



1. Bert
Bert是预训练的语言表征模型,其有巨大参数量要求海量监督数据进行训练,这需要大量的人力。因此,Google采用无监督的方式进行训练,具体任务是:MLM(Masked Language Model)和NSP(Next Sentence Prediction)。
1.1 特点
- 不使用传统的单向语言模型或两个单向语言模型浅层特征拼接进行预训练;
- 采用MLM任务对双向的Transformers进行预训练,以生成深层的双向语言表征;
- 预训练后,只需要添加额外的输出层用于下游任务,并进行fine-tune。
1.2 Bert 结构
传统预训练的语言模型大部分是单向的,即从左到右或从右到左,其只能获取单方向的上下文信息,限制了模型的表征能力。Bert采用了MLM任务进行预训练,并采用深层双向的Transformer组件来构建模型,因此,最终生成融合有左右上下文的深层双向语言表征。
注意:什么是单向和双向?
单向的Transformer一般被称为Transformer Decoder,因为每一个Token只能Attend向左的Token。
双向的Transformer一般被称为Transformer Encoder,每一个Token会Attend所有的Token。
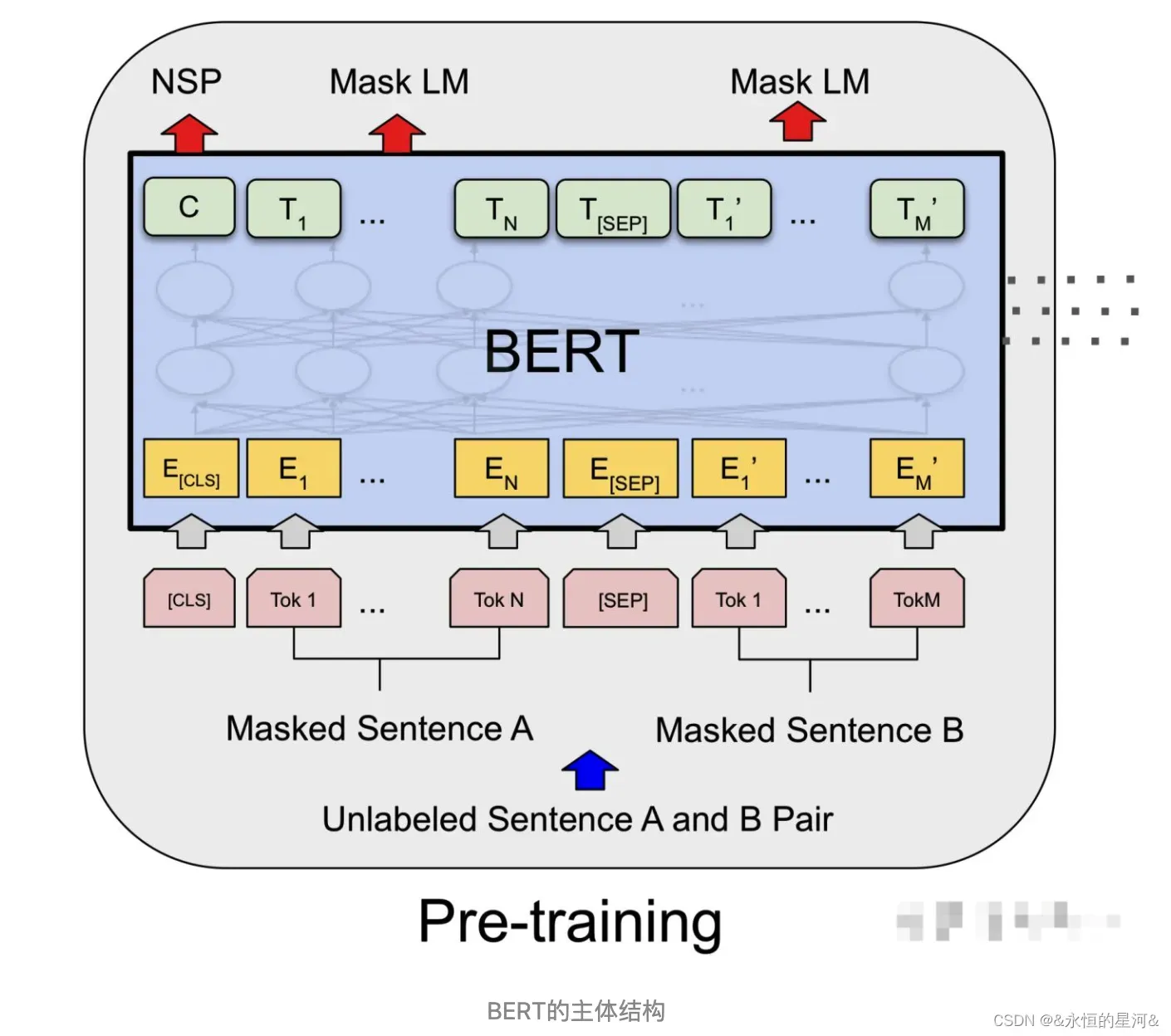
经过多层Transformer Encoder结构的堆叠后,形成BERT的主体结构,如上图。
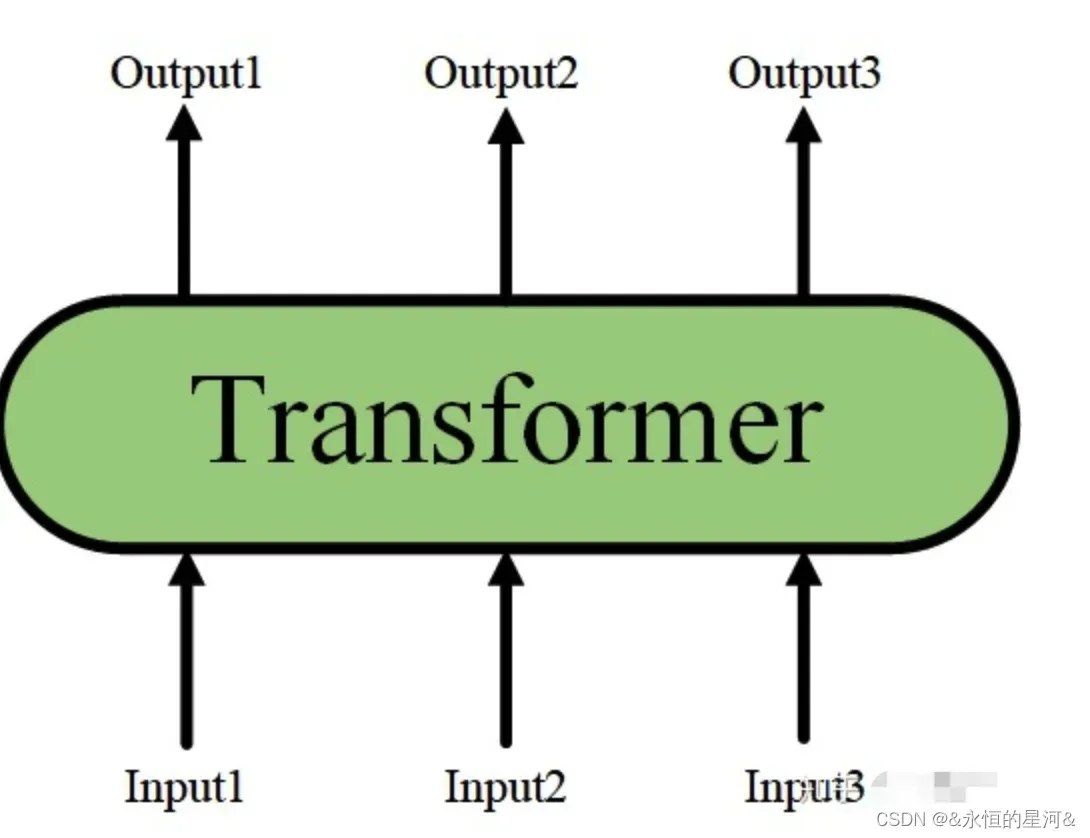
单层的Transformer Encoder结构如下图:

1.3 Bert 的输入
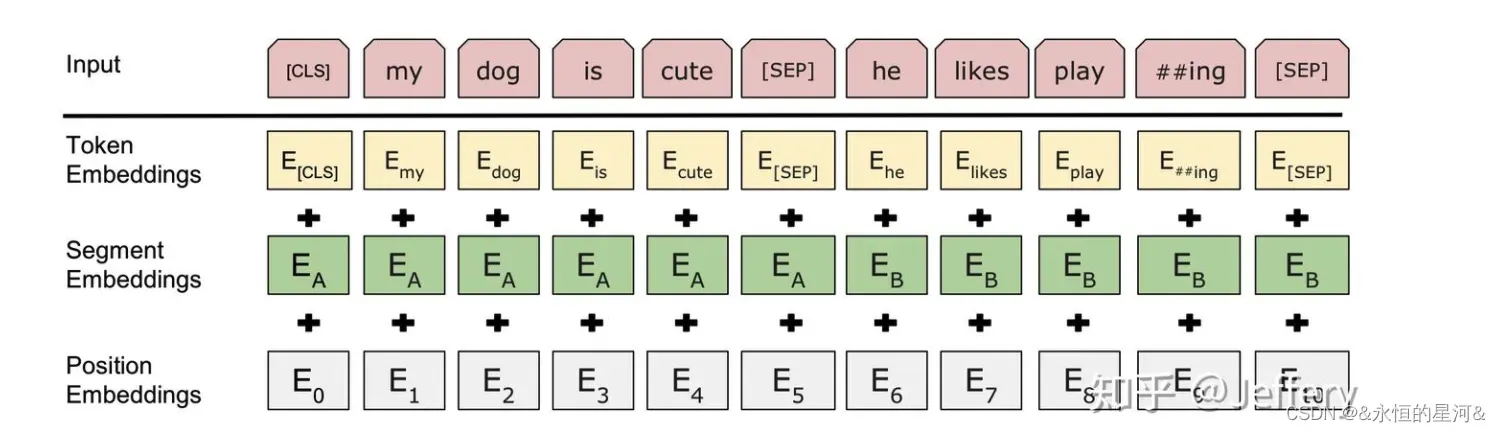

1.3.1 Token Embedding

