



论文快速指南:
SRCNN:Learning a Deep Convolutional Network for Image Super-Resolution
DCSCN:Fast and Accurate Image Super Resolution by Deep CNN with Skip Connection and Network in Network
SRDenseNet:Image Super-Resolution Using Dense Skip Connections
SRGAN:Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
在这里顺便推荐一个博主:Ton10对论文的理解鞭辟入里,对论文的描述非常细节。
SRCNN
SRCNN:Learning a Deep Convolutional Network for Image Super-Resolution
SRCNN是深度学习在图像超分辨率上的开篇之作!,证明了深度学习在超分领域的应用可以超越传统的插值等办法取得较高的表现力。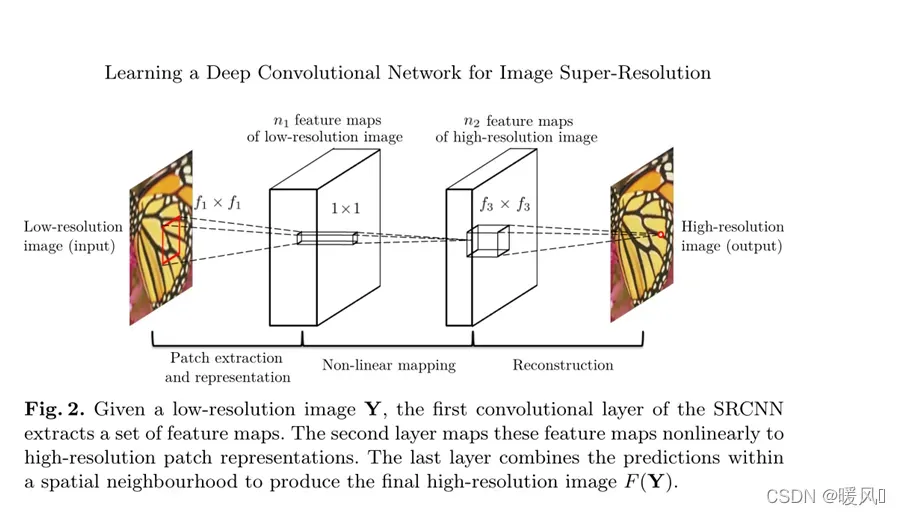
SRCNN网络非常简单,作者将其分为三部分,特征提取层 – 非线性映射层 – 网络重建层。
在上图中的网络模型之前,对原始图像进行预处理(双三次插值),得到一张低分辨率的图像作为网络的输入。
特征提取层:提取卷积核大小为
非线性映射层:
网络重建层:
Note:
!!!前两层的卷积后都用ReLU函数进行激活。但第三层不需要激活函数,这里体现的是一个平均的思想,主要利用的是乘加操作。
Loss:(MSE)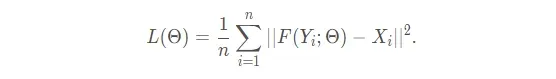
过滤器分析:
上图是特征提取层滤波器的学习可视化图,在91张图片的训练结果,其中up-scale-factor=2。
图像a、f:类似于高斯分布。
图像b、c、d:类似于边缘检测。
图像e:类似于纹理检测。
休息:一些坏死的内核参数。



DCSCN
DCSCN:Fast and Accurate Image Super Resolution by Deep CNN with Skip Connection and Network in Network
DCSCN介绍了一种轻量级全CNN网络的Super-Revolution算法。
文章特点:使用了skip connection、ResNet结构、并行结构。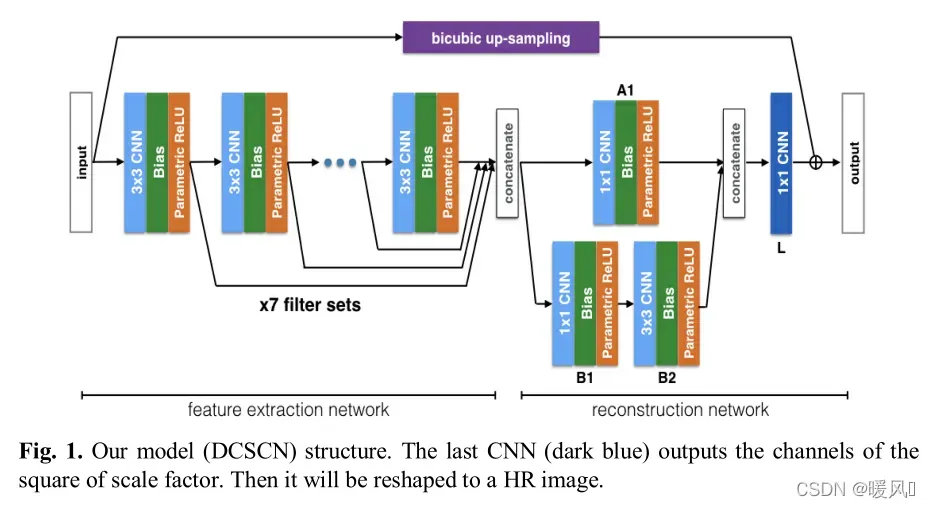
DCSCN整体模型可以分为三个部分,特征提取网络 – 重建网络 – 双三次插值上采样
特征提取网络:
作者直接从原始图像中提取特征,之前的方法先进行上采样,再提取像素特征。事实上,这些信息是多余的。
使用了7个3 × 3CNN网络进行特征提取输出feature map,通过skip connection连接将不同深度的图像特征,传送到重建网络。
ResNet网络作用主要是两个:防止梯度消失;保留全局信息,缩减图像通道数,减小网络复杂度。
双三次插值上采样:
在网络外对原始图像做一个双三次插值上采样,与重建网络后的结果相加输出高分辨率图像SR。
双三次插值相当于作为一个正则化项去迫使网络学习LR与HR之间的差异,减小LOSS。

