Topsis优劣解距离法用于求解 [样本 – 指标] 类型的数据,其行标签为样本序号,列标签为指标名称,将其 shape 记为 [sample, feature]
原始的 Topsis 是默认所有指标的权重相等,如果有四个指标,则权重向量是 [0.25 0.25 0.25 0.25]
本文将会讲解 熵权法、指标正向化、样本评分 的代码 (基于 numpy)
熵权法
熵权法的输入是 shape 为 [sample, feature] 的矩阵,输出是 shape 为 [feature, ] 的权值
- 原始输入:origin -> 使各列向量和为1 -> proba
- info:信息量 -ln(proba)
- entropy:信息熵 (Σ proba * info) / ln(n)
- redu:冗余度 1 – entropy
该指标对应的权重是其冗余度占所有冗余度总和的比例。
def comentropy(origin):
''' 熵权法
proba: 概率
info: 信息量 -ln(proba)
entropy: 信息熵 (Σ proba * info) / ln(n)
redu: 冗余度 1 - entropy'''
num = origin.shape[0]
proba = origin / origin.sum(axis=0).reshape(1, -1)
info = -np.log(proba, where=proba > 0)
entropy = (proba * info).sum(axis=0) / np.log(num)
redu = 1 - entropy
weight = redu / redu.sum()
return weight指数阳性
枚举每一列(指标向量),分别处理,最后一起归一化
输入是 shape 为 [sample, feature] 的原始矩阵,输出为 shape 为 [sample, feature] 的正向化矩阵
具体使用方法在后面
num = (int, float)
def positive(data, flags):
''' data:
行索引: 各方案
列索引: 各指标
flags: 指标类型
True: 效益型
False: 成本型
num: 中间型
[num, num]: 区间型
return: 正向化, 标准化矩阵'''
data = data.copy()
# 拷贝张量
for idx, flag in enumerate(flags):
col = data[:, idx]
if isinstance(flag, bool):
if not flag:
data[:, idx] = col.max() - col
# 成本型指标
elif isinstance(flag, num):
col = np.abs(col - flag)
data[:, idx] = 1 - col / col.max()
# 中间型指标
elif len(flag) == 2:
left, right = sorted(flag)
if isinstance(left, num) and isinstance(right, num):
col = (left - col) * (col < left) + (col - right) * (col > right)
data[:, idx] = 1 - col / col.max()
# 区间型指标
else:
raise AssertionError('区间型指标数据类型出错')
else:
raise AssertionError('出现无法识别的指标类型')
data /= (data ** 2).sum(axis=0) ** 0.5
return data样本分数
前向矩阵每列合成最大值的样本被认为是优秀样本,每列合成最小值的样本被认为是劣质样本。
计算加权欧几里得距离,得到每个样本到优等样本和劣等样本的距离,取到劣等样本的距离与两个距离之和的比值作为样本得分
输入是 shape 为 [sample, feature] 的正向化矩阵,输出是 shape 为 [sample, ] 的样本得分
def cal_score(pos, weight=None):
''' pos: 正向化, 标准化矩阵
weight: 权重向量
return: 样本得分'''
if np.all(weight is None):
length = pos.shape[1]
weight = np.ones([1, length])
# 当无权值要求,则各个指标权值相等
else:
weight = np.array(weight).reshape([1, -1])
# 使用指定的权值
weight /= weight.sum()
# 令权值和为1
worst = pos.min(axis=0)
best = pos.max(axis=0)
# 劣样本、优样本
dis_p = ((weight * (pos - best)) ** 2).sum(axis=1) ** 0.5
dis_n = ((weight * (pos - worst)) ** 2).sum(axis=1) ** 0.5
# 样本到劣样本、优样本的距离
score = dis_n / (dis_p + dis_n)
# 计算得分
return score.reshape(-1, 1)实战:评价水质
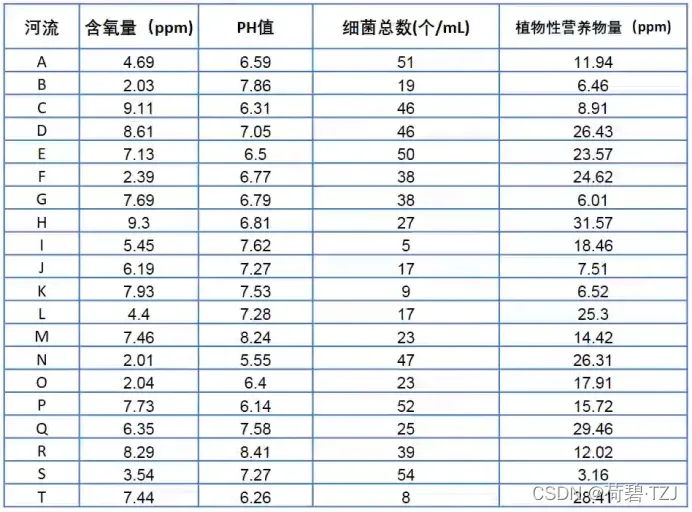
含氧量为效益性指标,pH 值为中间型指标,细菌总数为成本型指标,植物性营养物量为区间型指标 (处在 [10, 20] 区间内最好) —— 指标正向化函数的 flags 参数表示为:
[True, 7, False, (10, 20) ]
pos = positive(data, [True, 7, False, (10, 20)])
# 指标正向化
weight = comentropy(pos)
# 熵权法求指标权重
score = cal_score(pos, weight)
# 计算得分
index = np.argsort(score.T[0])
Ascii = reversed(index + 65)
# 将数值索引转化为 ASCII 码
print(" ".join(map(chr, Ascii)))
# 输出河流排名文章出处登录后可见!
已经登录?立即刷新