前言
之前在做MVS的学习接触到了MVSNet,这钟基于深度学习的方法是目前的一个趋势,因此值得我花大功夫去研究一番。但是现在网上的资料很少,特别是中文的,能找到的一般就是MVSNet或者是R-MVSNet。
上周在排行耪上看见了d2hc网络,效果很不错,在论文发表时排名第一,目前下滑至第二。
以下是我对论文的看法:
一、准备工作
网络的流程脱胎于r-mvsnet,大体为 特征提取,代价体聚合,代价体正则,深度图优化,点云融合
该网络可视为对r-mvsnet的一个优化版本,所有的改进都是针对他的部件。
d2hc的改进如下:
1)light DRENet(密集接收扩展)模块,用于利用多尺度上下文信息提取原始尺寸的密集特征图;
2)混合U-LSTM,用于将三维匹配体正则化为预测深度图,通过耦合LSTM和U-Net架构,有效地聚合不同规模/不同尺度的信息。
3)使用动态一致性检测融合点云。
二、网络详情
网络结果如下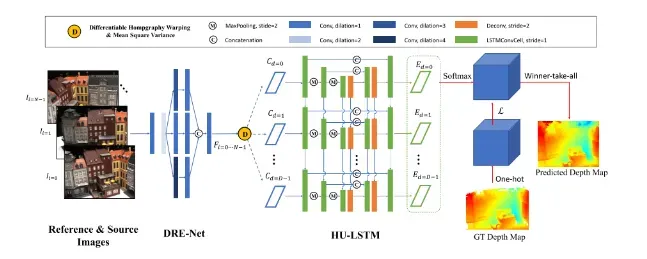
过程是:
将每个输入图像视为参考图像,并与几个相邻图像一起送入有效的密集混合递归MVSNet(DH RMVSNet),以回归相应的密集深度图。然后,我们使用动态一致性检查算法,通过利用所有相邻视图的几何一致性,过滤多视图图像的所有估计深度图,以获得更准确和可靠的深度值。在获得密集过滤的可靠深度图后,我们直接将具有可靠深度值的所有像素重新投影并融合到3D空间中,以生成相应的密集3D点云
1.特征提取部分
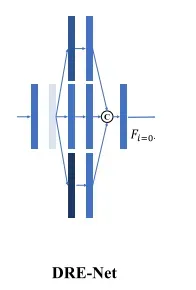
以前的大多数多视点立体网络,通常使用步长大于或等于2的二维卷积层来扩大接收场,同时降低分辨率,以满足内存限制。我们引入不同的扩展卷积层来生成多尺度背景信息,并保持分辨率,从而实现密集深度图估计
给定N视图图像,设Ii=0和Ii=1··N−1分别表示参考图像和相邻源图像。我们首先使用两个常用的卷积层来总结局部像素信息,然后使用三个具有不同放大比2、3、4的放大卷积层来提取多尺度上下文信息,而不影响分辨率。因此,在串联之后,DRENet可以提取密集的特征映射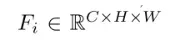
其中C表示特征通道,H,W表示输入图像的高度和宽度。
注意最终的feature map大小和原图一样,和之前的网络不同
2.代价体聚合
按照常见做法,构建3D特征卷{Vi}N−1 i=0,我们利用可区分单应性在不同视图之间扭曲提取的特征映射。我们采用相同的均方方差将它们聚合为一个代价体C。此步与MVSnet,R-MVSnet一样
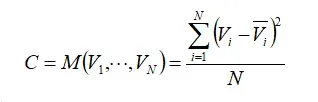
3.代价体正则
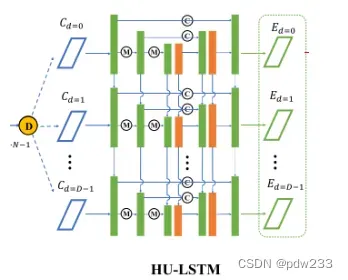
在众多网络中有两种不同的方法将成代价体C正则化为一个概率图P:
1.利用MVSNet中的3DCNN U-Net,它可以很好地利用局部信息和多尺度上下文信息,但由于GPU内存有限,特别是对于大分辨率图像,它不能直接用于回归原始密集深度图估计
