前言
卷积神经网络(ConvNets或CNNs)作为一类神经网络,托起cv的发展,本文主要介绍卷积神经网络的另外一个操作——池化操作,其原理,并以小白视角,完成池化从0到1的numpy实现。
1
随着小白一系列的入坑,今天的反击开始。错过其他专柜,请关注公众号无敌张大道领取。
池化一词开始视觉机制,指的是资源的合并、整合,英文为pooling,中文直译过来即为池化。池化操作(也称为子采样或下采样)主要为了降低每个特征图的维数,可以减少参数矩阵的尺寸,从而减少最后输出的数量,但保留了最重要的信息。池化可以有不同的类型:MaxPooling、AveragePooling、SumPooling等。
2
以Max Pooling最大池化为例,我们先定义一个滑动窗口(如一个 2×2 窗口)并从该窗口所对应的特征图中获取最大元素作为输出特征对应位置值,再以stride=2的步长,从左到右,自上而下滑动到下一个位置,并如下图所示: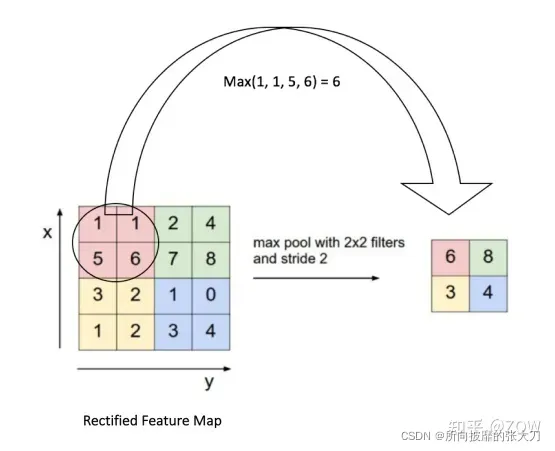
总体操作如下:一个5×5的特征,以3×3的滑窗滑动,每次的步长为1,最大池化和平均池化的结果如下图,AveragePooling、SumPooling的操作基本一致,AveragePooling则是计算每个滑窗的平均值,SumPooling计算每个滑窗的和,操作简单但是效果明显,而sumPooling 一般不用于图像中,主要原因是AveragePooling就是sumPooling 的一种表现形式,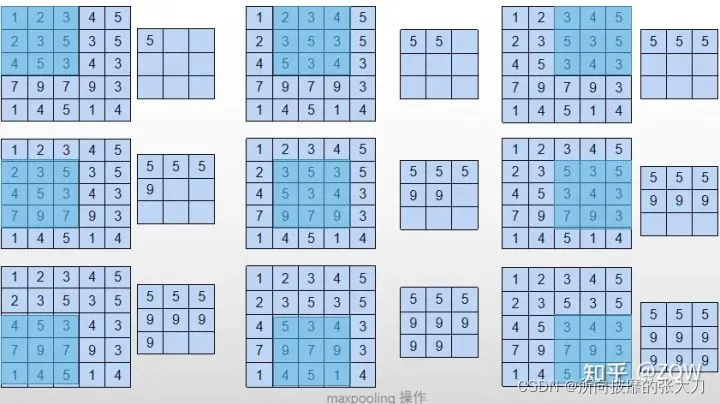
对每个特征图,有n个通道,池化操作是在每个通道上做操作,即输入3层特征图,输出也是三层,如下图所示(这里自己脑洞补下,Pooling是不是也算是一种深度可分离卷积,只是这里的pooling是静态的,特征值为固定的,不参与训练)。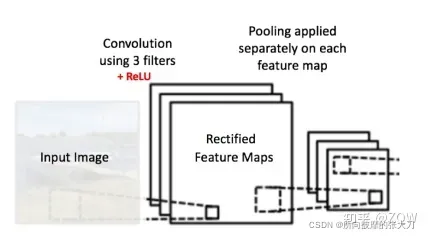
下图是使用maxPooling和SumPooling后,特征图的变化,通常认为如果选取区域均值,往往能保留整体数据的特征,较好的突出背景信息;如果选取区域最大值(max pooling),则能更好保留纹理特征: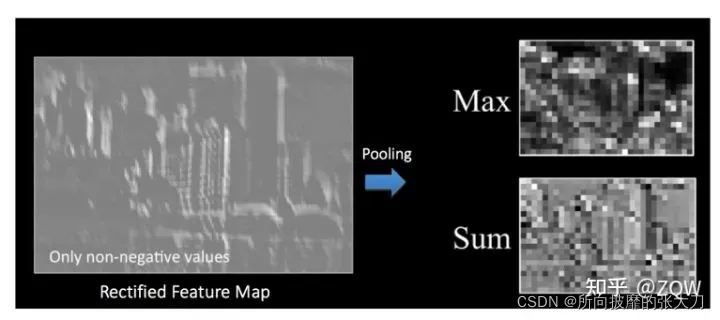
当然还有其他各种pooling操作:
此外还有一些变种如weighted max pooling,Lp pooling,generalization max pooling,还有global pooling。
- stochastic pooling:元素按照其概率值大小随机选择,元素被选中的概率与其数值大小正相关,这就是一种正则化的操作了。
- mixed pooling:在max/average pooling中进行随机选择。
- Data Driven/Detail-Preserving Pooling: 上面的这些方法都是手动设计,而现在深度学习各个领域其实都是往自动化的方向发展。我们前面也说过,从激活函数到归一化都开始研究数据驱动的方案,池化也是如此,每一张图片都可以学习到最适合自己的池化方式。
这样,pooling的操作简单方便,好处多多:
- 可以逐步减少feature map的大小,当feature map 越小时,对应原图的感受野就越大;如maxpooling操作图所示,一个5×5大小的图片,卷积操作后feature map后的大小是5×5,pooling操作后的大小是3×3,那对于每个元素来说,以前对应着一个像素点,现在对应着3×3的原图视野,感受野增大。
- 同时,在默认的多层卷积操作后,模型的数据量实际上是过拟合的,减少了网络参数和计算的数据量,可以有效防止过拟合;
- 另外在很多文章里说池化具有平移不变性,因为pooling不断地抽象了区域的特征而不关心位置,所以pooling一定程度上增加了平移不变性,这里和卷积的操作有异曲同工,从另一方面看,除非感受野够大,否则conv等只能学习局部信息,而缺乏全局观,所以后面会有transformer等在cv上的崛起。。这是后话,暂且不提。
