这篇文章由谷歌在17年提出,受启发于何凯明提出的ResNet在深度网络上较好的表现影响,作者将Residual connection加入到Inception结构中形成2个Inception-ResNet版本的网络以及一个纯Inception-v4网络。
参考目录:
①:论文的补充版(主要是添加一些图片)
②:从Inception v1到Inception-ResNet,一文概览Inception家族的「奋斗史」
③:论文笔记1
④:论文笔记2
截至这篇文章发表,谷歌提出的关于Inception块组成的GoogleNet经历了如下五个版本: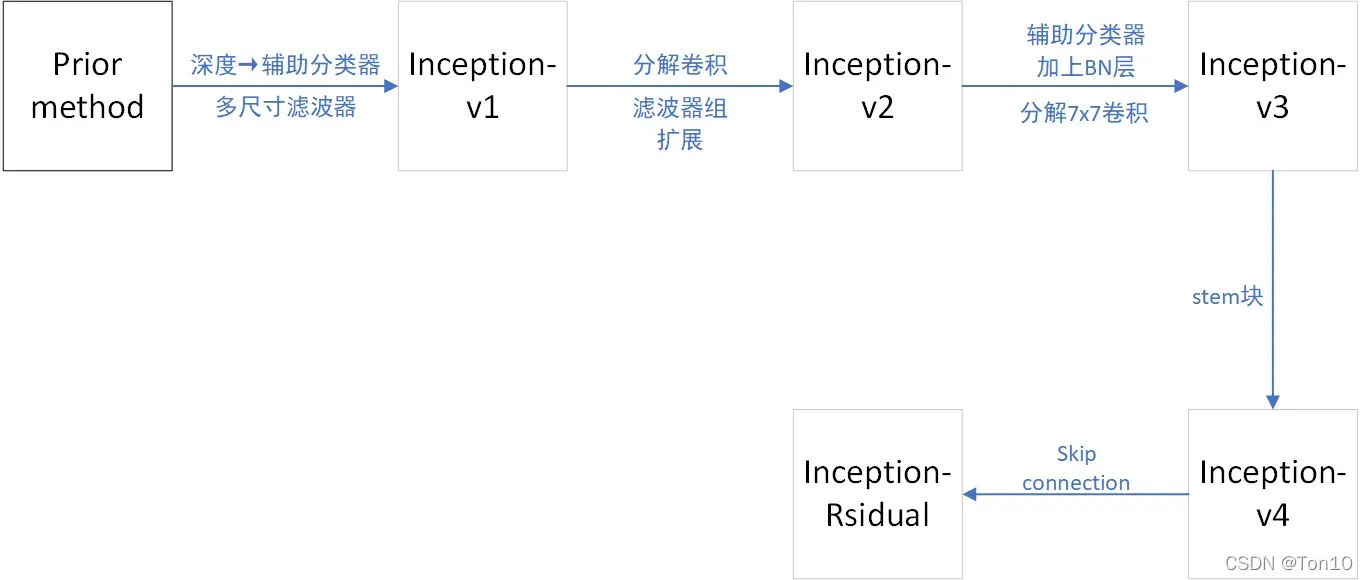 具体流程请参考上述参考文件②。
具体流程请参考上述参考文件②。
Note:
- 其中v1
