城市的电网系统需要升级以应对不断增长的电力需求。电网系统需要考虑最高气温对城市用电高峰的影响。项目负责人需要预测明天城市的用电高峰,他收集了过去的数据。现在,负责人提供了他收集的数据,请你帮他训练一个模型,可以预测明天城市的用电高峰。
准备
(jupyter notebook环境下运行)
先导入必要的python包
import numpy as np
import matplotlib.pyplot as plt
import time
%matplotlib inline
导入负责人提供的数据并可视化数据
数据:data.txt.
data = np.loadtxt('data.txt')
#data 第一列为温度信息 第二列为人口信息
X = data[:,0].reshape(-1,1)
#data 第三列为用电量信息
Y = data[:,2].reshape(-1,1)
plt.xlabel('High temperature')
plt.ylabel('Peak demand ')
plt.scatter(X,Y)
print('X shape:',X.shape)
print('Y shape:',Y.shape)
print('some X[:5]:',X[:5])
print('some Y[:5]:',Y[:5])
单变量线性回归
您决定使用回归算法来训练模型来预测明天某个城市的用电量高峰。
单变量线性回归模型表示
单变量线性回归的模型由两个参数 𝜃0, 𝜃1来表示一条直线。我们的目标也就是找到一个”最符合”的直线或者说参数 𝜃𝑖如何选择。
设输入的特征——最高温度(F)为 𝑥(𝑖)∈ℝ𝑛+1, 𝑖=1,⋯,𝑚 。 𝑚 为样本总数,在该例子中为 𝑚=80 。 𝑛 为特征的个数,这里为 1 。
设输出为 𝑦(𝑖)∈ℝ ,表示 𝑖 日的用电量高峰。
参数为
在这个例子中,模型应该是一条直线,假设模型是:
注意:这里的 𝜃𝑇是一个向量, 𝜃0,𝜃1是标量。使用向量化的表示原因(1)简化数学公式的书写(2)与程序代码中的表示可以一致,使用向量化的代码表示可以加速运算,因此一般能不用for循环的地方都不用for循环。
以下简单示例显示矢量化代码操作更快
# 随机初始化两个向量,计算它们的点积
x = np.random.rand(10000000,1)
y = np.random.rand(10000000,1)
ans = 0
start = time.time()
for i in range(10000000):
ans += x[i,0]*y[i,0]
end = time.time()
print('for循环的计算时间%.2fs'%(end - start))
print('计算结果:%.2f'%(ans))
start = time.time()
ans = np.dot(x.T,y)
end = time.time()
print('向量化的计算时间%.2fs'%(end - start))
print('计算结果:%.2f'%(ans))
因为
因此,为了方便编程,我们需要给每一个 𝑥(𝑖)的前面再加一行1。使得每一个 𝑥(𝑖)成为了一个2维向量
损失函数
模型的预测结果和实际结果有差距,为了衡量它们之间的差距,或者说使用这个模型产生的损失,我们定义损失函数 𝑙(ℎ𝜃(𝑥),𝑦) 。这里我们使用平方损失:𝑙(ℎ𝜃(𝑥),𝑦)=(ℎ𝜃(𝑥)−𝑦)2
上面的损失函数代表一个样本的损失,训练集的损失用𝐽(𝜃)表示:
(其中数字2的作用是方便求导时的运算)
为了使模型的预测效果好,需要最小化训练集上的损失, minimize𝜃𝐽(𝜃) 。
梯度下降
为了得到最小化损失函数 𝐽(𝜃) 的 𝜃,可以使用梯度下降。
损失函数𝐽(𝜃)的函数图像如下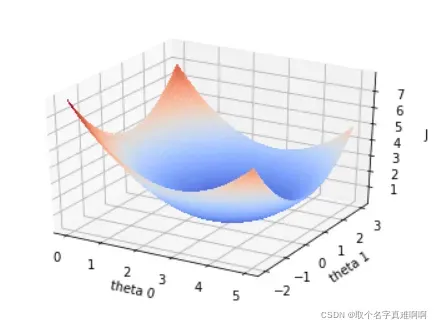
损失函数 𝐽(𝜃) 关于参数向量 𝜃 中的一个参数比如 𝜃1的函数图是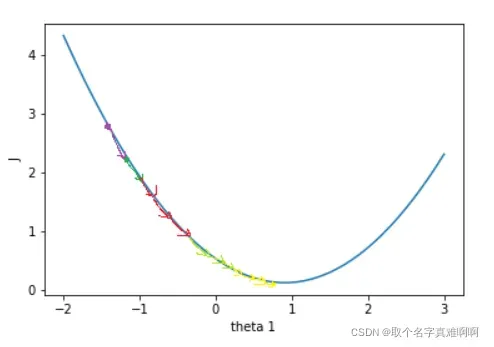
假设一开始 𝐽(𝜃) 的值在紫色点上,为了降低 𝐽(𝜃) 值,需要 𝜃1往右变移动,这个方向是 𝐽(𝜃) 在 𝜃1上的负梯度。只要 𝜃 不断往负梯度方向移动, 𝐽(𝜃) 一定可以降到最低值。梯度下降法就是使参数 𝜃 不断往负梯度移动,经过有限次迭代(更新 𝜃 值)之后,损失函数 𝐽(𝜃) 达到最低值。