上图为Bert Token级输入,红色表示Token, 黄色表示Token 表征。Bert中的词表采用WordPiece算法构建而成。Bert在输入序列的开头插入了 [CLS] Token,将最后一层Transformer Encoder中 [CLS] 输出表征用于下游分类任务,该Token用来聚合整个序列表征。
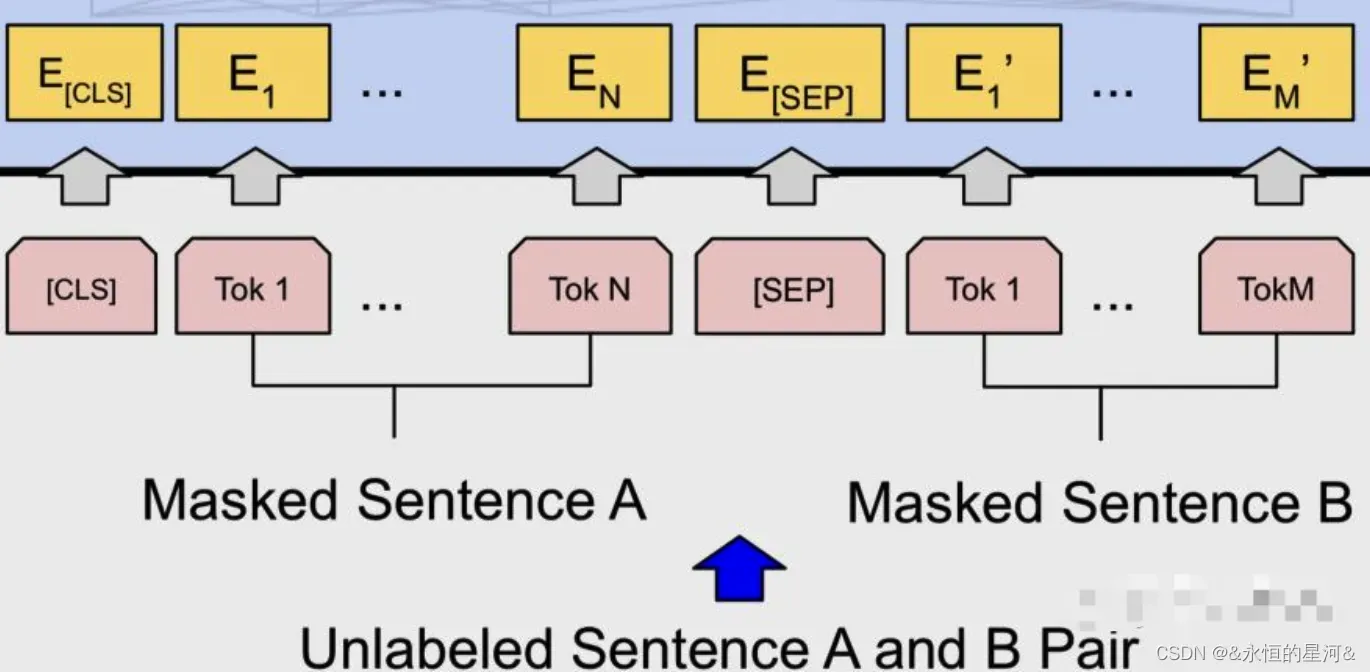
为了将Bert应用到各种各样的NLP任务中,模型必须能够处理单句或者多句输入序列,并能有效区分。Bert采用如下两种方式来解决:
- 序列tokens中把分割token([SEP])插入到每个句子后,以分开不同的句子tokens。
- 为每一个token表征都添加一个可学习的 Segment Embedding 来指示其属于句子A还是句子B。
注意:如果输入序列只包含一个句子的话,则没有[SEP]及之后的token
1.3.2 Segment Embedding
当输入序列为多句时候,引入Segment Embedding来区分每个句子。
1.3.3 Position Embedding
和Transformer位置编码不同,Bert是学习出来的,用来区分每个句子中Token的先后顺序。
1.4 Bert输出
Transformer Encoder的特点就是有多少个输入就有多少个对应的输出。
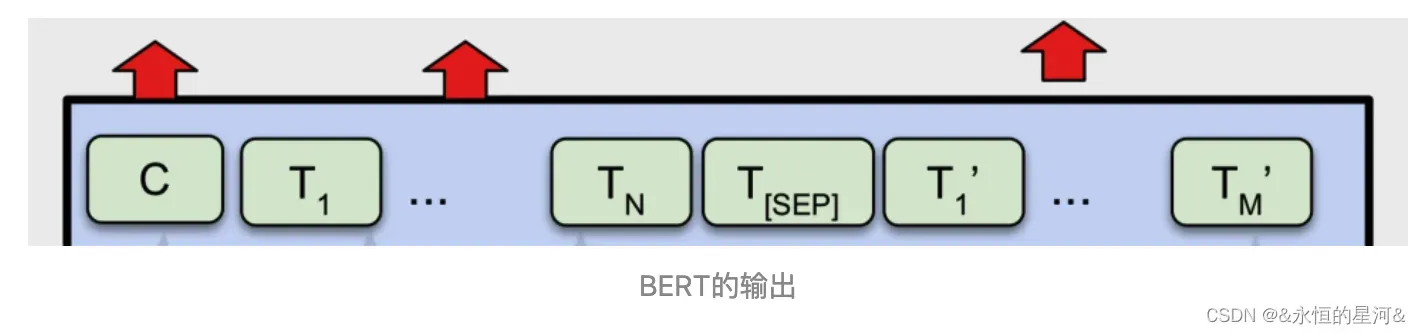

C为分类token([CLS])对应最后一个Transformer Encoder的输出, Ti 则代表其他token对应最后一个Transformer Encoder的输出。对于一些token级别的任务(如,序列标注和问答任务),就把Ti 输入到额外的输出层中进行预测。对于一些句子级别的任务(如,自然语言推断和情感分类任务),就把C输入到额外的输出层中,这里也就解释了为什么要在每一个token序列前都要插入特定的分类token。