v2的过程中滤波器组扩展指的是Inception块内部结构中网络变得更宽而不是更深,从而解决表征性瓶颈问题。
- 分解卷积指的是比如说
卷积分解成
和
卷积2个过程,作者指出这样会节约资源消耗。
Abstract
GoogleNet凭借着较低的计算资源损耗、通过Inception块中多个不同窗口形状的卷积层获取多尺度特征而闻名,而当时推出的Inception-v3版本和何凯明的Residual网络都取得了很好的表现,因此本文起源于作者的一个问题:如果将残差连接加入到Inception块理会怎么样?作者经过实验得出:
- residual connections有利于加速Inception网络的训练速度
. - 相同计算资源下,拥有残差连接的Inception只比没有残差连接的Inception网络表现出色一点点。这也似乎是谷歌想告诉大家:不是每次遇到深度网络就要想起用残差网络来解决。
本文的贡献如下:
- 作者推出了 Inception-v4 、 Inception-ResNet-v1 和 Inception-ResNet-v2 三种网络结构。
- 作者推出了 residual scaling 来稳定residual-based网络的训练。
1 Introduction
这篇文章中,总体来看作者主要做了2件事:
- 使用Residual网络的残差连接取代原本Inception块中池化层部分,使得filter-concatenation变成了求和相加的形式。
- 将 Inception-v3 进化到Inception-v4(注意:这都是无residual-connection的版本),相比v3,v4拥有更简洁的结构、有更多的Inception块以及在输入和首个Inception块之间引入stem模块。
2 Related Work
