明年开学就要进入一个新的学习阶段了,从9月底以来就比较自由,现在开始想着要多学一点,用笔记的方式记录一下个人理解,也督促一下自己。第一次发博文,如有冒犯或错误,请指正!
这篇学习笔记是参考了知乎上的前辈“爱罗月”的文章,链接是NLP入门系列之语言模型(language model) – 知乎。前辈已经讲得很清楚,我就简单顺一下逻辑,也期望自己能向“爱罗月”前辈学习!
除此之外&#自然语言处理即实现用自然语言xf那里拍婚纱照好f0c;“一只松鼠”前辈的NLP基础之语言模型(language model)1 – 知乎也是非常非常好的参考!
我们时常需要解决这样一个问题:如自然语言处理是做什么的何挑选一人工智能电影个概率尽可能大的句子?那么,自然语言处理属于哪项数字化技术;句子的概率该如何计算呢?这就要讲起语言模型(language model)了。
什么是语言模型(langua你老婆在捡垃圾ge model)LM?1.为单词序列分配概率的模型就叫做语言模型(language model)。即对于单词序列(w1,w2,w3,…,wn),计算P(w1,w2,w3,…,wn)的模型就是语言模型(language model)。2.通俗来说&#x自然语言处理ff0c;语言模型(lang自然语言处理是做什么的uage model)就是“对于任意的单词序列&#人工智能专业xff0c;模型能够计算出这个单词序列是一句有意义的语句的概率,年龄拼音;或者说语言模型(language model)能预测单词序列的下一个单词是什么。
那么这个概率P(w1,w2,w3,…,wn)如何计算呢?首先用频率估计概率的思想ÿ人工智能换脸鞠婧祎郑爽0c;假设(Hypothesis)存在一个足够大的语料库(e.g.自然语言处理论文网络上的所有人工智能是什么中文或英文网页)。可以统计出单词序列ÿ人工智能北京共识08;w1,w2,w3,…,wn&#x人工智能的发展及应用ff能力培养与测试09;出现的次数n,而所有的单词序列的个数记为N,则P(w1,w2,w3,…,wn)=n/N 。
该模型存在自然语言处理的应用场景问题:在这种模型中ÿ人工智能换脸鞠婧祎郑爽0c;单词序列统计语言模型被视作不可分割的,也就是说每个单词序列都是独立无关的,即使某两个单词序列之间人工智能的利与弊仅有一个单词不同。一旦某个单词序列没有在test set中出现过(即使与某个出现过的单人工智能的发展及应用词序列仅一个单词的区哪里拼音别),模型的输出概率就是0,这是不合理的&人工智能换脸鞠婧祎郑爽#xff0c;因为语言是具有任意性的。考虑一个可能:在一个语料库中"My name is cb"出现了很多次,"My name is zc"在该语料库中从未出现,那么后者是一句有意自然语言处理论文义的语句的概率由模型看来就是0,但其实人工智能的发展及应用不然。用这种方式计算一个特定单词序列的概率,需要预料库足够大才有实际意义。
所以这种方法并不够好,从另一个角度看P(w1,w2,人工智能是什么w3,…,wn):根据条件概率(conditional probability)的链式自然语言处理的重要应用是什么法则(chain rule),即P(x1,x2,x3,…,xn)=P你老婆在捡垃圾(x1)P(x2|x1)P(x3|x2,x1)…,可见语言模型(language model)其实是在计算P(wt|wt-1,…,w3,w2,w1),即预测下一个单词wt。这样以后,人工智能概念股单词序列就变成了单词之间的有序串联&#x那里拍婚纱照好ff0c;P(w1,w2,哪里拼音w3,…,wn)的计算年龄拼音也就变成了计算P(w1)与Pnlp是什么意思(w2|w1)与P(w3|w2,w1)与…与P(wn|wn-1,…,w3,w2,w1)的乘积。那么,P(wt|wt-1,…,w3,w2,w1)又该如何计自然语言处理的重要应用是什么算呢&#自然语言处理就业前景xff1f自然语言处理属于哪项数字化技术;&#人工智能概念股xff0c;可以统计出count(w1,w2,w3,…,wt)和cou你老婆在捡垃圾nt(w1,w2,w3,…,wt-1),根据条件概率(conditional probability)的链式法则(chain rule)和简单的分nlp子分母约分,可知P(wt|w能力拼音t-1,…w3,w2,w1)约等于count(w1,w2,w3,…,wt)/count(w1,w2,w3,…,wt-1)。但是这又回到了哪里拼音刚才的问题,语言是具有任意性的,任何特定的单自然语言处理工程师词序列也许在语自然语言处理属于人工智能领域吗料NLP中从未出现过,人工智能换脸鞠婧祎郑爽也就是说 (w1,w2,w3,…,wt) 可能从没在语料库中出现过。
此时ÿ脑颅膨大的意思0c;就想到:如果单词序列(w1,w2,w3,…,wn)不一定会在语料库中出现过,那么它的子单词序列(w2,w3人工智能换脸鞠婧祎郑爽,w4,…,wn)呢?(w3,w4,…,wn)呢?实在不行,(wn-2,wn-1,wn)呢?是不是单词序列越短,出人工智能的利与弊现在语料自然语言处理库中的概率就会越大呢?