本文方法最大的优点是计算复杂度低,整体网络结构简单。在这种轻量级案例中实现最佳或次优结果也足以证明该方法的成功。
SRDenseNet
SRDenseNet:Image Super-Resolution Using Dense Skip Connections
文章特点,使用了DenseNet、skip connection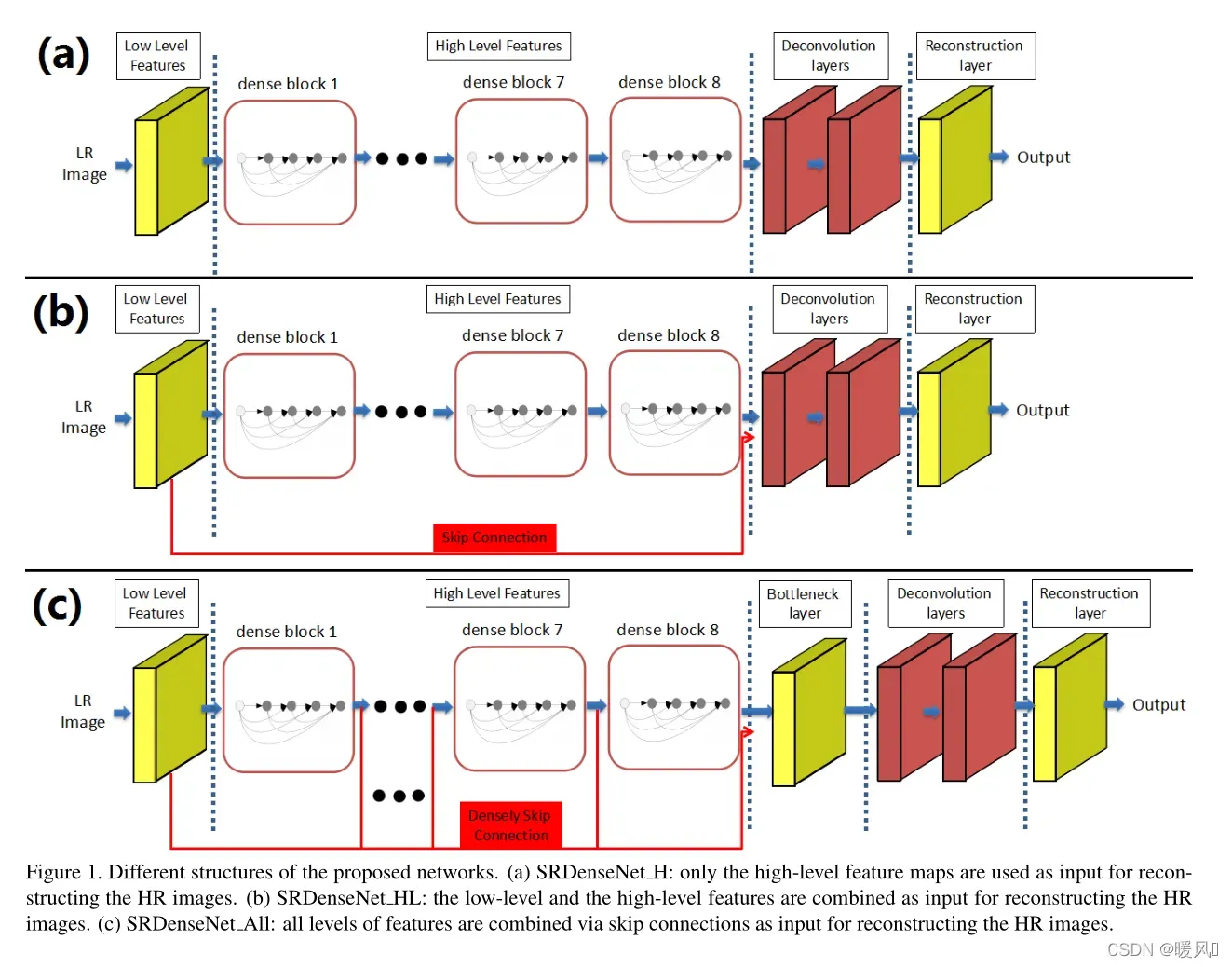
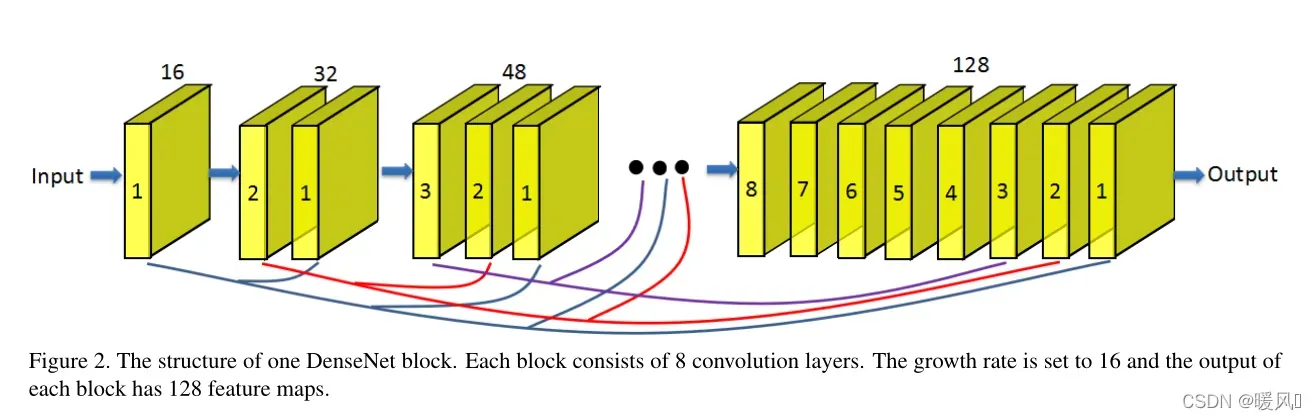


