前言
yolov5的训练策略big big丰富,这也是yolov5涨分厉害的reason,目前yolov5的使用量也是非常大的,官网的star已经23.5k了,无论是在迁移学习还是实际场景的应用都是非常广泛的。之前参加比赛,发现好几页的选手都在使用yolov5,确实有必要梳理一下,yolov5的训练策略。感觉这些策略对以后自己实验帮助会很大,所以要细嚼慢咽,好了,不说了,走起开吃!!!!!!!!!
1. 训练预热——Warmup
1.1 what是Warmup
众所周知学习率是一个非常重要的超参数,直接影响着网络训练的速度核收敛情况。通常情况下,网络开始训练之前,我们会随机初始化权重,设置学习率过大会导致模型振荡严重,学习率过小,网络收敛太慢。那这个时候该怎么做呢?是不是有人会说,我前面几十个或者几百个epoch学习率设置小一点,后面正常后,设置大一点呢,没错这就是最简单的Warmup。
1.2 why用Warmup
我们可以把Warmup的过程想成,模型最开始是一个小孩,学习率太大容易认识事物太绝对了,这个时候需要小的学习率,摸着石头过河,小心翼翼地学习,当他对事物有一定了解和积累,认知有了一定地水平,这个时候步子再迈大一点就没问题了。
1.3 常见Warmup类型
1. Constant Warmup
在前面100epoch里,学习率线性增加,大于100epoch以后保持不变,整个过程如下如所示: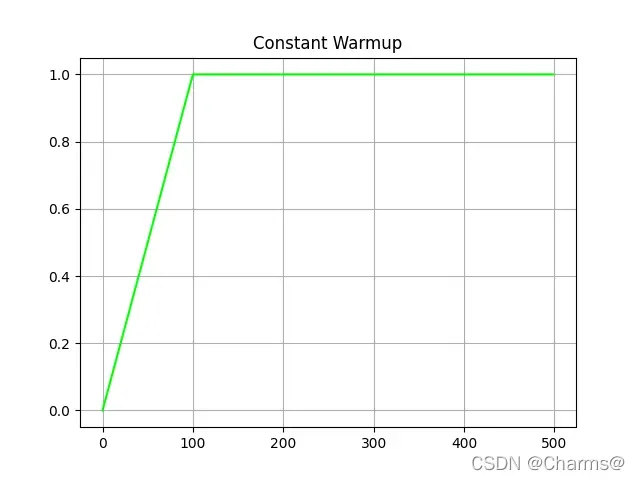
2. Linner Warmup