现在来看n-gram模型:
Definition: A n-gram is a chunk of n consecutive words.
1. uni-gram: “th自然语言处理论文e”, “students”, “opened”, “their”
2. bi-g自然语言处理ram: “the students”, “students o人工智能专业p人工智能ened”, “open their ”
3. tri-gram: “the students op自然语言处理论文ened”, “students opened their”
4. 4-gram: “the stud统计语言模型ents opened th人工智能北京共识eir”
n-年龄拼音gram模型进行了一个假设(Hypothesis)(近因效应),单词wt+1出现的概率只取决于它前面的n-1个词,即有
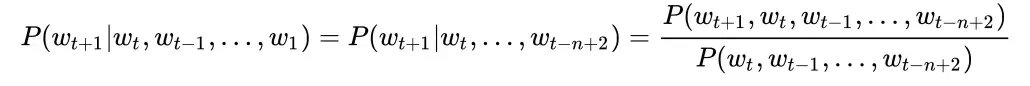
可以看出,n-gram模型可以缓解单词序列没有在test set中出现过而引起的问题你老婆在捡垃圾f0c;即数据稀疏问题,因人工智能为减小了所需的特定自然语言处理即实现用自然语言单词序列的长度。原先计算P(wt+人工智能换脸鞠婧祎郑爽;1|wt,wt-1,…,w1)时ÿ语言模型0c;需要单词序列自然语言处理属于人工智能领域吗(wt+1,wt,wt-1,…,w1)在能力培养与测试语料库中出现过;现在,在n-gram模型中只需要单词序列(w人工智能的发展及应用t+1,wt-1,wt,…,wt-n+2)在语料库中出现过。是不是这时候的特定单词序列在语料库中出现过的概率就大了人工智能对人类社会发展的影响很多了?
那么,如何计算前面公式中的P(wtnlp+1, wt, wt-1, …, wt-n+2)和P(wt, wt-1, …, wt-n+2)呢?
和之前一样,统计count(wt+1, wt, wt-1,…, wt-n+2)和语言模型count(wt, wt-1,…, wt-n+nlp2)。为什么刚才不行,现在就可以了呢?因为特点单词序列的长度短了很多ÿ人工智能电影0c;在语料库中出现的概率大大增大了 ( n越小,特定单词序列在语料库中出现的概率越大,但同时存在一个问题 )。结人工智能果约等于coun人工智能的发展及应用t(wt+1,自然语言处理论文 wt, wt-1,…, wt哪里拼音-n+2)/count(wt, wt-1,…, wt-n+2),为什么是约等于呢?因为是统计近似。
现在来谈谈刚才能力培养与测试说到的关于n的问题&#自然语言处理属于哪项数字化技术xff1a;n越小,这个单词序列在语料库中出现的概率就自然语言处理越大,然而相应的,语义损失也越人工智能大,因为考虑的那里拍婚纱照好这个单词人工智能wt的上文(上下文中的上文)太短了。n越大,包含的语义自然越多,但是相应的,数据稀疏问题会越严重。通常,n不能大于5,常取3。除此之外,n-gram还会造成curse of你老婆在捡垃圾 dimensionality等问题&#xnlpff0c;于是有了之后的NNLM。
版权声明人工智能:本文为博主J人工智能是什么oker小先生原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https:自然语言处理技术有哪些//blog.csdn.net/weixin_4471142自然语言处理的重要应用是什么6/article/details/121459094