2.R-MVSNet中使用堆叠卷积GRU,效率非常高,但缺少多尺度上下文信息的聚合
我们吸收了这两种方法的优点,提出了一种比GRU更强大的递归卷积单元(LSTMConvCell)的混合递归正则化网络。构造了一个混合U-LSTM,这是一种新颖的2D U-net体系结构,其中每一层都是LSTMConvCell,可以顺序处理。我们将此模块称为HU-LSTM。我们的HU-LSTM能够很好地聚合多尺度上下文信息,同时能够高效地处理密集的原始大小成本卷。与以前的递归方法R-MVSNet相比,它需要19.4%的GPU内存。
代价体C可被视为D张2D成本匹配图(代价图){C (i)} i=0…D-1在深度方向上连接。在顺序处理过程中,我们将正则化代价匹配图的输出表示为{CH(i)} i=0…D-1
因此,CH(i)依赖于当前投入成本匹配图C(i)和所有先前状态CH(0…i-1)
与RMVSNet中的GRU不同,我们引入了更强大的循环单元ConvLSTMCell,它有三个门映射来控制信息流,并且可以很好地聚合不同规模的上下文信息。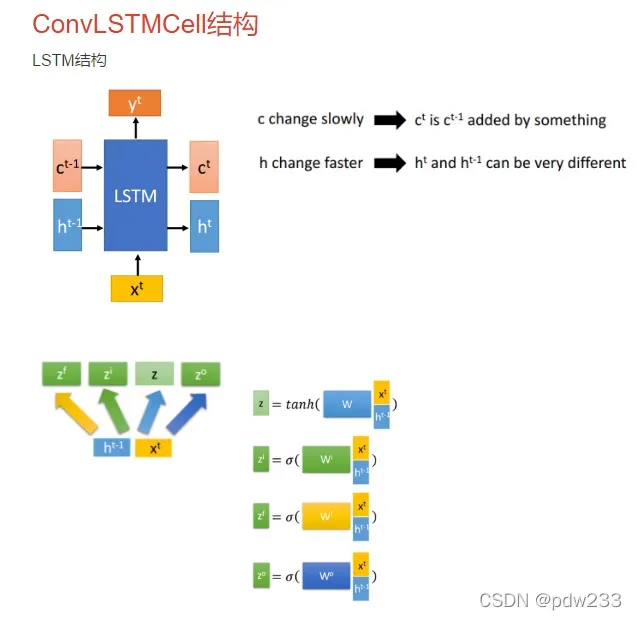
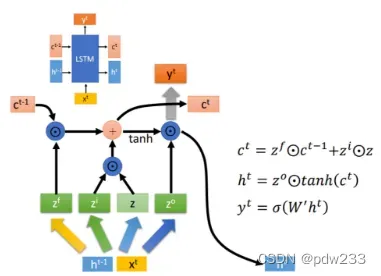
ConvLSTM,其不仅具有LSTM的时序建模能力,而且还能像CNN一样刻画局部特征。
传统的LSTM网络由input gate, forget gate, cell, output gate, hidden五个模块组成,这种LSTM结构我们也可以称之为FC-LSTM,因其内部门之间是依赖于类似前馈式神经网络来计算的,而这种FC-LSTM对于时序数据可以很好地处理,但是对于空间数据来说,将会带来冗余性,原因是空间数据具有很强的局部特征,但是FC-LSTM无法刻画此局部特征。
ConvLSTM尝试解决此问题,做法是将FC-LSTM中input-to-state和state-to-state部分由前馈式计算替换成卷积的形式,ConvLSTM的内部结构如下图所示:
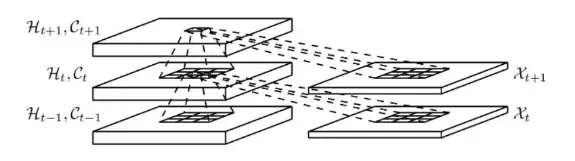
在论文中,他的正则化结构网络存在一些错误。在搜索了各种来源后,我做了一些修改。如下: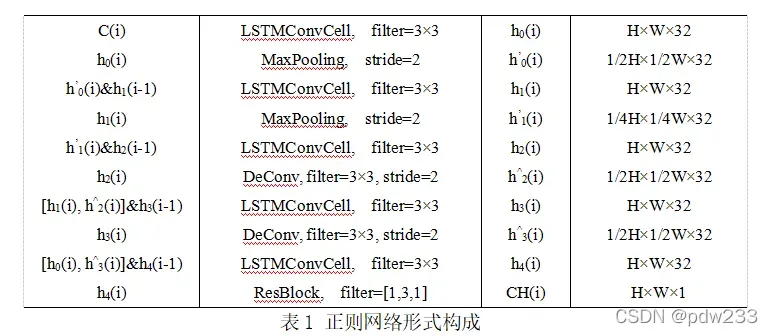
4.LOSS函数
将深度图优化视为多类分类任务,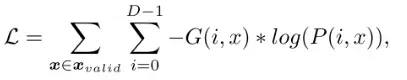
Xvalid是值中的有效像素集,G(i,x)表示由真值G在像素x处的深度值生成的一个one-hot向量,P(i,x)是相应的深度估计概率
5.动态一致性检测

实验
分为DTU和Blended_MVS数据集
1.DTU
设置size = 800*600
2.Blended_MVS
设置size = 768×576
几乎所有的网络都使用了低分的数据集,我也尝试过高分的数据集,没有好的结果。
文章出处登录后可见!