1.5 Bert预训练任务
BERT利用大规模文本数据的自监督性质来构建预训练任务,两大预训练任务:Masked Language Model和Next Sentence Prediction。
1.5.1 Masked Language Model(MLM)
MLM是BERT能够不受单向语言模型所限制的原因。简单来说就是以15%的概率用mask token ([MASK])随机地对每一个训练序列中的token进行替换,然后预测出[MASK]位置原有单词。然而,由于[MASK]并不会出现在下游任务的微调(fine-tuning)阶段,因此预训练阶段和微调阶段之间产生了不匹配(这里很好解释,就是预训练的目标会令产生的语言表征对[MASK]敏感,但是却对其他token不敏感)。因此BERT采用了以下策略来解决这个问题:
首先在每一个训练序列中以15%的概率随机地选中某个token位置用于预测,假如是第i个token被选中,则会被替换成以下三个token之一
- 80%的时候是[MASK]。如,my dog is hairy ——>my dog is [MASK]
- 10%的时候是随机的其他token。如,my dog is hairy ——>my dog is apple
- 10%的时候是原来的token
(保持不变,个人认为是作为2)所对应的负类)
。如,my dog is hairy ——>my dog is hairy
该策略令到BERT不再只对[MASK]敏感,而是对所有的token都敏感,以致能抽取出任何token的表征信息。
那么为什么要以一定的概率使用随机词呢?