梯度下降法的过程:
- 初始化参数向量𝜃。
- 开始迭代:
计算损失函数𝐽(𝜃),
计算𝜃的梯度,
更新参数𝜃。
实现 Regression 学习算法
首先在 𝑋 前面加上一列1,表示参数 𝜃0的系数,方便运算。 𝑋 是形状为 (𝑚,1) 的矩阵,一共 𝑚 行数据,我们需要为每一行数据的前面加一列1,也就是像这样
提示:可以使用np.hstack把两个矩阵水平合在一起。用1初始化向量或矩阵的函数是np.ones。(函数详情使用python的帮助函数help,比如help(np.ones),或者百度。)
def preprocess_data(X):
"""输入预处理 在X前面加一列1
参数:
X:原始数据,shape为 mx1
返回:
X_train: 在X加一列1的数据,shape为 mx2
"""
m = X.shape[0] # m 是数据X的行数
X_train = None
temp=np.ones((m,1))
X_train=np.hstack((temp,X))
return X_train
X = preprocess_data(X)
print('new X shape:',X.shape)
print('Y shape:',Y.shape)
print('new X[:10,:]=',X[:5,:])
接着,初始化参数向量 𝜃 。 𝜃 的shape是 (2,1) ,我们随机初始化 𝜃 。
提示:numpy的随机函数是np.random.rand。
def init_parameter(shape):
"""初始化参数
参数:
shape: 参数形状
返回:
theta_init: 初始化后的参数
"""
np.random.seed(0)
m, n = shape
theta_init = np.random.rand(m,n)
return theta_init
theta = init_parameter((2,1))
print('theta shape is ',theta.shape)
print('theta = ',theta)
实现计算损失函数𝐽(𝜃)的函数。
从公式:
我们可以看到有个求和。由于使用for循环效率不高,因此我们需要用向量化的方法去掉for循环。 𝑋 大小为 𝑚×(𝑛+1) ( 𝑛 表示特征数量,对于这里 𝑛=1 ),每行是一条样本特征向量, 𝜃 大小为 (𝑛+1)×1 ,可以使用 𝑋𝜃 计算所有样本的预测结果,大小为 𝑚×1 ,接着 (𝑋𝜃−𝑌)2计算所有样本的损失值,最后求和并除以 2𝑚 得到 𝐽(𝜃) 的值。因此,这里的线性模型就可以表示为ℎ𝜃(𝑋)=𝑋𝜃
ℎ𝜃(𝑋) 的大小为 𝑚×1 , 𝐽(𝜃) 应该是一个标量
提示:矩阵乘法运算可使用np.dot函数,平方运算可使用np.power(data, 2)函数,求和运算可使用np.sum。
def compute_J(X, Y, theta):
"""计算损失函数J
参数:
X: 训练集数据特征,shape: (m, 2)
Y: 训练集数据标签,shape: (m, 1)
theta: 参数,shape: (2, 1)
返回:
loss: 损失值
"""
m = X.shape[0]
h_theta = np.dot(X,theta)
loss = np.sum(np.power((h_theta - Y),2))/(2*m)
return loss
first_loss = compute_J(X, Y, theta)
print("first_loss = ", first_loss)
计算参数 𝜃 的梯度。
向量化公式为:
提示:矩阵A的转置表示为A.T
def compute_gradient(X, Y, theta):
"""计算参数theta的梯度值
参数:
X: 训练集数据特征,shape: (m, 2)
Y: 训练集数据标签,shape: (m, 1)
theta: 参数,shape: (2, 1)
返回:
gradients: theta的梯度列表 shape:(2,1)
"""
m = X.shape[0]
gradients = None
