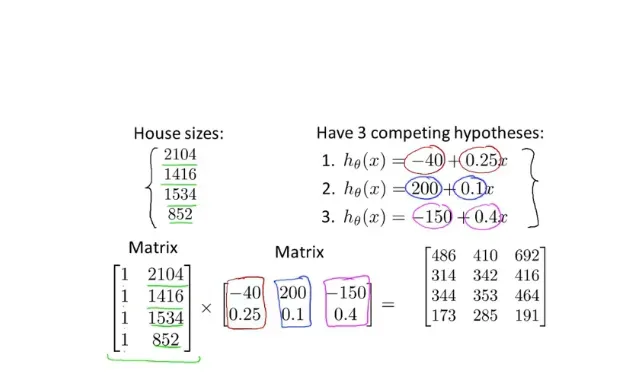
4.矩阵和向量
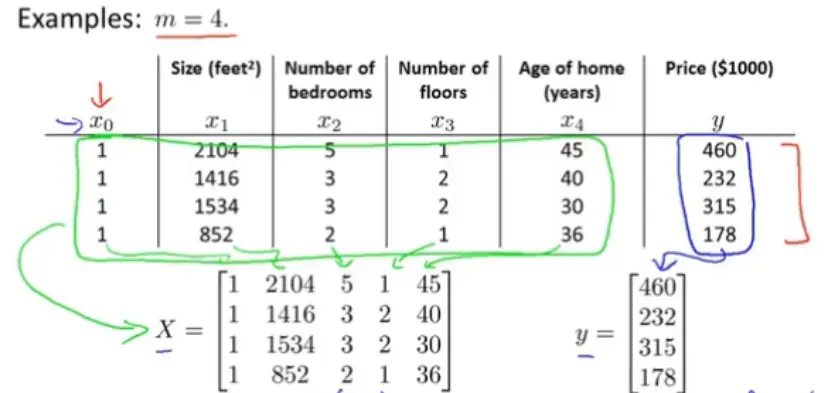
使用线性回归梯度下降时,的值由成本函数反复确定,增加了循环次数。在矩阵的运算中,我们可以一次使用多组数据作为参数,得到多组不同的预测值。 .因此,当函数方程有多个输入参数时,求解起来很方便。
引入矩阵时为了后面的正规方程寻最优解
5.多元线性回归&梯度下降&正规方程
- 多元线性回归梯度下降
- 功能:
- 成本函数:
- 梯度下降:KaTeX parse error: Undefined control sequence: \part at position 38: …-\alpha \frac {\̲p̲a̲r̲t̲ ̲J(\theta{_0},..…
- 运行过程:对多个参数进行梯度下降,得到最优值

- 特征缩放:当数据量大时,为了方便计算,我们可以对简单规则的值进行缩放,让我们的梯度下降更快,收敛更快。
- 数据有一定范围:数据可以按比例缩小范围
- 平均归一化:
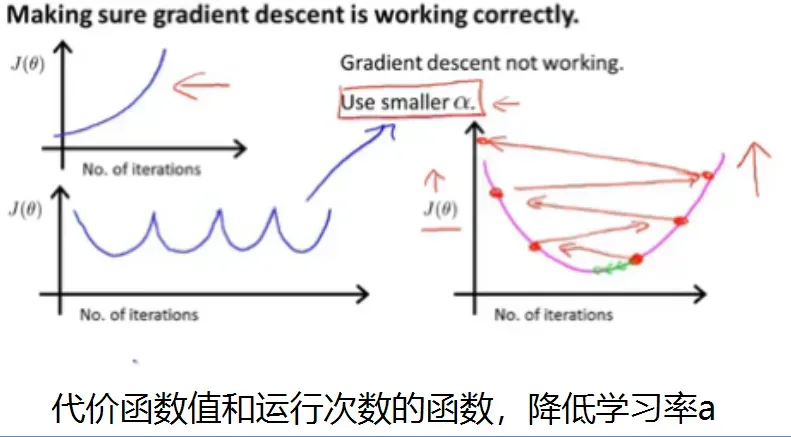
- 监控代价函数:为了监控是否达到最小值,可以使用执行次数和代价函数的值来绘制图像并监控。阈值通常可用于自动收敛测试。代价函数对学习率也有很大的影响,所以我们也需要通过合适的算法来选择合适的学习率

- 正规方程
- 梯度下降核心:通过对代价函数求偏导,得到近似0的值(等于0就是类似于极值的求解),最终得到合适的参数