以往我们为深度网络的训练而发愁时,都只会想到用Residual Network来解决问题。但是作者指出,他们的实验显示了在没有skip connection的条件下,也可以取得和有残差连接时候差不多的效果;作者也严谨的说道也许是关于Residual Network更深更多的实验才能完全理解residual connection的价值。虽然有残差下的Inception网络和无残差的Inception相比表现力提升不大,但是residual connection确实可以提升Inception的训练速度。
3 Architectural Choices
本节主要介绍:
- Inception-v4网络。
- Inception-ResNet-v1、Inception-ResNet-v2网络。
- Residual Scaling。
3.1 Pure Inception blocks
首先来看Inception-v4的结构: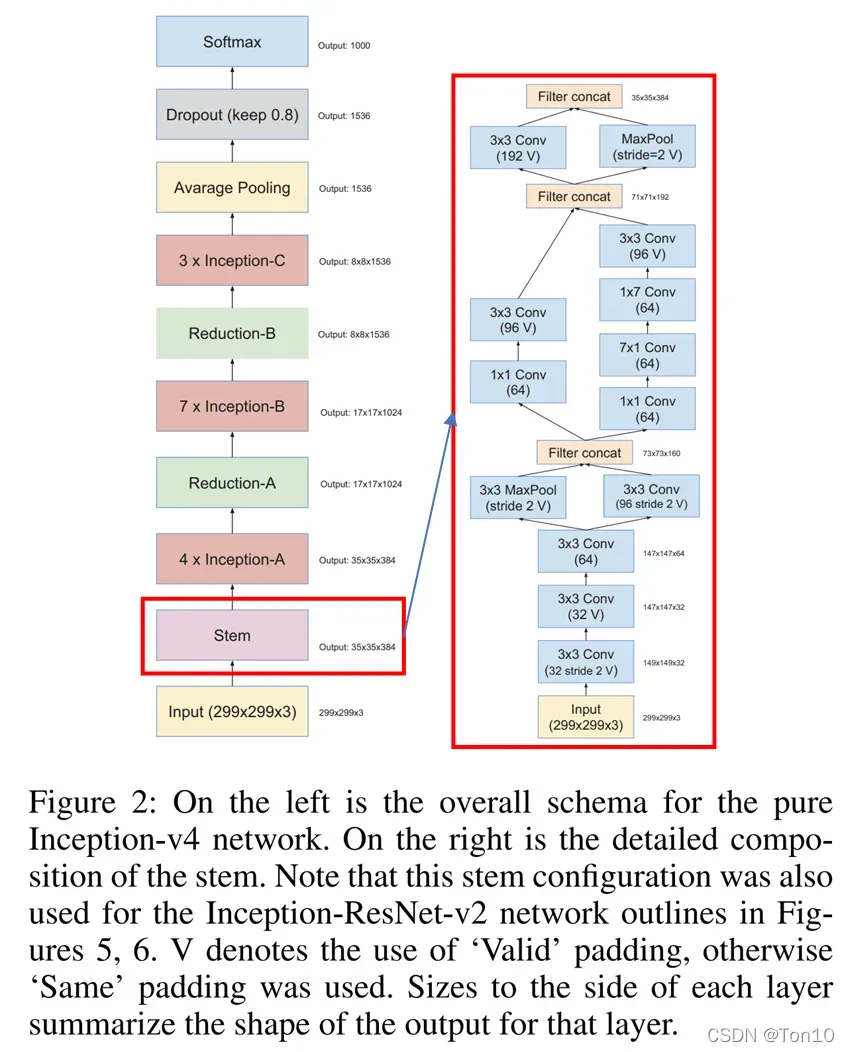
Note:
- Inception-v4引入了stem模块,如上图红色框所示,其中的 filter concat 和Inception块中的一样,是将不同滤波器运算过的feature map做通道上的合并。
- 3个输入图像宽高分别是
的Inception块内部结构如下:
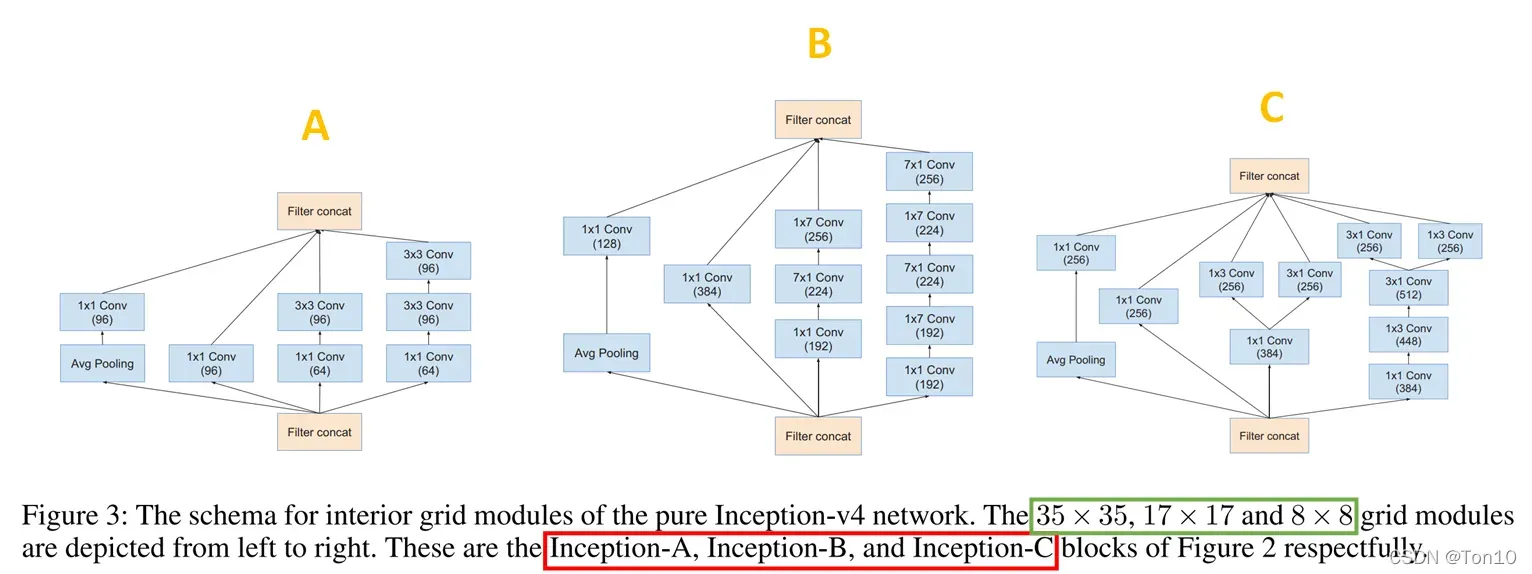
- 2个缩减块(reduction block)的内部结构如下:
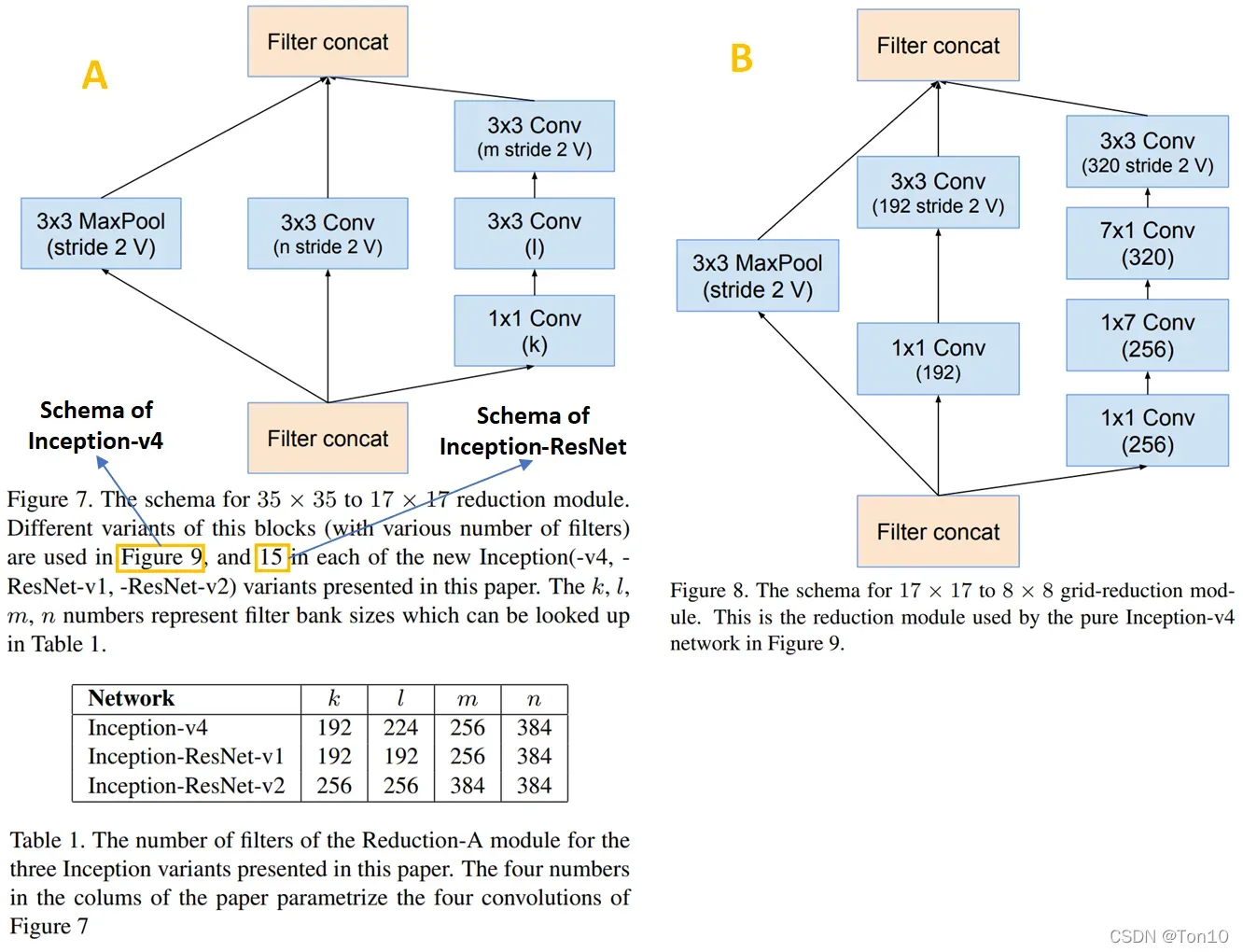
3.2 Residual Inception Blocks
接下来介绍ResNet和Inception的合体:
