机器学习(西瓜书+南瓜书)第一、二章总结(python代码实现)
一、理论总结
1.1 什么是机器学习?
什么是机器学习?简单来说,就是所谓的“智能”,根据我们生活中的经验,对尚未发生的事件进行预测,并利用经验通过计算手段来提升系统本身的性能。甚至允许计算机从数据中生成“模型”的算法。
下图是一个比较形象的比喻,直观地体现了机器学习的思想。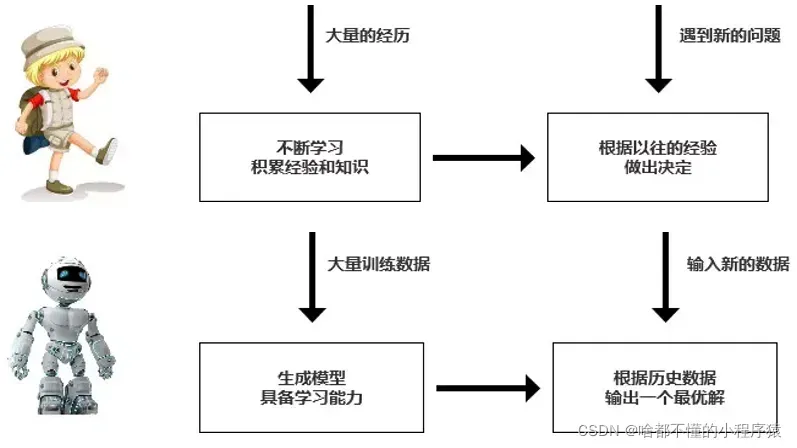
1.2 基本术语

数据集(data_set):就是一个存储数据的集合,一般有图片或者包含数字的表格。如上图所示,一个表格就可以代表一个数据集。
样本(sample):可以理解为一行数据,或者一张图片。就是组成数据集的单元。比如第二行的数据就是一个样本,也就是一个西瓜的数据。
**属性(attribute)或 特征(feature)**就是一行数据可能包含的不同类型的数据,比如西瓜的“根蒂”,“纹理”,”颜色“等,这些组成了属性或者说特征。数据集中的所有属性个数也被称作维数。就是上面数据集的列
属性值(attribute value):直观说就是西瓜的属性有哪些取值,比如颜色这个属性有“青绿”,“乌黑”,这些就是称为属性值。就是一列中所有取值的集合
样本空间(sample space):把数据集中的所有属性作为坐标轴,所有可能的属性的取值就包含在了样本空间中。就是数据集所有可能取值的集合。
训练(training) 或 学习(learning):从数据中学习模型,这里的模型可以简单理解为一个数学公式。也可以简单理解对于一个包含未知变量的方程,通过带入(自变量【数据】,因变量【标签】)来确定这一个公式,进一步利用公式,对于一个自变量【数据】,获得未知的因变量【标签】。
测试(testing):简单来说训练就是平时刷题总结知识点,考试出一套试卷,让你做,然后得出试卷成绩,从而判断你的学习效果。
有监督学习(supervised learning):每个【数据】都包括【标签】,就是说每道题都有答案,你可以根据自己做题的情况来调整自己的学习方向。代表算法为分类和回归。
无监督学习(unsupervised learning):只有数据没有标签,根据数据本身特征进行总结归纳,了解数据的内在规律,代表算法为聚类。
1.3 模型评估与选择
1.3.1 过拟合与欠拟合
首先介绍两个概念,“过拟合”和“包容”。
欠拟合:模型没有学习到训练集中的数据特征,对训练集的效果很差。主要原因是学习率太低或者模型的学习能力太差。
过拟合:模型对数据的拟合能力太强,即可以完美拟合训练数据,但过分追求完美,使得模型复杂,使得测试集失效,意味着模型泛化能力下降。要解决这个问题,可以添加更多数据或添加正则化项来约束模型
1.3.2 评估方法
(1)留出法
最简单也最常用的方法,也就是根据比例随机分配训练集和测试集。比如要求训练集和测试集的比例为8:2.那么就从数据集中随机选取80%的数据做训练集,用来训练模型,20%的数据用来测试模型的性能,常见的做法为将大约~
(2)交叉验证法
也叫K折交叉验证法(K-fold cross validation)。就是把数据集分为K分,把K份按照顺序依次选取一份作为测试集。其余数据作为训练集测试模型结果,将K分结果求和求均值,进而获得模型的性能指标。
(3)自助法
从m个样本的数据集又放回的选取m个样本,其中出去重复的样本,从而获得理论上获得的数据来训练,其余数据用作测试。这种方法在数据集较小,难以有效划分训练、测试集时很有用,此外,自助法能从数据集中产生不同的训练集,这对集成学习有很大好处,到那时它该改变了数据集的初始分布,会引入估计误差。
1.4 调参
大多数学习算法都有超参数,这意味着它们需要手动调整,而这些值通常是凭经验选择的。然后,对于训练好的模型的内部参数,可以从数据集中划分出一个验证集来指导模型的训练方向。选择和调整基于验证集的性能。
1.5 损失函数
也可以称为误差函数,即模型的预测值与实际值的差距,我们自然需要它们之间的差距尽可能小。因此,需要构造一个损失函数来计算差距,反映模型训练的效果。
常见的损失函数包括均方误差、均方根误差和平均绝对误差。
均方误差
均方根误差
平均绝对误差
1.6 评价指标
| 模型判定推荐的 | 模型判定不推荐的 | |
|---|---|---|
| 测试集中被推荐的(被检索到) | True positives(TP 正类判断为正类)(搜到的也想要的) | False positives(FP 负类判断为正类)(搜到的但没用的) |
| 测试集中不被推荐的(未被检索到) | False negatives(FN 正类判断为负类)(没搜到,然而实际想要的 | True negatives(TN 负类判定为负类)(没搜到也没用的) |
这个表是机器学习中最常见的混淆矩阵,用来判断模型的好坏。
2.3.1.2 具体例子分析
让我们假设一个特定的场景作为示例。
假如某个班级有男生80人,女生20人,共计100人.目标是找出所有女生.