3
pooling池化算子的实现torch、tensorflow等框架中均已封装好,拿来即用,非常方便,这边是方便自己理解,通过numpy 从0实现pooling。思路如下,同样考虑继承Layers类,Layer类的代码参见conv算子中Layer类的实现。pooling池化算子集成Layer类,前向和反向实现如下:
import numpy as np
from module import Layers
class Pooling(Layers):
"""
"""
def __init__(self, name, ksize, stride, type):
super(Pooling).__init__(name)
self.type = type
self.ksize = ksize
self.stride = stride
def forward(self, x):
b, c, h, w = x.shape
out = np.zeros([b, c, h//self.stride, w//self.stride])
self.index = np.zeros_like(x)
for b in range(b):
for d in range(c):
for i in range(h//self.stride):
for j in range(w//self.stride):
_x = i *self.stride
_y = j *self.stride
if self.type =="max":
out[b, d, i, j] = np.max(x[b, d, _x:_x+self.ksize, _y:_y+self.ksize])
index = np.argmax(x[b, d, _x:_x+self.ksize, _y:_y+self.ksize])
self.index[b, d, _x +index//self.ksize, _y +index%self.ksize ] = 1
elif self.type == "aveg":
out[b, d, i, j] = np.mean((x[b, d, _x:_x+self.ksize, _y:_y+self.ksize]))
return out
def backward(self, grad_out):
if self.type =="max":
return np.repeat(np.repeat(grad_out, self.stride, axis=2),self.stride, axis=3)* self.index
elif self.type =="aveg":
return np.repeat(np.repeat(grad_out, self.stride, axis=2), self.stride, axis=3)/(self.ksize * self.ksize)
深度学习发展至今,一开始各种算子已经被反复蹂躏,从真香到放弃再到真香,斯坦福大学Eric Kauderer-Abrams曾经通过平移敏感图发现pooling似乎对性能没有影响,而数据增强才是提高性能的好方法。。总之带步长的卷积、池化均是为了下采样,各有优缺点,带步长的卷积虽然不需池化,却没有了灵活的激活机制。平均池化在卷积激活后稳扎稳打,却丢失了细节。最大池化克服了平均池化的缺点,因为每次只保留了最大值,也打断了梯度回传。同样池化的size大小也需要考虑。
参考:
[1] https://zhuanlan.zhihu.com/p/58381421
[2]https://www.zhihu.com/question/303215483/answer/615115629
更多CV请关注公众号:所向披靡的张大刀
文章出处登录后可见!