- Inception-ResNet-v1:这是一种和Inception-v3具有相同计算损耗的结构。
- Inception-ResNet-v2:这是一种和Inception-v4具有相同计算损耗的结构,但是训练速度要比纯Inception-v4要快。
相比纯Inception网络,Inception-ResNet网络具有以下3个特点:
- Inception块的构造更加简单。
- 采用filter-expansion layer(其实就是
卷积层)去扩大因为Inception块损失的通道数,因为过多地减少维度可能会造成信息的损失(表征性瓶颈)。
- 关于BN的使用。Inception-ResNet为了减小BN带来的存储消耗,只在stem模块中使用,而不是像之前在每个Inception块中使用。
Inception-ResNet结构如下: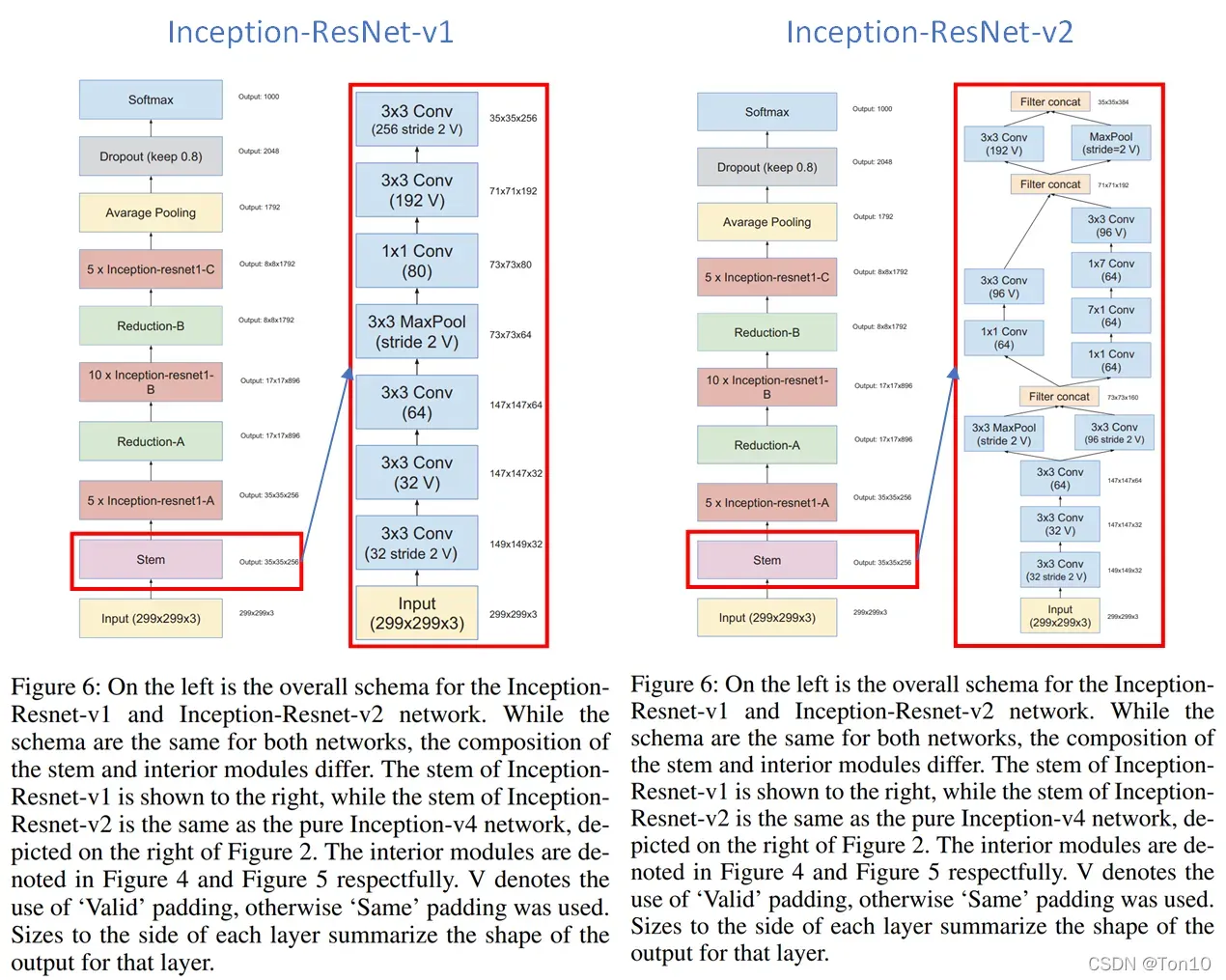