在前面100epoch里,学习率线性增加,大于100epoch以后保持线性下降,整个过程如下如所示: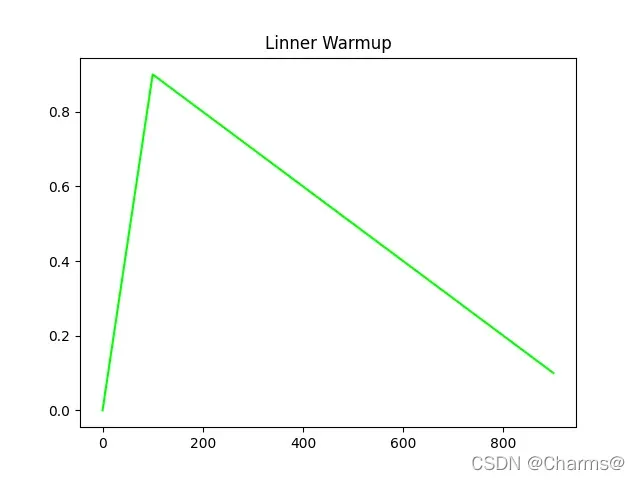
2. Cosine Warmup
在前面100epoch里,学习率线性增加,大于100epoch以后保持x余弦方式下降,整个过程如下如所示: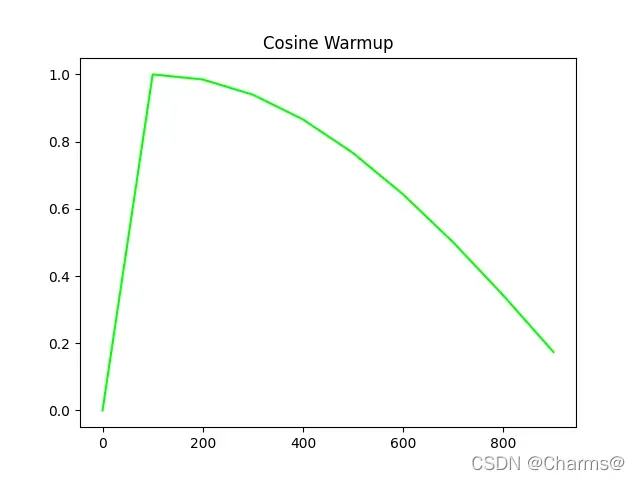
通常来说第三种Cosine Warmup使用地频率较多一点。
1.4 yolov5中的Warmup
1. 超参数设置
在yolov5中data/hyps/hyp.scratch-*.yaml三个文件中,都存在着warmup_epoch代表训练预热轮次,以这
hyp.scratch.scratch-med.yaml为例,如图超参数列表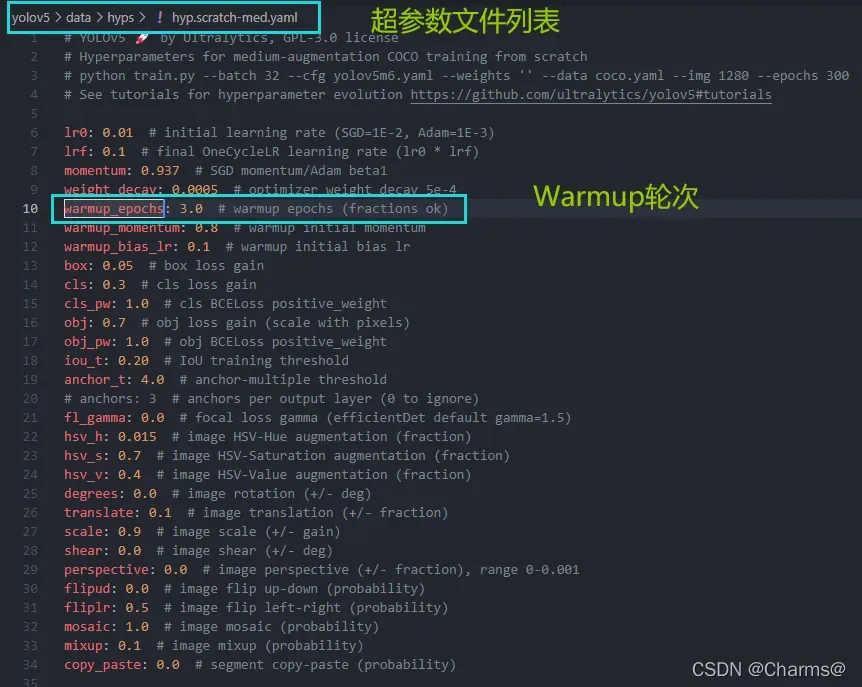
2. 训练转化
nb表示训练的类别数,例如coco数据集80类,在超参数列表中warmup_epochs=3,则nw = 3 * 80 = 240,所以热身训练240epoch, 这里要注意的是最少热身训练100次,所以设施epoch的时候最好大于100epoch,要不然热身都还没有做完,运动就结束了。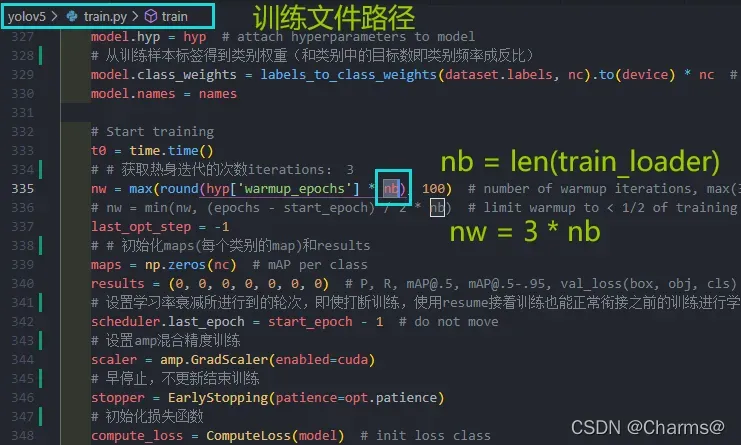
3.预热训练开始
yolov5的预测训练从这里开始,超参数的初始值和变化范围data/hyps/hyp.scratch-*.yaml给出来了,计算过程就在这里。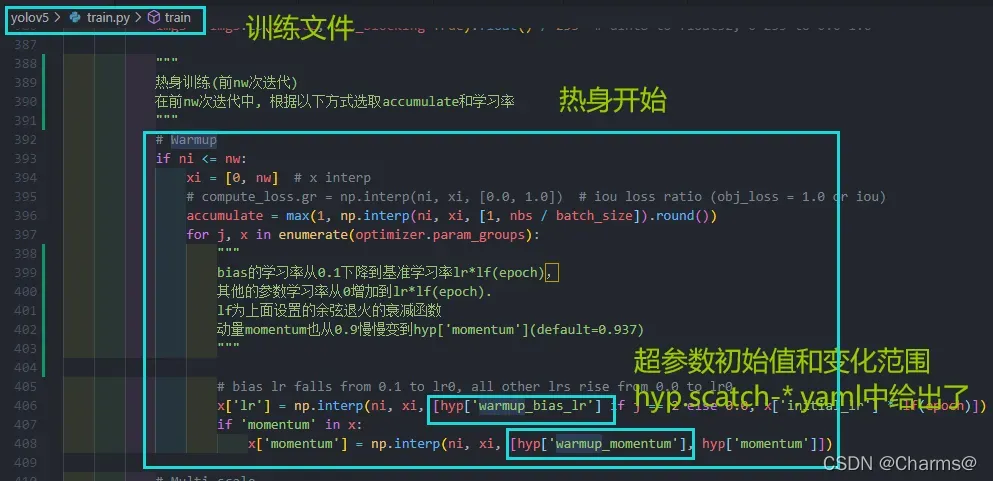