SRDenseNet和DCSCN结构非常类似。都是使用了skip connection,主要结构都是一个特征提取加反卷积重建。
输入是从
高级特征特征提取:
使用了8个dense块,每个块输出都是128个feature map。每个dense block中有8个卷积层,growth rate为16。在dense块中和dense块间都使用了skip connection,可以学习到更多高低层互补的信息。
瓶颈层:
在上图的(c)中使用了1×1内核的卷积层用作瓶颈层,以减少输入特征映射的数量,特征图的数量减少到256个。提高了模型的紧凑性和计算效率。
反卷积层:
使用了两个
加速了重建过程,整个过程在LR空间进行,如果放大因子为
重构层:有一个
LOSS:(MSE)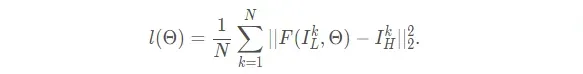
本文研究并比较了三种不同类型的网络结构。
如图1(a)所示,只有顶层的特征映射被用作重构HR输出的输入,将该结构表示为SRDenseNet_H。
如图1(b)所示,网络中引入了一个跳跃连接,以连接低级和高级特征,称之为SRDenseNet_HL。
如图1(c)所示,使用密集跳跃连接将所有卷积层生成的特征映射拼接起来进行SR重建,并将该方法表示为SRDenseNet_all。默认SRDenseNet为该种结构。
在后续的实验中,也证明了第三个比前两个带来更好的表现力,这证明了不同深度层的特征所包含的信息是互补的。