因为transformer要保持对每个输入token分布式的表征,否则Transformer很可能会记住这个[MASK]就是”hairy”。至于使用随机词带来的负面影响,文章中解释说,所有其他的token(即非”hairy”的token)共享15%*10% = 1.5%的概率,其影响是可以忽略不计的。
1.5.2 Next Sentence Prediction(NSP)
一些如问答、自然语言推断等任务需要理解两个句子之间的关系,而MLM任务倾向于抽取token层次的表征,因此不能直接获取句子层次的表征。为了使模型能够有能力理解句子间的关系,BERT使用了NSP任务来预训练。
简单来说就是预测两个句子是否连在一起。具体的做法是:对于每一个训练样例,我们在语料库中挑选出句子A和句子B来组成,50%的时候句子B就是句子A的下一句(标注为IsNext),剩下50%的时候句子B是语料库中的随机句子(标注为NotNext)。接下来把训练样例输入到BERT模型中,用[CLS]对应的C信息去进行二分类的预测。
例如:
Input1=[CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Label1=IsNext
Input2=[CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label2=NotNext
把每一个训练样例输入到BERT中可以相应获得两个任务对应的loss,再把这两个loss加在一起就是整体的预训练loss。(也就是两个任务同时进行训练)
可以明显地看出,这两个任务所需的数据其实都可以从无标签的文本数据中构建(自监督性质),比CV中需要人工标注的ImageNet数据集可简单多了。
2. RoBERTa
2.1 特点(与Bert相比)
- 训练时间更长,batch size更大,训练数据更多;
- 移除了next predict loss;
- 更长的训练序列;
- 动态调整Masking机制。
- Byte level BPE
2.1 超参数
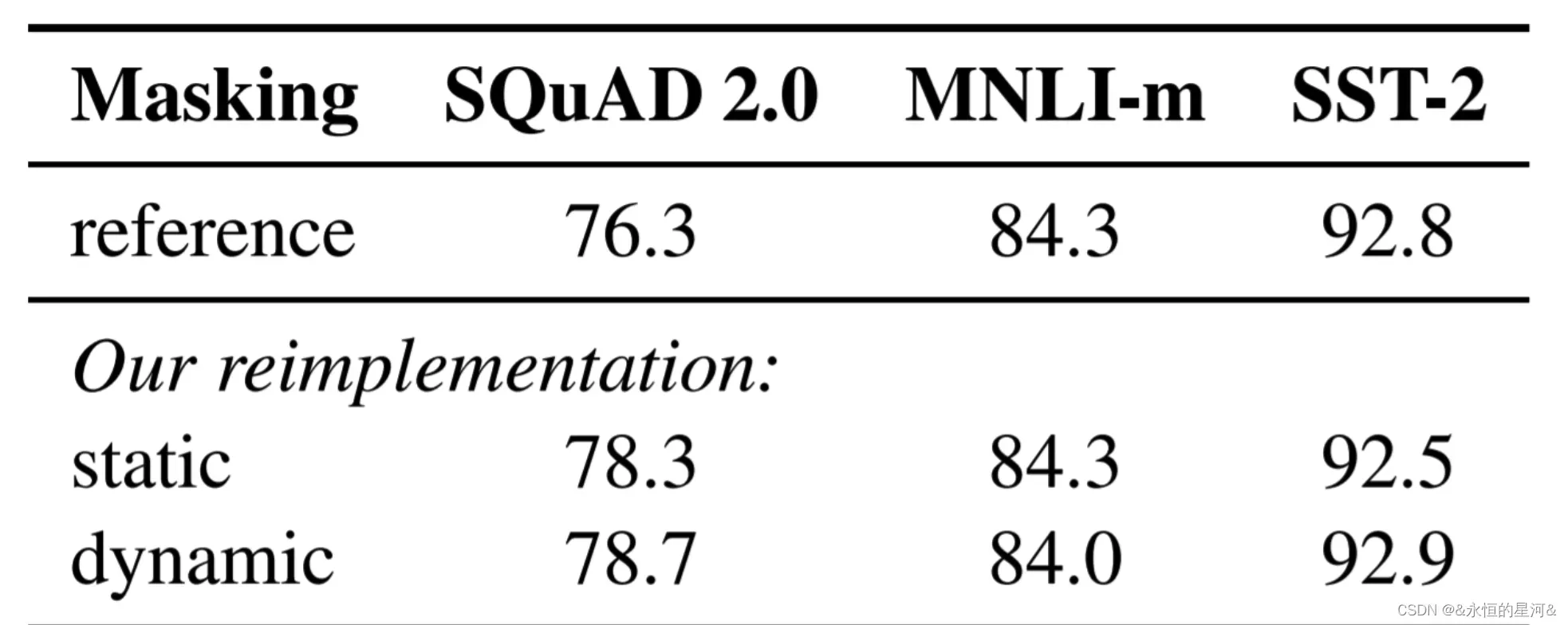