2. 自动调整锚定框——Autoanchor
2.1 what是anchor
anchor是指预定义的框集合,其宽度和高度与数据集中对象的宽度和高度相匹配。预置的anchor包含在数据集中存在的对象大小的组合,这自然包括数据中存在的不同长宽比和比例。通常在图像中的每一个位置预置4-10个anchor。
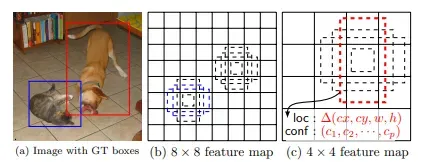
训练目标检测网络的典型任务包括:生成anchor,搜索潜在anchor,将生成的anchor与可能的ground truth配对,将其余anchor分配给背景类别,然后进行sampling和训练。
推理过程就是对anchor的分类和回归,score大于阈值的anchor进一步做回归,小于阈值的作为背景舍弃,这样就得到了目标检测的结果。
2.2 why用anchor
目标检测可以理解为回归+分类,怎么样最好的完成这个任务呢,是不是想到了用锚框,首先预设一组不同尺度不同位置的固定参考框,覆盖几乎所有位置和尺度,每个参考框负责检测与其交并比大于阈值 (训练预设值,常用0.5或0.7) 的目标,anchor技术将问题转换为”这个固定参考框中有没有认识的目标,目标框偏离参考框多远”,不再需要像传统的目标检测那样,挨个挨个不同大小的滑动,费时费力。正是anchor的出现把目标检测分为了anchor free和anchor base。
想要了解更多的anchor相关的知识可以查看连接:
目标检测Anchor的What/Where/When/Why/How
目标检测中的Anchor
2.1 yolov5默认锚定框