Note:
- 两个版本的总体结构相同,不同的是stem、Inception块、缩减块。
- 2个版本的3个Inception块如下:
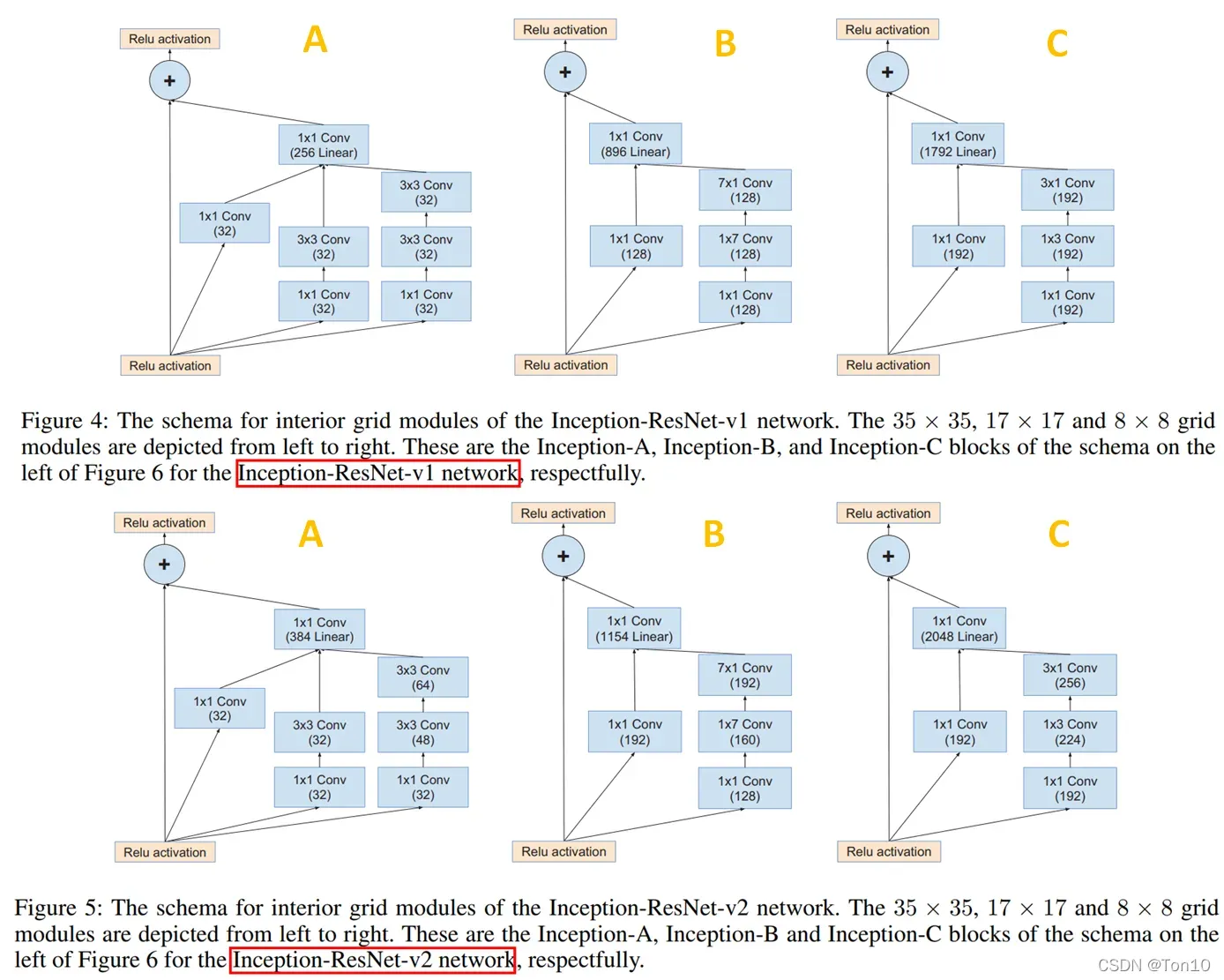 从上面结构中可以看出
从上面结构中可以看出
Inception-ResNet用残差连接取代了原Inception块中的filter concatenation,或者说残差连接代替了Inception中的池化层。 - 2个版本的缩减块结构如下:
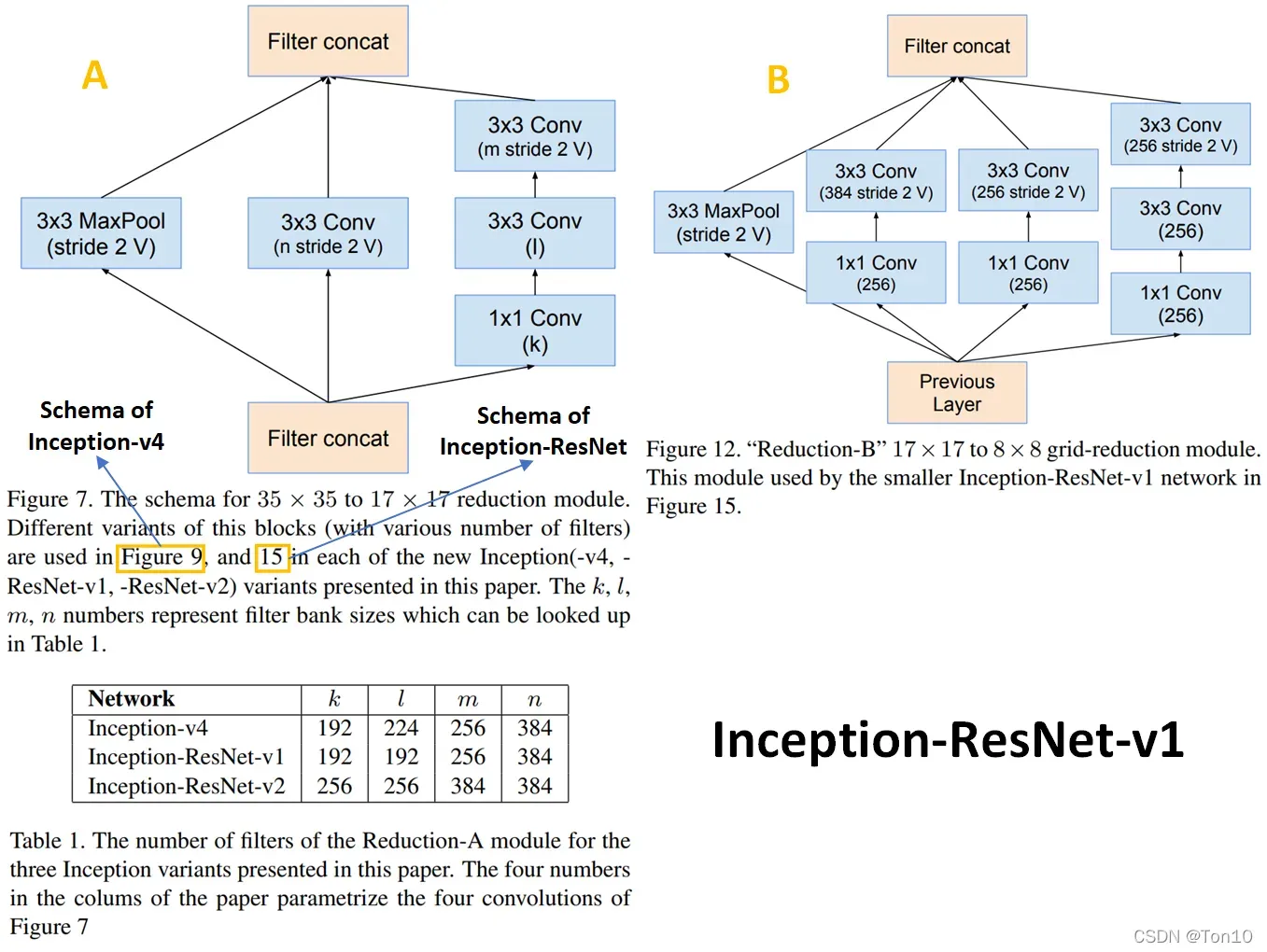
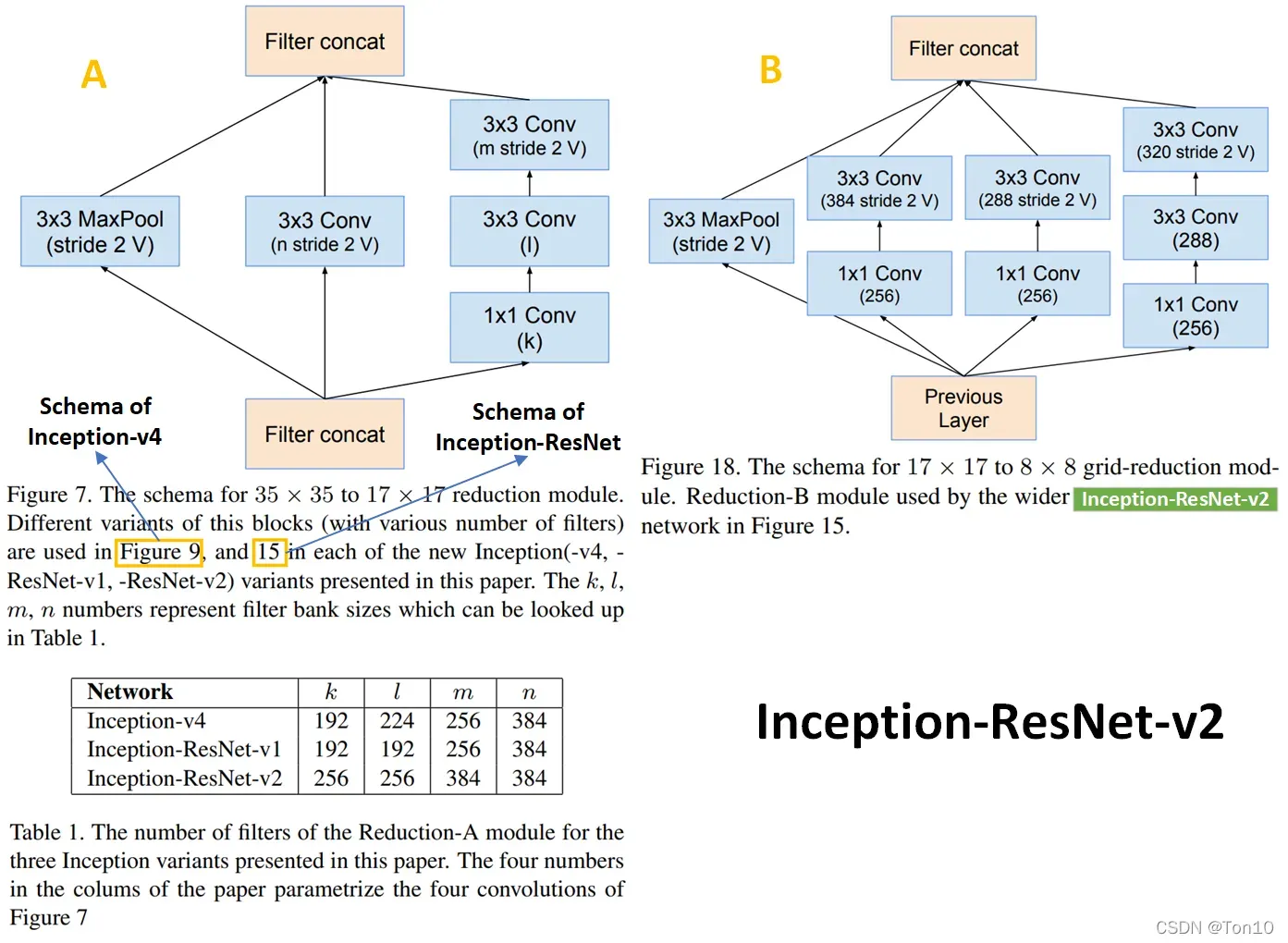 从上图中可以看出
从上图中可以看出
原Inception中被取代的池化层部分其实是转移到了缩减块中
.