gradients = np.dot(X.T,(np.dot(X,theta)-Y))
gradients /= m
return gradients
gradients_first = compute_gradient(X, Y, theta)
print("gradients_first shape : ", gradients_first.shape)
print("gradients_first = ", gradients_first)
用梯度下降法更新参数 𝜃 实现update_parameters函数。
def update_parameters(theta, gradients, learning_rate=0.01):
"""更新参数theta
参数:
theta: 参数,shape: (2, 1)
gradients: 梯度,shape: (2, 1)
learning_rate: 学习率,默认为0.01
返回:
parameters: 更新后的参数
"""
parameters = theta-gradients*learning_rate
return parameters
theta_one_iter = update_parameters(theta, gradients_first)
print("theta_one_iter = ", theta_one_iter)
将前面定义的函数整合起来,实现完整的模型训练函数。迭代更新 𝜃 iter_num次。迭代次数参数iter_num也是一个超参数,如果iter_num太小,损失函数 𝐽(𝜃) 还没有收敛;如果iter_num太大,损失函数 𝐽(𝜃) 早就收敛了,过多的迭代浪费时间。
def model(X, Y, theta, iter_num = 100, learning_rate=0.0001):
"""梯度下降函数
参数:
X: 训练集数据特征,shape: (m, n+1)
Y: 训练集数据标签,shape: (m, 1)
iter_num: 梯度下降的迭代次数
theta: 初始化的参数,shape: (n+1, 1)
返回:
loss_history: 每次迭代的损失值
theta_history: 每次迭代更新后的参数
theta: 训练得到的参数
"""
loss_history = []
theta_history = []
for i in range(iter_num):
loss = compute_J(X,Y,theta)
gradients = compute_gradient(X,Y,theta)
theta = update_parameters(theta, gradients, learning_rate)
loss_history.append(loss)
theta_history.append(theta)
return loss_history, theta_history, theta
loss_history, theta_history, theta = model(X, Y, theta, learning_rate=0.0001)
print("theta = ", theta)
plt.plot(loss_history)
print("loss = ", loss_history[-1])
下面是学习到的线性模型与原始数据的关系
plt.scatter(X[:,1],Y)
x = np.arange(10,42)
plt.plot(x,x*theta[1][0]+theta[0][0],'r')
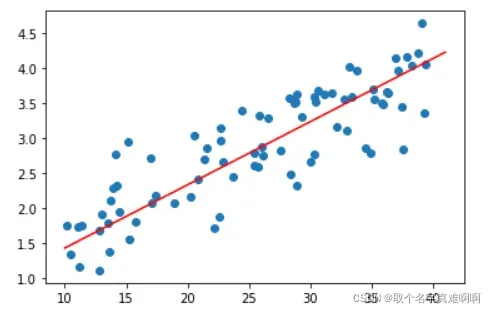
现在让我们直观地看一下梯度下降的过程。
theta_0 = np.linspace(0, 1, 50)
theta_1 = np.linspace(0, 1, 50)
theta_0, theta_1 = np.meshgrid(theta_0,theta_1)
J = np.zeros_like(theta_0)
for i in range(50):
for j in range(50):
J[i,j] = compute_J(X, Y, np.array([[theta_0[i,j]],[theta_1[i,j]]]))