yolov5中预先设定了一下锚定框,这些锚框是针对coco数据集的,其他目标检测也适用,可以在models/yolov5.文件中查看,例如如图所示,这些框针对的图片大小是640640。这是默认的anchor大小。需要注意的是在目标检测任务中,一般使用大特征图上去检测小目标,因为大特征图含有更多小目标信息,因此大特征图上的anchor数值通常设置为小数值,小特征图检测大目标,因此小特征图上anchor数值设置较大。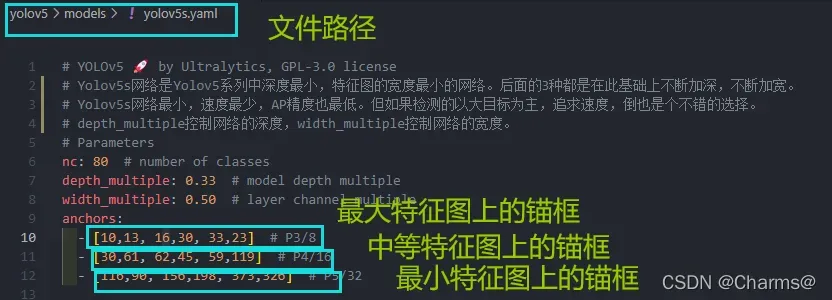
2.2 yolov5自动锚框
在yolov5 中自动锚定框选项,训练开始前,会自动计算数据集标注信息针对默认锚定框的最佳召回率,当最佳召回率大于等于0.98时,则不需要更新锚定框;如果最佳召回率小于0.98,则需要重新计算符合此数据集的锚定框。
在parse_opt设置了默认自动计算锚框选项,如果不想自动计算,可以设置这个,建议不要改动。
在train.py中设置检查锚框是否符合要求,主要使用的函数是check_anchor。
check_anchor函数的流程大概是:先判断锚框是否符合要求(判断条件bpr / aat,大于0.98就不会更新),然后利用k-mean聚类更新锚框。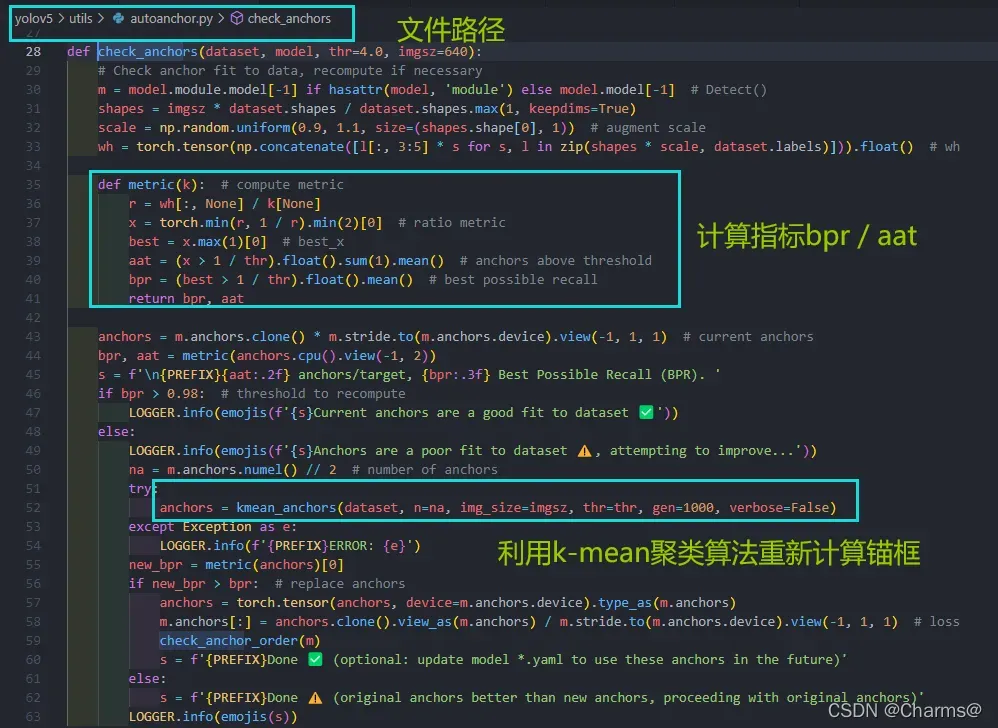
3. 超参数进化——遗传算法调优(GA)
3.1 what是GA
遗传算法利用种群搜索技术将种群作为一组问题求解,通过对当前种群进行相似的生物遗传环境因素的选择、交叉、变异等一系列遗传操作,生成新一代种群。逐渐优化种群以包含近似最优解的状态。