3.3 Scaling of the Residuals
这一节介绍的是在残差汇合之前,对残差进行缩减来稳定训练。作者指出,当卷积核的数量超过1000时,那么残差网络就会变得不稳定,具体表现为几万次迭代之后,平均池化层之前的最后一层开始产生0的输出,使得网络崩溃坏死,这种现象通过降低学习率或者增加BN都无法解决。
因此作者决定采用residual scaling,取一个区间之内的缩减常数去减小Inception网络输出的方差,增加稳定性,一定程度上也可以避免模型过拟合。
具体结构如下: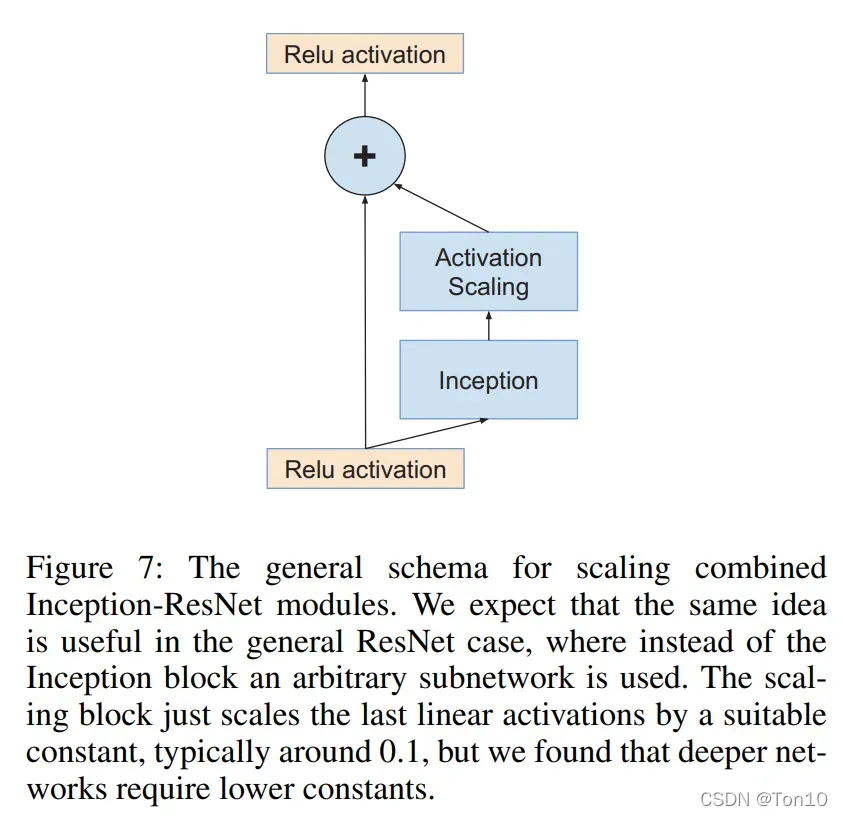
Note:
- 这种简化的结构可以应用于任何具有残差连接的网络。
- 缩减指数一般取0.1左右,且网络越深,这个值最好是越小。
- 作者指出,残差减少不仅不影响最佳性能,而且还增加了训练的稳定性。
引用一段代码(开头参考文档③)来解释这个过程:
def forward(self, x):
out = self.conv2d(x) # 这里可以是卷积层、可以是Inception模块等任意sub-network
out = out * self.scale + x # 乘以一个比例系数再相加
out = self.relu(out)
return out
4 Training Methodology
主要是关于网络的结构,所以省略了。
5 Experimental Results
主要是为了了解网络的结构,所以省略了实验。
6 Conclusions
论文一口气输出3个新的结构,分别是:
- Inception-v4:Inception-v3的进化版,增加了stem块(其实就是输入到第一个Inception的处理过程)。
- Inception-ResNet-v1:将Residual connection和Inception网络结合在一起,并引入
residual scaling
稳定训练,其计算消耗和Inception-v3类似。 - Inception-ResNet-v2:将Residual connection和Inception网络结合在一起,并引入
residual scaling
稳定训练,其计算消耗和Inception-v4类似,但
训练更快
;相比Inception-ResNet-v1,v2版本的网络参数更多,结构也略微复杂一丢丢。
文章出处登录后可见!