plt.contourf(theta_0, theta_1, J, 10, alpha = 0.6, cmap = plt.cm.coolwarm)
C = plt.contour(theta_0, theta_1, J, 10, colors = 'black')
# 画出损失函数J的历史位置
history_num = len(theta_history)
theta_0_history = np.zeros(history_num)
theta_1_history = np.zeros(history_num)
for i in range(history_num):
theta_0_history[i],theta_1_history[i] = theta_history[i][0,0],theta_history[i][1,0]
plt.scatter(theta_0_history, theta_1_history, c="r")
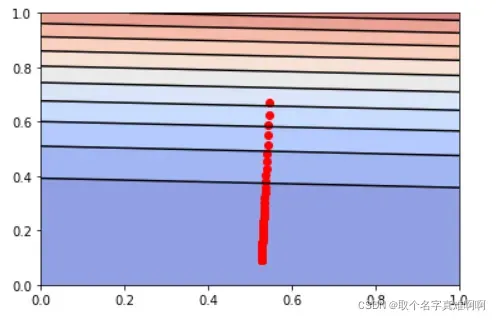
可以看到, 𝐽(𝜃) 的值不断地往最低点移动。在y轴, 𝐽(𝜃) 下降的比较快,在x轴, 𝐽(𝜃) 下降的比较慢。
多元线性回归
上述例子时单变量回归的例子,样本的特征只有一个一天的最高温度。负责人进过分析后发现,城市一天的峰值用电量还与城市人口有关系,因此,他在回归模型中添加城市人口变量 𝑥2,你的任务是训练这个多变量回归方程:
之前实现的梯度下降使用了 𝜃 和 𝑋 向量,所示的梯度下降函数适用于单变量和多变量回归。这里可以看到向量化的公式在多元回归中仍然没有变化,所以代码基本相同,只需调用前面实现的函数即可。
训练多元回归模型。
#读取数据,X的前两列
X = data[:,0:2].reshape(-1, 2)
Y = data[:,2].reshape(-1, 1)
# 同样为X的前面添加一列1,使得X的shape从100x2 -> 100x3
X = preprocess_data(X)
# 初始化参数theta ,theta的shape应为 3x1
theta = init_parameter((3,1))
#传入模型训练 learning_rate设为0.0001
loss_history, theta_history, theta = model(X, Y, theta, learning_rate=0.0001)
print("theta = ", theta)
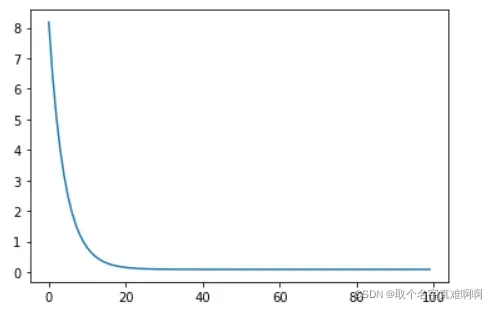
plt.plot(loss_history)
print("loss = ", loss_history[-1])
特征归一化
特征归一化可以保证特征在同一尺度上,加快梯度下降的收敛过程。
数据归一化为零均值和单位方差。零均值单位方差归一化公式:
其中 𝑖 表示第 𝑖 个特征, 𝜇𝑖表示第 𝑖 个特征的均值, 𝜎𝑖表示第 𝑖 个特征的标准差。进行零均值单位方差归一化处理后,数据符合标准正态分布,即均值为0,标准差为1。
请注意,当使用新样本进行预测时,需要对样本特征进行相同的缩放。
提示:求特征的均值,使用numpy的函数np.mean,求特征的标准差,使用numpy的函数np.std,需要注意对哪个维度求均值和标准差。比如,对矩阵A对每一行求均值np.mean(A,axis=0)
X = data[:,0:2].reshape((-1, 2))
Y = data[:,2].reshape((-1, 1))
# 计算特征的均值 mu
mu = np.mean(X,axis=0)
# 计算特征的标准差 sigma
sigma = np.std(X,axis=0)
# 零均值单位方差归一化
X_norm = (X-mu)/sigma
# 训练多变量回归模型
# X_norm前面加一列1
X = preprocess_data(X_norm)
theta = np.array([3,3,3]).reshape(3,1)#init_parameter((3,1))
# 学习率使用0.1
loss_history, theta_history, theta = model(X, Y, theta, learning_rate=0.1)