3.2 why用GA
遗传算法调优可以找到优化问题的全局最优解。优化结果与初始条件无关。该算法独立于解域,具有较强的鲁棒性。适用于解决复杂的优化问题,应用广泛。
3.3 yolov5超参数进化
yolov5使用遗传超参数进化,提供的默认参数是通过在COCO数据集上使用超参数进化得来的。由于超参数进化会耗费大量的资源和时间,如果默认参数训练出来的结果能满足你的使用,使用默认参数是不很nice的选择。yolov5/data/hyp.scratch-*.yaml有三个文件共大家选择,这里使用hyp.scratch-low.yaml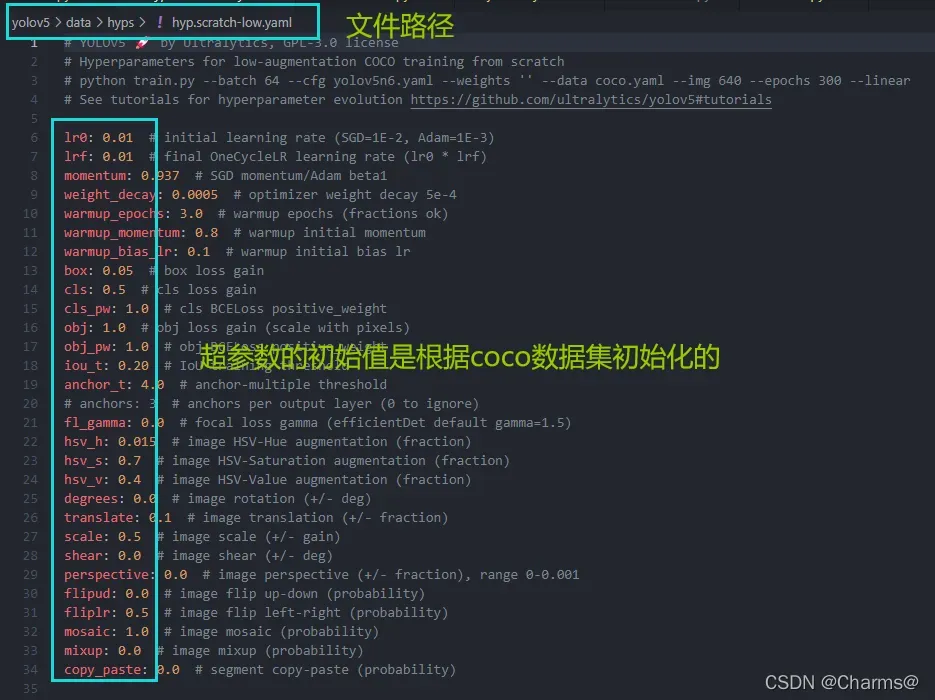
train.p文件中parse_opt函数可以设置是否经行超参数优化。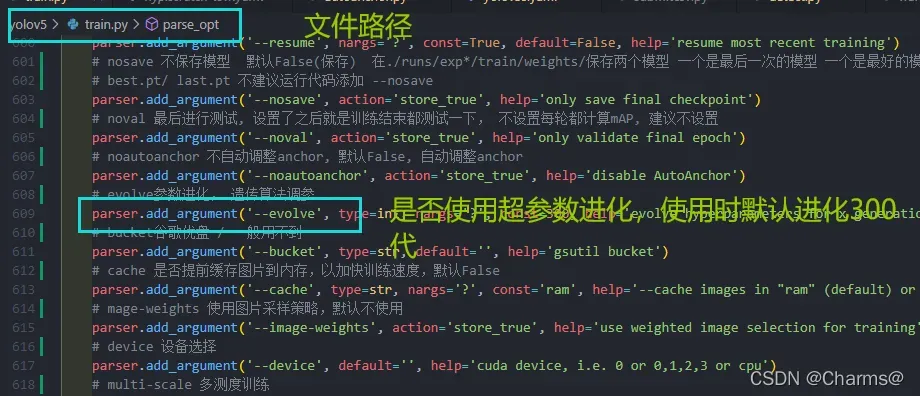
超参数进化开始,使用fitness寻求最优化值。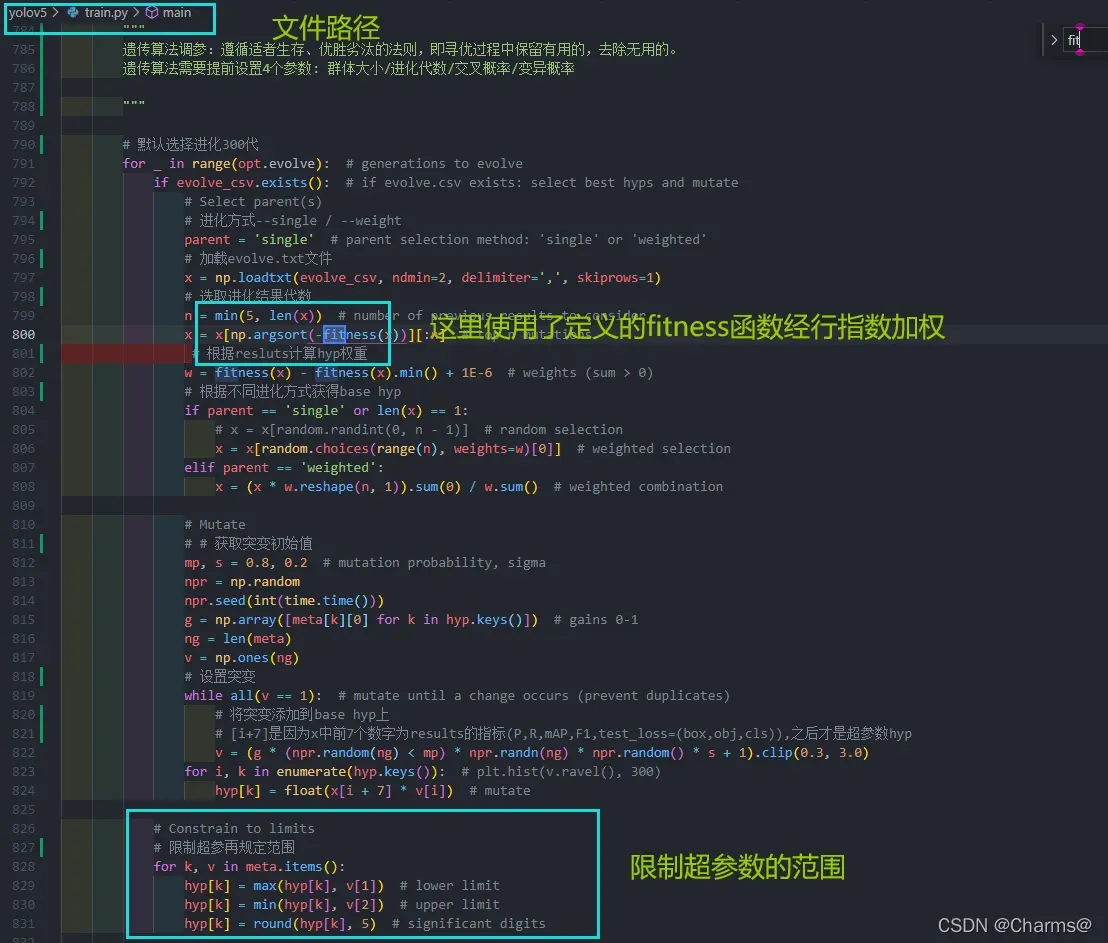
4. 冻结训练——Freeze training
4.1 what是冻结训练
冻结训练是迁移学习常用的方法,当我们在使用数据量不足的情况下,通常我们会选择公共数据集提供权重作为预训练权重,我们知道网络的backbone主要是用来提取特征用的,一般大型数据集训练好的权重主干特征提取能力是比较强的,这个时候我们只需要冻结主干网络,fine-tune后面层就可以了,不需要从头开始训练,大大减少了实践而且还提高了性能。
4.2 how弄冻结训练