采用大的Batch Size有助于提高性能
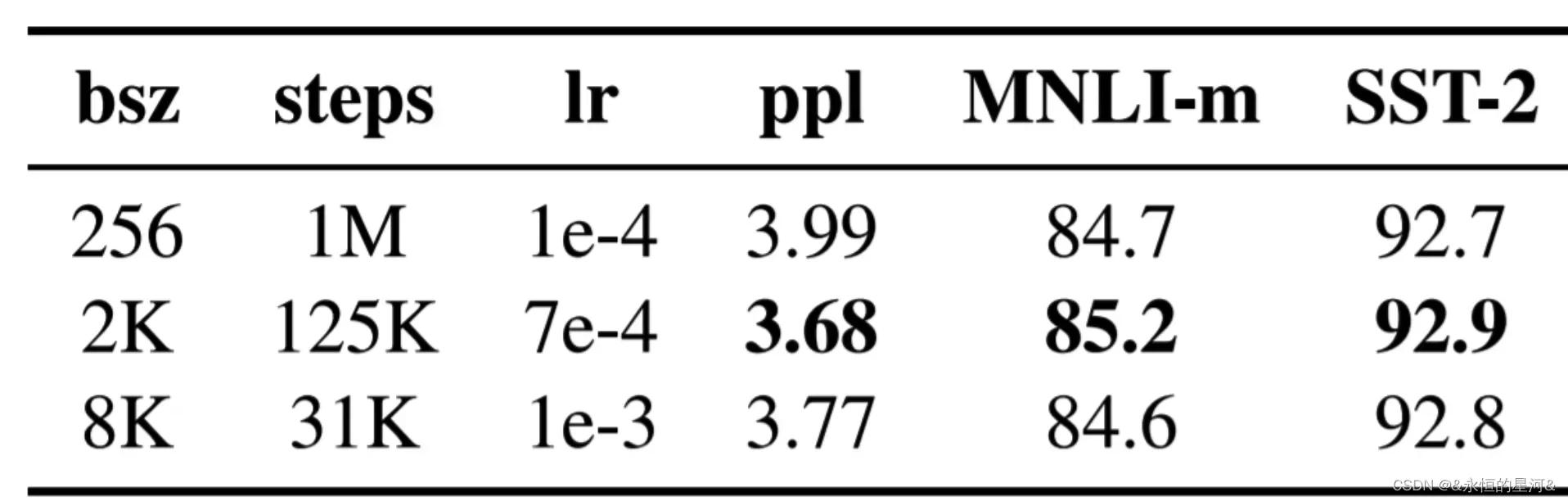

上图中第一行为Bert超参数,第二三行是RoBERTa使用超参数。其中,bsz是Batch Size;steps是训练步数(为了保证bsz*steps近似相同,所以大bsz必定对应小steps);lr是学习率;ppl是困惑度,越小越好;最后两项是不同任务的准确率。
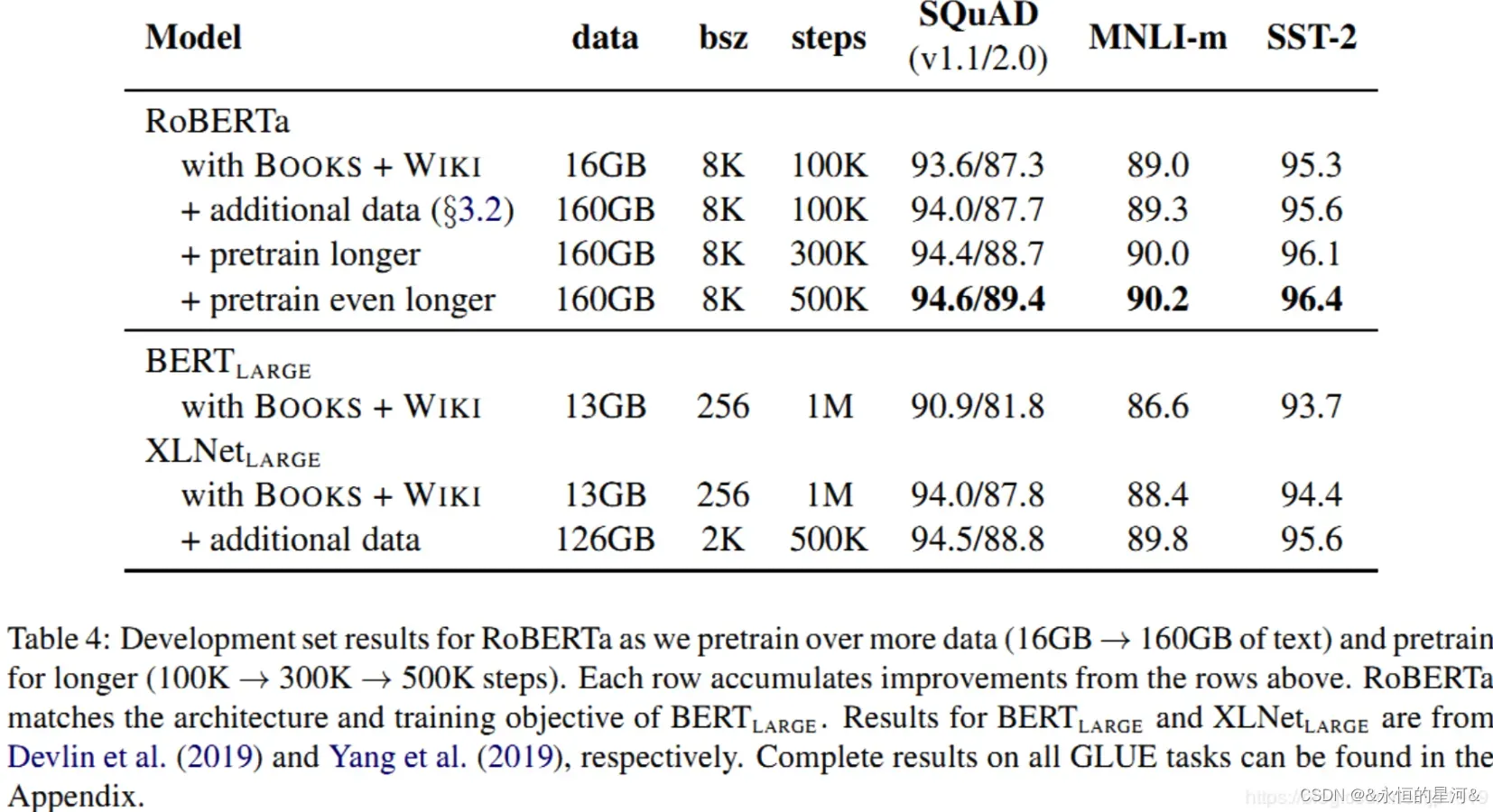

上图是按照BERT-Large架构(L=24,H=1024,A=16355m)对RoBERTa进行训练预训练结果,结果分析:更多训练数据,更多训练步数,可以增加性能。
2.2 移除NSP
原始的BERT包含2个任务,预测被mask掉的单词(MLM)和下一句预测(NSP)。鉴于最近有研究(Lample and Conneau,2019; Yang et al., 2019; Joshi et al., 2019)开始质疑NSP的必要性。所以RoBERTa实验了始终方法:
- SEGMENT-PAIR + NSP:输入包含两部分,每个部分是来自同一文档或者不同文档的 segment (segment 是连续的多个句子),这两个segment 的token总数少于 512 。预训练包含 MLM 任务和 NSP 任务。这是原始 BERT 的做法。
- SENTENCE-PAIR + NSP:输入也是包含两部分,每个部分是来自同一个文档或者不同文档的单个句子,这两个句子的token 总数少于 512 。由于这些输入明显少于512 个tokens,因此增加batch size的大小,以使 tokens 总数保持与SEGMENT-PAIR + NSP 相似。预训练包含 MLM 任务和 NSP 任务。
- FULL-SENTENCES:输入只有一部分(而不是两部分),来自同一个文档或者不同文档的连续多个句子,token 总数不超过 512 。输入可能跨越文档边界,如果跨文档,则在上一个文档末尾添加文档边界token 。预训练不包含 NSP 任务。