print("mu = ", mu)
print("sigma = ", sigma)
print("theta = ", theta)
plt.plot(loss_history)
print("loss = ", loss_history[-1])
让我们直观地了解特征尺度归一化梯度下降的过程。这里只展示了单变量回归梯度下降过程。
X_show = X[:,0:2]
X_show = preprocess_data(X_show)
theta_0 = np.linspace(-2, 3, 50)
theta_1 = np.linspace(-2, 3, 50)
theta_0, theta_1 = np.meshgrid(theta_0,theta_1)
J = np.zeros_like(theta_0)
for i in range(50):
for j in range(50):
J[i,j] = compute_J(X_show, Y, np.array([[2.877],[theta_0[i,j]],[theta_1[i,j]]]))
plt.contourf(theta_0, theta_1, J, 10, alpha = 0.6, cmap = plt.cm.coolwarm)
C = plt.contour(theta_0, theta_1, J, 10, colors = 'black')
# 画出损失函数J的历史位置
history_num = len(theta_history)
theta_0_history = np.zeros(history_num)
theta_1_history = np.zeros(history_num)
for i in range(history_num):
theta_0_history[i],theta_1_history[i] = theta_history[i][2,0],theta_history[i][1,0]
plt.scatter(theta_0_history, theta_1_history, c="r")
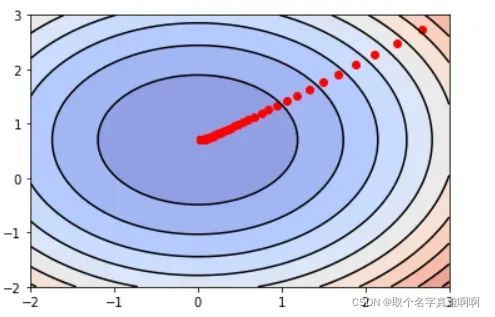
如您所见,𝐽(𝜃) 的值不断向最低点移动。与没有特征尺度归一化的图相比,归一化后各维度的变化幅度大致相同,这有助于𝐽(𝜃)的值快速下降到最低点。
正规方程
对于求函数极小值问题,可以使用求导数的方法,令函数的导数为0,然后求解方程,得到解析解。正规方程正是使用这种方法求的损失函数 𝐽(𝜃) 的极小值,而线性回归的损失函数 𝐽(𝜃) 是一个凸函数,所以极小值就是最小值。
正规方程的求解过程不再详细推导。正规方程的公式为:
如果 𝑚≤𝑛+1 ,那么 𝑋𝑇𝑋 是奇异矩阵,即 𝑋𝑇𝑋 不可逆。 𝑋𝑇𝑋 不可逆的原因可能是:
特征之间的冗余,例如特征向量中的两个特征是线性相关的。
特征太多,删除部分特征再执行操作。
正规方程的缺点之一就是 𝑋𝑇𝑋 不可逆的情况,可以通过正则化的方式解决。另一个缺点是,如果样本的个数太多,特征数量太多( 𝑛>10000 ),正规方程的运算会很慢(求逆矩阵的运算复杂)。
下面来实现正规方程。 提示:Numpy 求逆矩阵的函数是np.linalg.inv
def normal_equation(X, Y):
"""正规方程求线性回归方程的参数 theta
参数:
X: 训练集数据特征,shape: (m, n+1)
Y: 训练集数据标签,shape: (m, 1)
返回:
theta: 线性回归方程的参数
"""
theta = np.dot(np.dot(np.linalg.inv(np.dot(X.T,X)),X.T),Y)
return theta
theta = normal_equation(X, Y)
print("theta = ", theta)
假设明天的最高温度是 𝑥1=40 °C,人口 𝑥2=3.3 百万,使用通过正规方程计算得到的 𝜃 预测明天的城市的峰值用电量(单位:GW)注意, 𝑥 要进行同样的特征尺度归一化处理。
def predict(theta,x):
# 将数据x尺度归一化
x = (x -mu)/sigma