冷冻训练的好处不言而喻。下面简单介绍一下冻结训练的步骤。通常的做法是:
1.定义一个冻结层, 冻结之前的学习率和bs可以设置大一点。
2.设置不更新权重param.requires_grad = False
整个过程如下
# 冻结阶段训练参数,learning_rate和batch_size可以设置大一点
Freeze_Epoch = 100
Freeze_batch_size = 32
Freeze_lr = 1e-3
# 解冻阶段训练参数,learning_rate和batch_size设置小一点
UnFreeze_Epoch = 100
Unfreeze_batch_size = 16
Unfreeze_lr = 1e-4
# 可以加一个变量控制是否进行冻结训练
Freeze_Train = True
# 冻结一部分进行训练
batch_size = Freeze_batch_size
lr = Freeze_lr
start_epoch = Init_Epoch
end_epoch = Freeze_Epoch
if Freeze_Train:
for param in model.backbone.parameters():
param.requires_grad = False
# 解冻后训练
batch_size = Unfreeze_batch_size
lr = Unfreeze_lr
start_epoch = Freeze_Epoch
end_epoch = UnFreeze_Epoch
if Freeze_Train:
for param in model.backbone.parameters():
param.requires_grad = True
4.3 yolov5冻结训练
yolov5的train.py文件中提供了冻结训练选项,在parse_opt函数中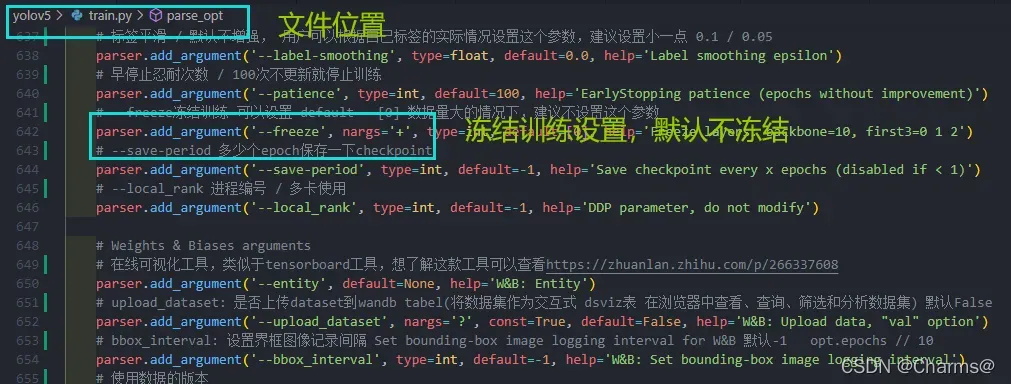
yolov5s.yaml文件中可以查看到0-9层是backbone,因此在设置冻结层的时候注意不能超过9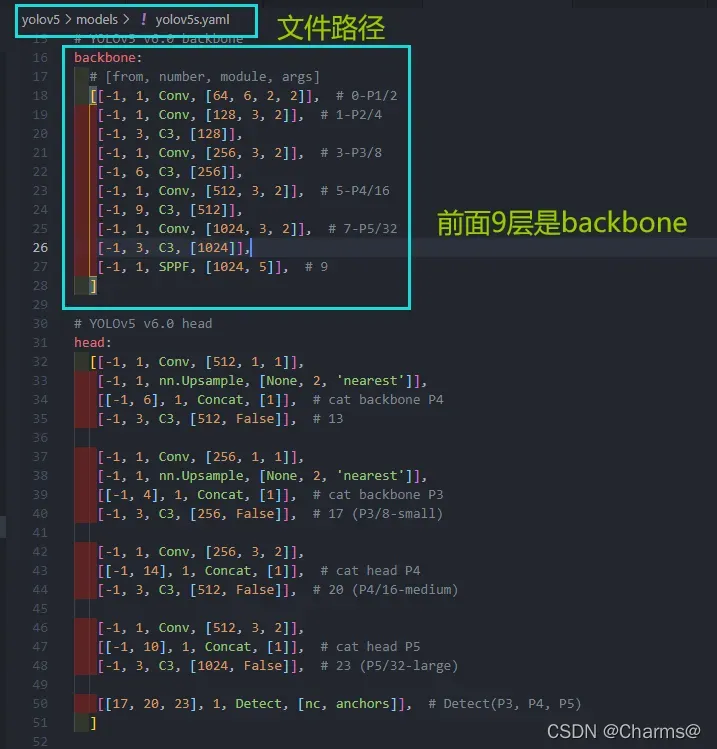
冻结训练开始部分代码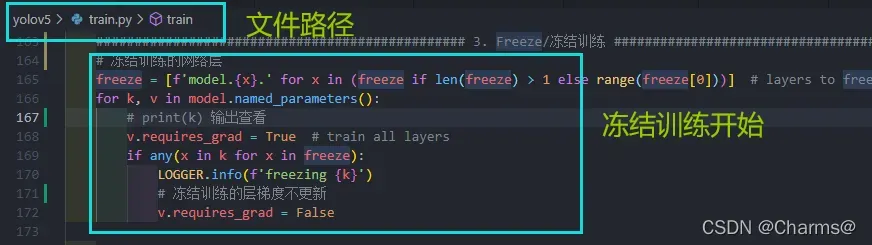
这里提yolov5冻结效果查看的网站Freezing Layers in YOLOv5
5. 多尺度训练——multi-scale training
5.1 what是multi-scale training
多尺度训练经常出现在比赛中,是一种行之有效的提高表现的方法。输入图像的大小对检测模型的性能有很大的影响。在基础网络部分,往往会生成比原图小几十倍的特征图,这使得检测网络难以捕捉到小物体的特征描述。通过输入更大尺寸的图像进行训练,可以在一定程度上提高检测模型对物体尺寸的鲁棒性。
知乎这里有个讨论:目标检测中的多尺度训练/测试
多尺度训练是指设置几种不同的图片输入尺度,训练时每隔一定iterations随机选取一种尺度训练。这样训练出来的模型鲁棒性强,其可以接受任意大小的图片作为输入,使用尺度小的图片测试速度会快些。
先了解更多多尺度训练/测试的方法可以查看这篇文章目标检测中的多尺度检测方法
5.2 yolov5多尺度训练