- DOC-SENTENCES:输入的构造类似于FULL-SENTENCES,只是不需要跨越文档边界,其输入来自同一个文档的连续句子,token 总数不超过 512 。在文档末尾附近采样的输入可以短于 512个tokens, 因此在这些情况下动态增加batch size大小以达到与 FULL-SENTENCES 相同的tokens总数。预训练不包含 NSP 任务。
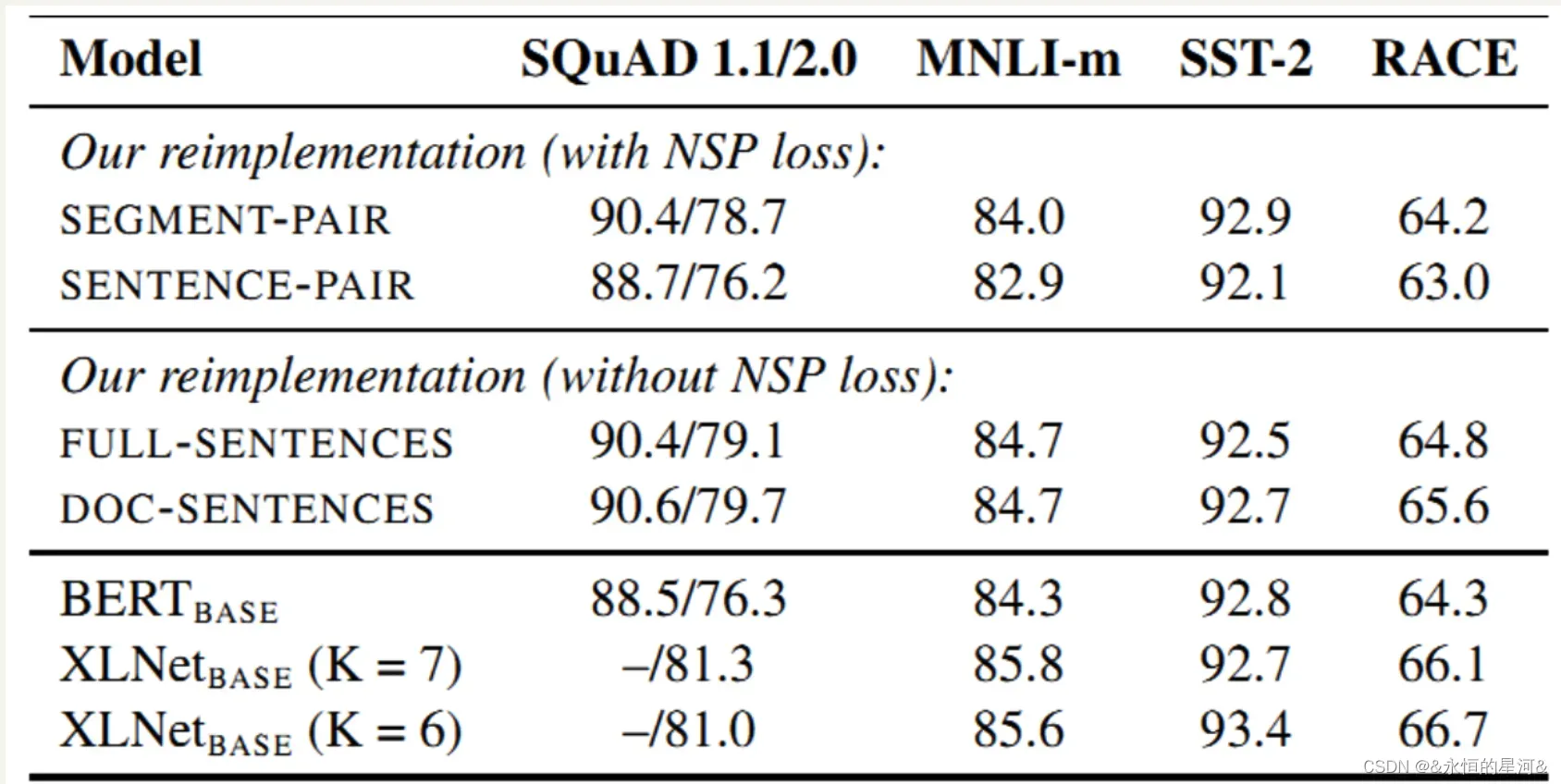

上图是实验结果图,可以看出:
- 采用NSP loss的情况下,SEGMENT-PAIR 优于SENTENCE-PAIR(两句话)。单个句子会损害下游任务的性能,因为模型无法学习远程依赖。
- 采用无NSP loss的情况下,DOC-SENTENCES优于FULL-SENTENCES,说明不要跨文档更优。
- 采用无NSP loss比采用NSP loss可以略微提高性能。
但是 DOC-SENTENCES 策略中,位于文档末尾的样本可能小于 512 个 token。为了保证每个 batch 的 token 总数维持在一个较高水平,需要动态调整 batch-size 。出于处理方便,后面采用FULL-SENTENCES输入格式。
2.4 动态调整Masking机制
Bert采用了静态Mask方式处理数据,具体描述如下:
- 静态Maksing:在数据预处理期间Mask矩阵就已生成好,每个样本只会进行一次随机Mask,每个Epoch都是相同的.
- 修改版静态Maksing:在预处理的时候将数据拷贝10份,每一份拷贝都采用不同的Mask,也就说,同样的一句话有10种不同的mask方式,然后每份数据都训练N/10个Epoch.
动态Mask
- 每次向模型输入一个序列时,都会生成一种新的Maks方式。即不在预处理的时候进行Mask,而是在向模型提供输入时动态生成Mask.

动态Mask和静态Mask对比图
2.5 Byte level BPE
BPE(字节对)编码或二元编码是一种简单的数据压缩形式,其中最常见的一对连续字节数据被替换为该数据中不存在的字节。 后期使用时需要一个替换表来重建原始数据。OpenAIGPT-2与FacebookRoBERTa均采用此方法构建subword vector.