- 正规方程核心:利用矩阵的运算:$\theta X=Y
\theta$的值
- 求得
(考虑是否可逆:一般均可在octave中用pinv算出,inv只能算不可逆的)
- 不可逆情况:特征值之间存在比例关系
- 奇异矩阵或者退化矩阵:存在多余的feature
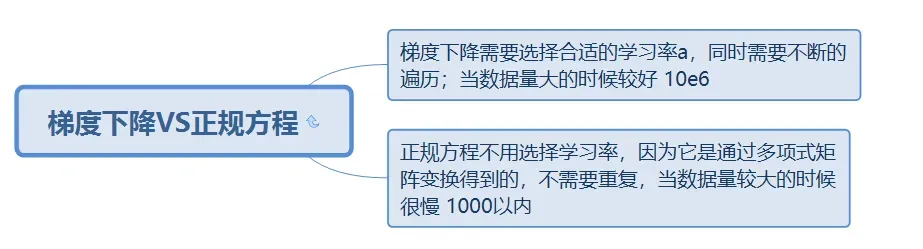
6.正规方程VS梯度下降
2.神经网络学习
让程序像大脑一样思考,模拟大脑的神经传递,通过层层映射关系将参数传递到最终结果
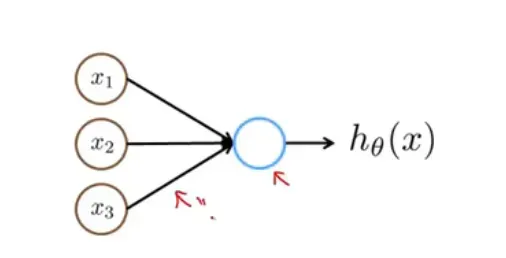
1.现实问题
当某个模型中的输入参数变得非常大时,比如图像中的像素块分解作为参数,使用常规模型会使计算量变得非常大。
2.神经网络
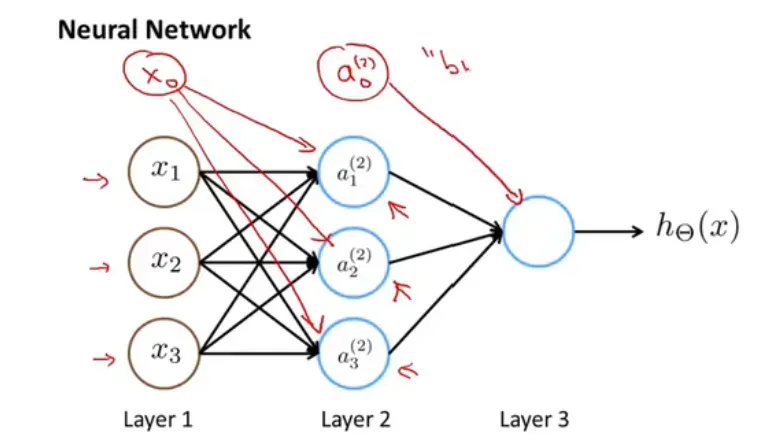
- 第一个参数输入后,函数会计算出第二层的目标值。第二层的目标值依次作为第三层的参数输入。等等
表示第2层的a1是第一层通过函数进行变换得到的,参数为第一层对应的权重。
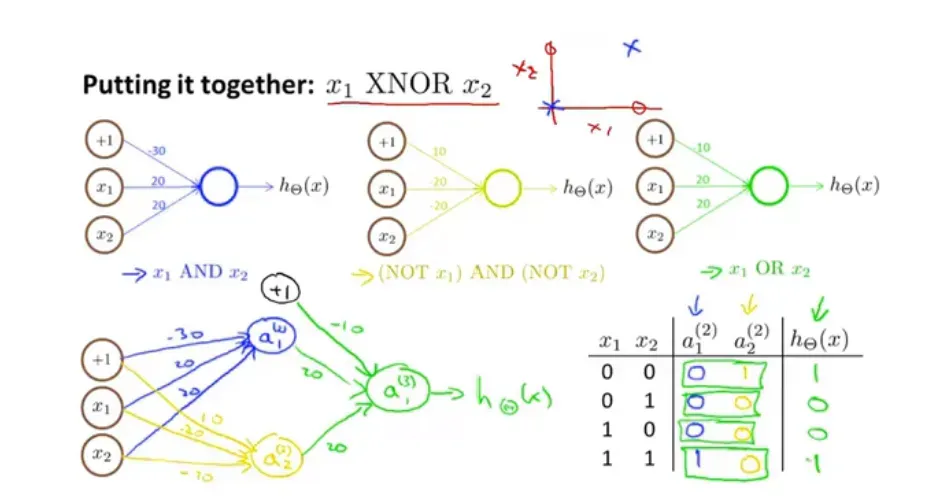
- 简单模拟:不同颜色有不同的映射规则,得到的每个参数都不一样
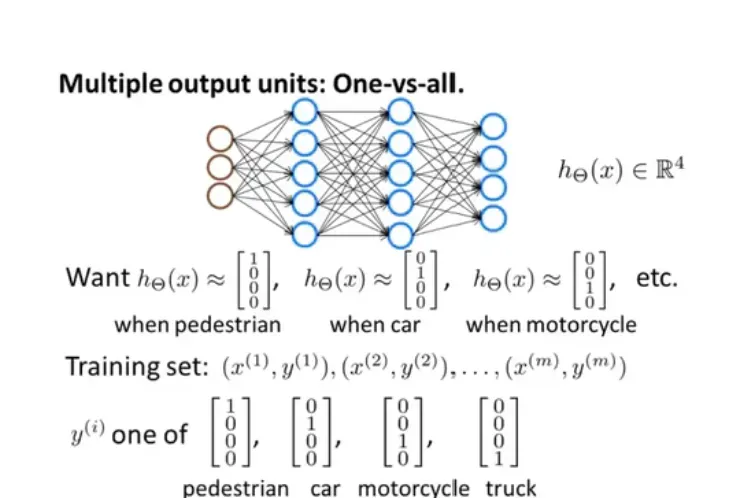
3.多元分类
一组数据中有大量数据,我们需要对数据进行多类分类,最终预测值不止一个。
文章出处登录后可见!
已经登录?立即刷新