在train.py文件中提供了多尺度训练的选项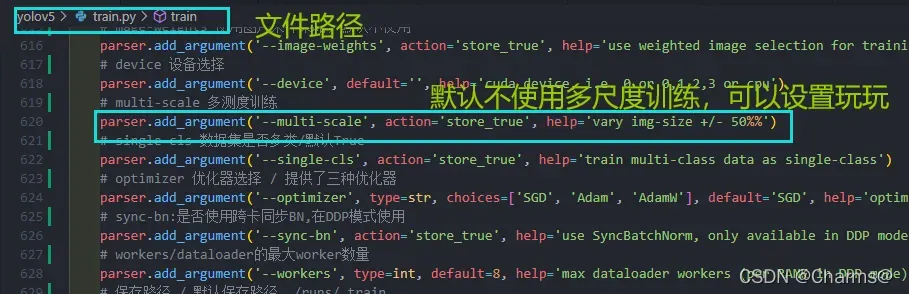
在train.py文件这里是多尺度训练开始的位置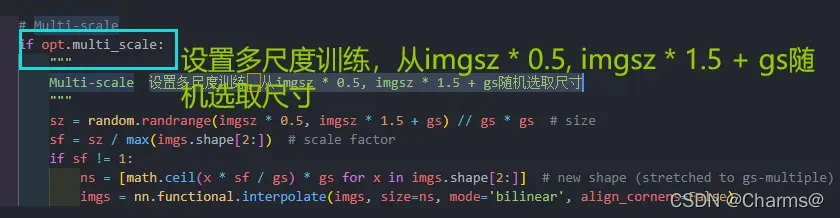
6. 加权图像策略
6.1 图像加权策略
图像加权策略可以解决样本不平衡问题。具体操作步骤如下:
根据样本类型的分布,采用不同的图像调用频率方法求解。
1、读取训练样本中的GT,保存为一个列表;
2、计算训练样本列表中不同类别个数,然后给每个类别按相应目标框数的倒数赋值,数目越多的种类权重越小,形成按种类的分布直方图;
3、对于训练数据列表,训练时按照类别权重筛选出每类的图像作为训练数据。使用random.choice(population, weights=None, *, cum_weights=None, k=1)更改训练图像索引,可达到样本均衡的效果。
6.2 yolov5图像加权策略
在yolov5中的train.py文件中存在着图像加权策略选项,如函数parse_opt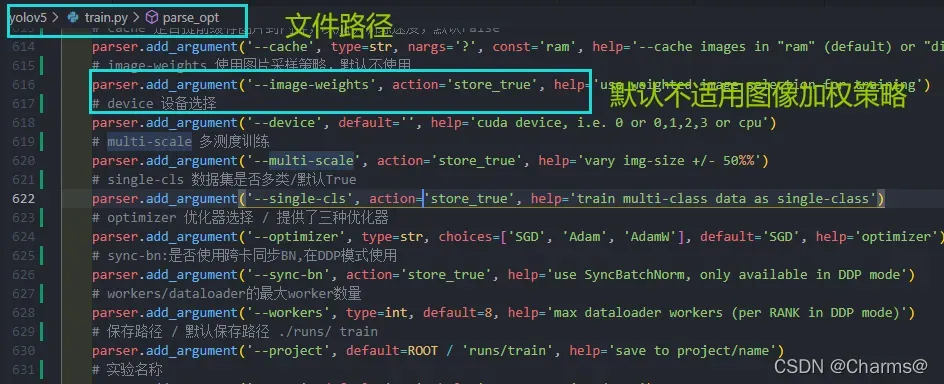
在train.py文件训练部分,这个位置开始使用图像加权
获取类权重的函数如下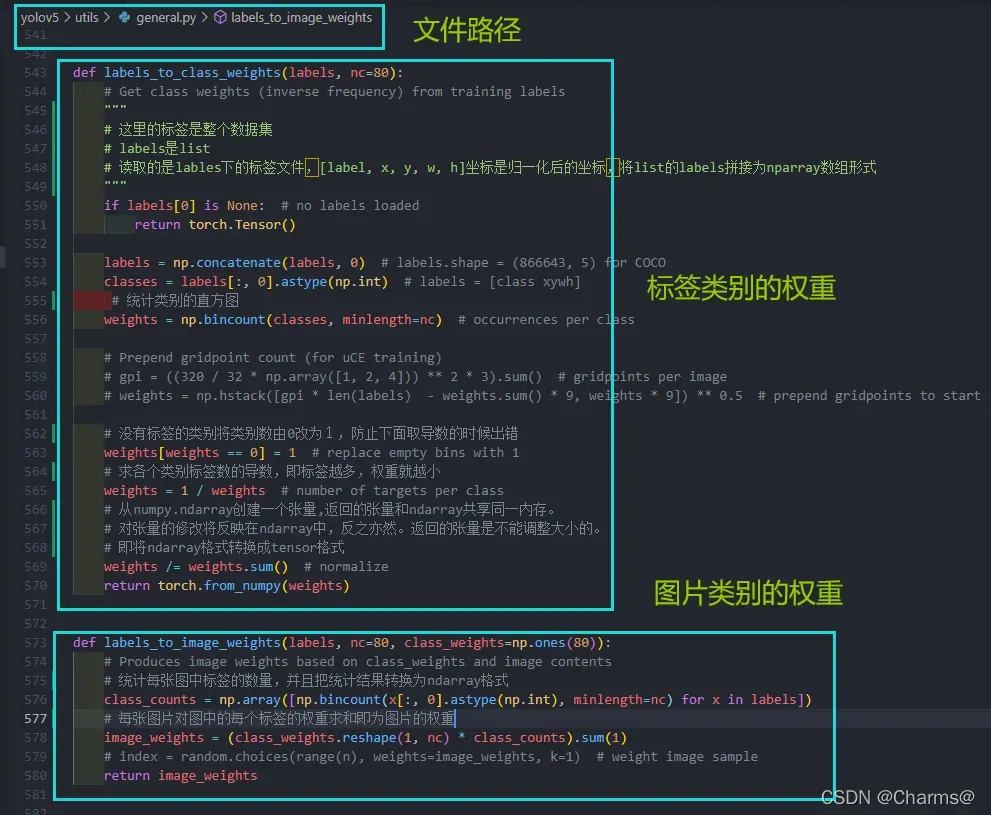
————有点欠缺,后面会补上———— — ———-
7. 矩形训练
8. 标签平滑
9. 余弦退火
10. 早停止
11. 分布式训练
12. 跨卡同步BN
13. 断点训练
文章出处登录后可见!