2.5.1 算法描述
- 准备足够的训练语料
- 确定期望的subword词表大小
- 将单词拆分为字符序列并在末尾添加后缀“ ”,统计单词频率。 本阶段的subword的粒度是字符。 例如,“ low”的频率为5,那么我们将其改写为“ l o w ”:5
- 统计每一个连续字节对的出现频率,选择最高频者合并成新的subword
- 重复第4步直到达到第2步设定的subword词表大小或下一个最高频的字节对出现频率为1
停止符””的意义在于表示subword是词后缀。举例来说:”st”字词不加””可以出现在词首如”st ar”,加了””表明改字词位于词尾,如”wide st”,二者意义截然不同。


3. AIBert
3.1 解决问题
自BERT的成功以来,预训练模型都采用了很大的参数量以取得更好的模型表现。但是模型参数量越来越大也带来了很多问题,比如对算力要求越来越高、模型需要更长的时间去训练、甚至有些情况下参数量更大的模型表现却更差。本文做了一个实验,将BERT-large的参数量隐层大小翻倍得到BERT-xlarge模型,并将BERT-large与BERT-xlarge的结构进行对比如下:
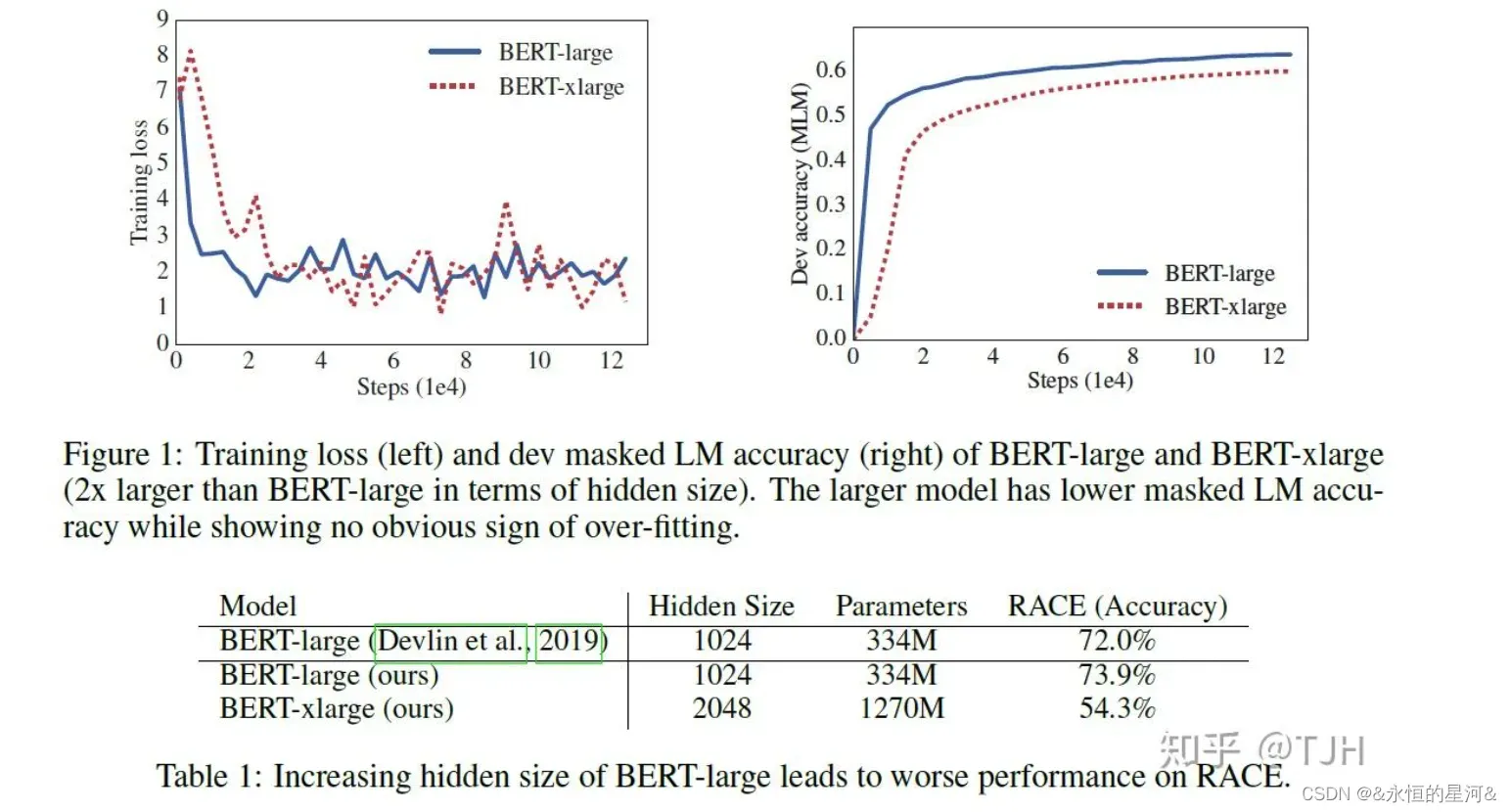

从上图可以看出,仅仅增加BERT-large 等模型的隐藏层大小也会导致性能下降。研究者将 BERT-large 的隐藏层大小增加一倍,该模型(BERT-xlarge)在 RACE 基准测试上的准确率显著降低。为了解决目前预训练模型参数量过大的问题,本文提出了两种能够大幅减少预训练模型参数量的方法,此外还提出用Sentence-order prediction(SOP)任务代替BERT中的Next-sentence prediction(NSP)任务,基于这些本文提出了ALBERT(A Lite BERT)模型,在多个自然语言理解任务中取得了state-of-the-art的结果。
3.2 AlBert改进点
3.2.1 嵌入向量参数化的因式分解(Factorized embedding parameterization)
在 BERT 以及后续的 XLNet 和 RoBERTa 中,WordPiece 词嵌入大小 E 和隐藏层大小 H 是相等的,即 E ≡ H。由于建模和实际使用的原因,这个决策看起来可能并不是最优的。
从建模的角度来说,WordPiece 词嵌入的目标是学习上下文无关的表示,而隐藏层嵌入的目标是学习上下文相关的表示。通过上下文相关的实验,BERT 的表征能力很大一部分来自于使用上下文为学习过程提供上下文相关的表征信号。因此,将 WordPiece 词嵌入大小 E 从隐藏层大小 H 分离出来,可以更高效地利用总体的模型参数,其中 H 要远远大于 E。