某人挑选出50个人,其中20人是女生,另外还错误的把30个男生也当作女生挑选出来了.
作为评估者的你需要来评估(evaluation)下他的工作。
我们需要先需要定义TP,FN,FP,TN四种分类情况。
根据前面的例子,我们需要从一个班级的人中找到所有女孩。如果把这个任务看成一个分类器,那么我们需要的是女孩,而男孩不是,所以我们称女孩为“正类”,称男孩为“负类”。
| 相关(Relevant),正类 | 无关(NonRelevant),负类 | |
|---|---|---|
| 被检索到(Retrieved) | TP=20 true positives(TP 正类判定为正类,例子中就是正确的判定”这位是女生”) | FP=30 false positives(FP 负类判定为正类,“存伪”,例子中就是分明是男生却判断为女生) |
| 未被检索到(Not Retrieved) | FN=0 false negatives(FN 正类判定为负类,“去真”,例子中就是,分明是女生,这哥们却判断为男生–梁山伯同学犯的错就是这个) | TN=50 true negatives(TN 负类判定为负类,也就是一个男生被判断为男生) |
通过这张表,我们可以很容易得到例子中这几个分类的值:TP=20,FP=30,FN=0,TN=50。
2.3.1.3 显示反馈数据分析
我们可以通过计算模型分类的准确率,和召回率进来通过计算F-Measure的值来对模型分类的好坏进行评价。
下面结合例子中这几个分类的值:TP=20,FP=30,FN=0,TN=50介绍准确率,召回率,和F-measure的概念与计算方法。
1.准确率
准确率(precision)又称“精度”,“正确率”。的公式是,它计算的是所有被检索到的item(TP+FP)中,“应该被检索到的item(TP)”占的比例。
在例子中就是希望知道分类得到的所有人中,正确的人(也就是女生)占有的比例.所以其precision也就是40%(20女生/(20女生+30误判为女生的男生)).
2.召回率
召回率(recall)又称“查全率”的公式是,它计算的是所有检索的tem(TP)占所有”应该被检索到的item(TP+FN)”的比例。
在例子中就是希望知道此君得到的女生占本班中所有女生的比例,所以其recall也就是100%(20女生/(20女生+ 0 误判为男生的女生))
3. 准确率与召回率的关系
虽然“precision”和“recall”之间没有必然的关系(从上式可以看出),但在大规模数据集中,这两个指标是相互制约的。
由于“检索策略”并不完善,当期望检索到更多相关文档时,当“检索策略”放松时,往往伴随着一些不相关的结果,从而影响准确率。
当你想从检索结果中删除不相关的文档时,必须使“检索策略”更加严格,这也会使一些相关文档不再被检索,从而影响召回率。
大规模数据集的所有检索和选择都涉及“召回率”和“准确率”两个指标。由于这两个指标相互制约,我们通常根据自己的需要为“检索策略”选择合适的度数,不能太严格也不能太松,在查全率和查准率之间寻求平衡。这种平衡是由特定需求决定的。
4. F-Measure值
F-Measure又称为F-Score是一种统计量,是IR(信息检索)领域的常用的一个评价标准,常用于评价分类模型的好坏。它的计算公式为,其中β是参数 , R是召回率(recall)P是准确率(precision)。当参数β=1时,就是最常见的F1-Measure了:
,此时F1综合了P和R的效果,当F1较高时则能说明试验方法比较有效。
二、python代码实现
作者水平有限,如有错误请指教。
2.1 sklearn 中的性能指标
accuracy_score:精度
precision_score:查准率
recall_score:查全率
f1_score:F1指标
roc_auc_score:ROC曲线AUC指标
confusion_matrix:混淆矩阵
# !/usr/bin/env python
# @Time:2022/3/15 21:20
# @Author:华阳
# @File:1.py
# @Software:PyCharm
# accuracy_score的参数
# precision_score的参数
# recall_score的参数
# y_true:为样本真实标签,类型为一维的ndarray或者list
# y_predict:为模型预测标签,类型为一维的ndarray或者list
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,confusion_matrix
import numpy as np
from sklearn.metrics import roc_auc_score
y_true = [0, 0, 1, 1]
y_predict = [1, 0, 1, 0]
print("正例的准确率为:",accuracy_score(y_true, y_predict))
print("查准率为:",precision_score(y_true, y_predict))
print("查全率为:",recall_score(y_true, y_predict))
print("F1指数为:",f1_score(y_true, y_predict))
print("混淆矩阵为:",confusion_matrix(y_true,y_predict))
# y_true为真实标签
# y_score为预测为Positive的概率
y_true = np.array([0, 0, 1, 1])
y_score = np.array([0.1, 0.4, 0.35, 0.8])
print("ROC曲线auc指标",roc_auc_score(y_true, y_score))
结果:
正例的准确率为: 0.5
查准率为: 0.5
查全率为: 0.5
F1指数为: 0.5
混淆矩阵为: [[1 1]
[1 1]]
ROC曲线auc指标 0.75
文章出处登录后可见!