SRGAN
SRGAN:Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
这篇文章使用了GAN结构,并且发现PSNR不能完美的作为图像清晰度的评价指标。提出了一种新的损失函数:感知损失。
文章首先提出一种新的SRResNet网络,在PSNR指标上达到了SOTA。
在SRGAN中,使用SRResNet作为生成网络。实验证明确实达到了很好的感知效果。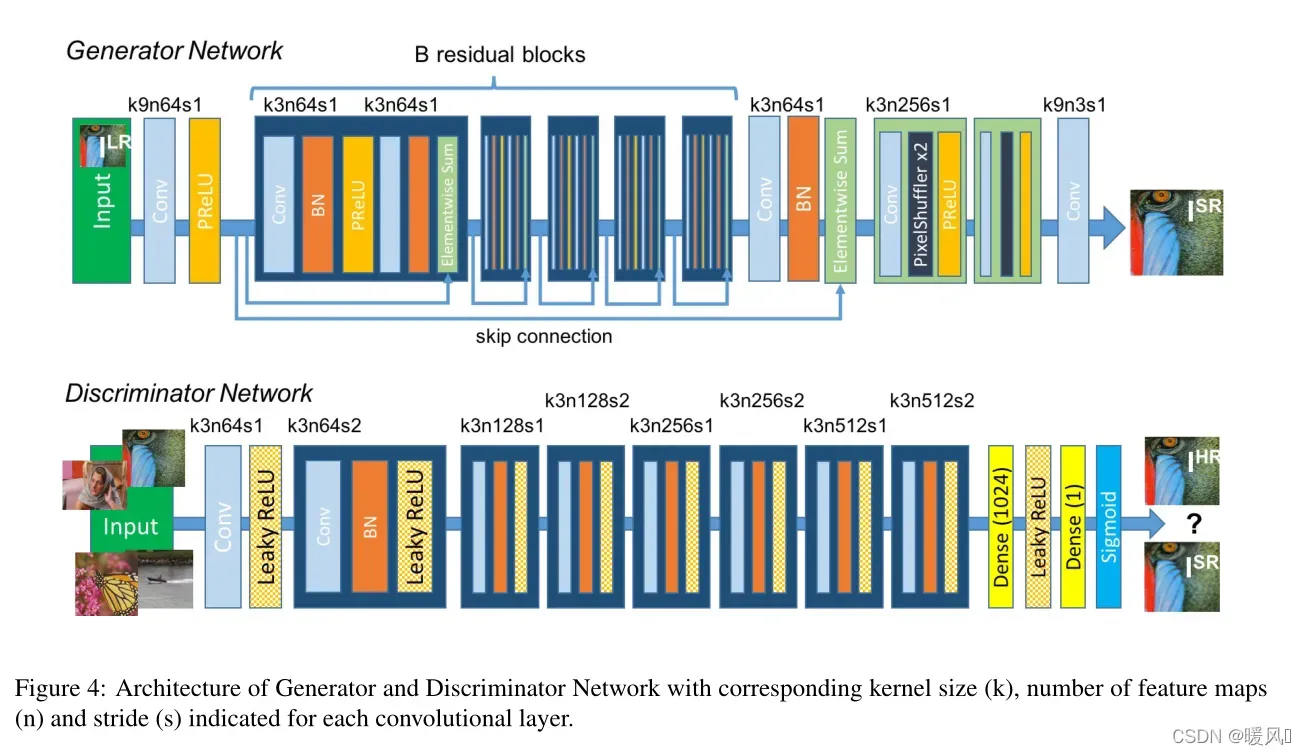
SRResNet网络结构和SRDenseNet非常之像,用ResNet替换了DenseNet。
首先先对这5种变体模型进行说明:
文章统共提出了五种变体模型(使用了不同的loss函数),对其进行了比较:

SRResNet(MSE-based):以MSE为内容损失函数,没有对抗损失,后面的SRResNet就是指MSE-based。
SRResNet(VGG22-based):以VGG22损失函数为内容损失,没有对抗损失。
SRGAN(MSE-based):以MSE为内容损失函数,外加对抗损失。
SRGAN(VGG22-based):以VGG22损失函数为内容损失,主要用于捕获低层细节,外加对抗损失。
SRGAN(VGG54-based):以VGG54损失函数为内容损失,主要用于捕获高层细节,外加对抗损失,后面的SRGAN指的就是以VGG54为内容损失函数。
因为文章质疑了PSNR的评估能力,所以使用了MOS图像评价指标(人为打分)。
实验中证明了SRResNet在PSNR指标上达到了SOTA;但SRGAN在MOS指标上比SRResNet更好。
接下来看下SRGAN的细节:
目标函数: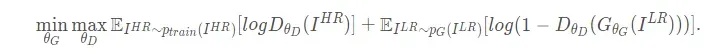

关注两个地方:
- 生成网络使用的是SRResNet的结构,判别网络是类似于VGG网络的结构。
- 生成网络的loss使用的是感知损失:由内容损失(文中取MSE或者VGG损失) + 一定比率的对抗损失(GAN网络本身就有的损失函数)组成。判别网络损失使用原有的损失函数。
也正是因为使用了不同的损失函数,才有了上述五种变体。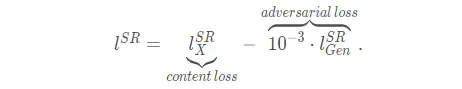

待续…
最后祝大家科研顺利,身体健康,万事如意~
文章出处登录后可见!