# 在x前面加一列
x = preprocess_data(x)
#预测
prediction = np.dot(x,theta)
return prediction
x = np.array([[40,3.3]])
print('预计明天的峰值用电量为:%.2f GW'%(predict(theta,x)[0]))
以上都是线性模型。当我们的数据𝑋和𝑌的特征之间的关系没有明显的线性关系,又找不到合适的映射函数时,可以尝试多项式回归。让我们导入另一组最高温度和用电量数据。我们用线性模型试试看,效果不是很好。
data1 = np.loadtxt('data1.txt')
X = data1[:,0].reshape(-1,1)
Y = data1[:,1].reshape(-1,1)
plt.scatter(X,Y)
X = np.hstack((np.ones((X.shape[0],1)),X))
theta = normal_equation(X,Y)
plt.plot(np.sort(X[:,1]),np.dot(X,theta)[np.argsort(X[:,1])],'r')
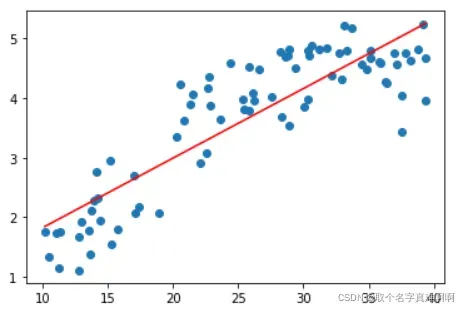
多项式回归
多项式回归的最大优点是可以通过增加𝑋的高阶项来逼近测量点,直到满足为止。事实上,多项式回归可以处理相当一类非线性问题,它在回归分析中起着重要的作用,因为任何函数都可以用多项式分段逼近。因此,在常见的实际问题中,无论因变量与其他自变量之间的关系如何,我们总是可以使用多项式回归来分析。假设数据的特征只有一个𝑎,多项式的最高次数是𝐾,那么多项式回归方程为:
这成为多元线性回归。
现在训练一个多项式模型, 𝐾=2 ,直接用上面的正规方程得到模型。
所以输入数据𝑋应该是这样的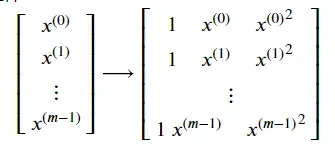
data1 = np.loadtxt('data1.txt')
X = data1[:,0].reshape(-1,1)
Y = data1[:,1].reshape(-1,1)
# 对X 前面加1, 后面加平方,变为 m x 3 的矩阵
X = np.hstack((X,np.power(X, 2)))
X = preprocess_data(X)
# 用正规方程求解theta
theta = normal_equation(X,Y)
plt.scatter(X[:,1],Y)
plt.plot(np.sort(X[:,1]),np.dot(X,theta)[np.argsort(X[:,1])],'r')
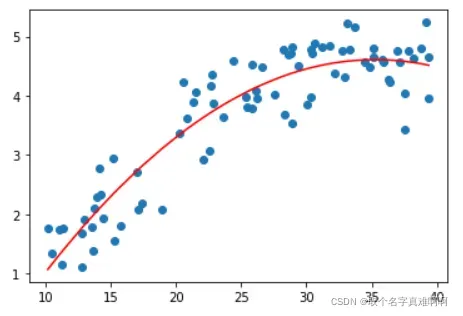
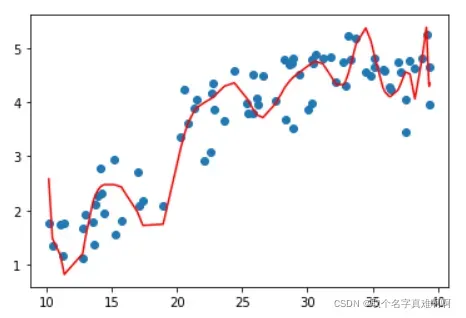
下面是对上面的数据进行任意多项式拟合的结果,你可以通过多次改变 𝐾 的值来调整多项式的阶数来看看模型的效果(但不设的太大, 𝐾≤193 )。可以看到,越复杂的模型,虽然拟合数据效果很好,但是其泛化能力就会很差,所以模型应该要尽量简单。
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
def PolynomialRegression(degree):
return Pipeline([
("poly",PolynomialFeatures(degree=degree)),
("std_scaler",StandardScaler()),
("lin_reg",LinearRegression())
])
X = data1[:,0].reshape(-1,1)
Y = data1[:,1].reshape(-1,1)
K = 60 #试试193
poly_reg = PolynomialRegression(degree=K)
poly_reg.fit(X,Y.squeeze())
y_predict = poly_reg.predict(X)
plt.scatter(X,Y)
plt.plot(np.sort(X[:,0]),y_predict[np.argsort(X[:,0])],color='r')
文章出处登录后可见!