从实践的角度,自然语言处理使用的词典大小 V 非常庞大,如果 E 恒等于 H,那么增加 H 将直接加大嵌入矩阵的大小,这种增加还会通过 V 进行放大。
因此, 本文想要打破 E 与 H 之间的绑定关系,从而减小模型的参数量,同时提升模型表现。将embedding matrix分解为两个小矩阵。研究者不再将 one-hot 向量直接映射到大小为 H 的隐藏空间,而是先将它们映射到一个低维词嵌入空间 E,然后再映射到隐藏空间。通过这种分解,研究者可以将词嵌入参数从 O(V × H) 降低到 O(V × E + E × H),这在 H 远远大于 E 的时候,参数量减少得非常明显。
3.2.2 跨层参数共享(cross-layer parameter sharing)
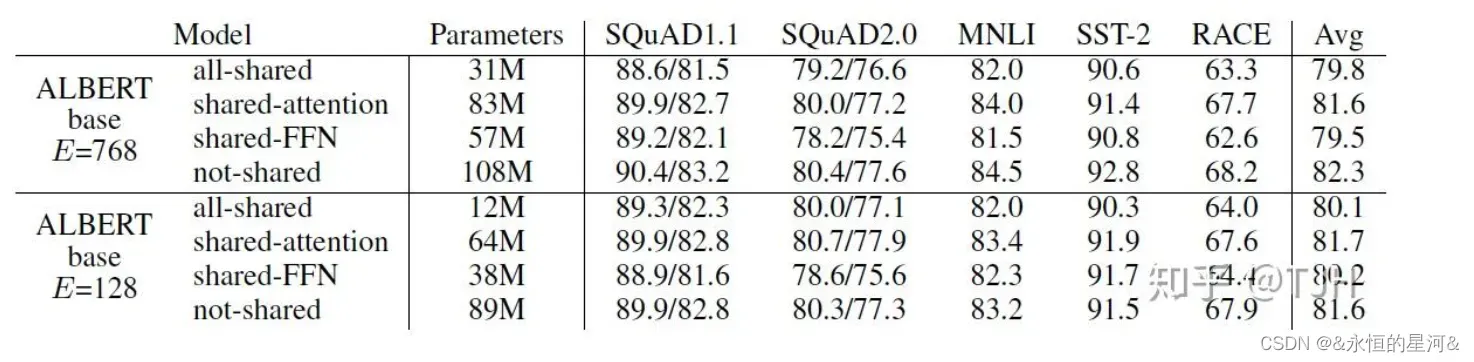
本文提出的另一个减少参数量的方法就是层之间的参数共享,即多个层使用相同的参数。参数共享有三种方式:只共享feed-forward network的参数、只共享attention的参数、共享全部参数。ALBERT默认是共享全部参数的,在后续实验结果中可以看到几种方式的模型表现。
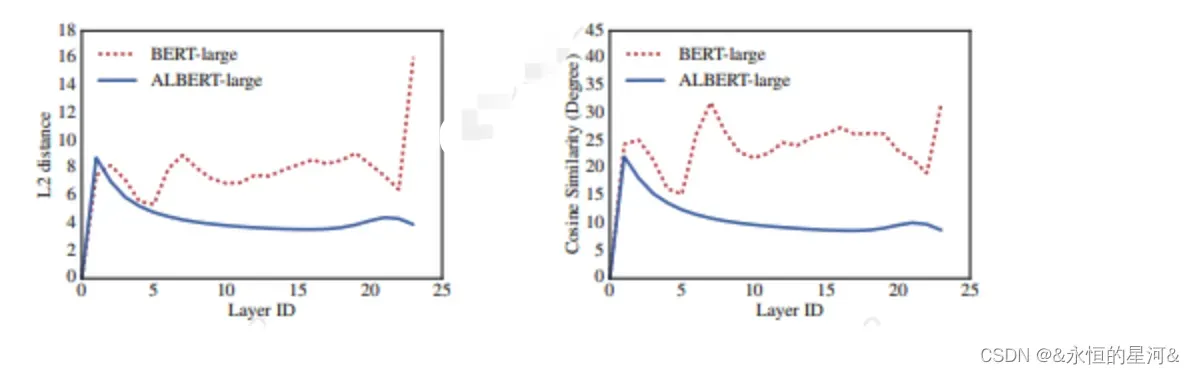
如下图所示,实验表明加入参数共享之后,每一层的输入embedding和输出embedding的L2距离和余弦相似度都比BERT稳定了很多。这证明参数共享能够使模型参数更加稳定。


除了减少模型参数外,本外还对BERT的预训练任务Next-sentence prediction (NSP)进行了改进。BERT使用的NSP损失,是预测两个片段在原文本中是否连续出现的二分类损失。目标是为了提高如NLI(Natural Language Inference)等下游任务的性能,但是最近的研究都表示 NSP 的作用不可靠,都选择了不使用NSP。
作者推测,NSP效果不佳的原因是其难度较小。将主题预测和连贯性预测结合在了一起,但主题预测比连贯性预测简单得多,并且它与LM损失学到的内容是有重合的。
SOP的正例选取方式与BERT一致(来自同一文档的两个连续段),而负例不同于BERT中的sample,同样是来自同一文档的两个连续段,但交换两段的顺序,从而避免了主题预测,只关注建模句子之间的连贯性。


BERT的MLM目标是随机MASK15%的词来预测,ALBERT预测的是N-gram片段,包含更多的语义信息,每个片段长度n(最大为3),根据概率公式计算得到。比如1-gram、2-gram、3-gram的的概率分别为6/11、3/11、2/11.越长概率越小.
3.2.5 结果对比
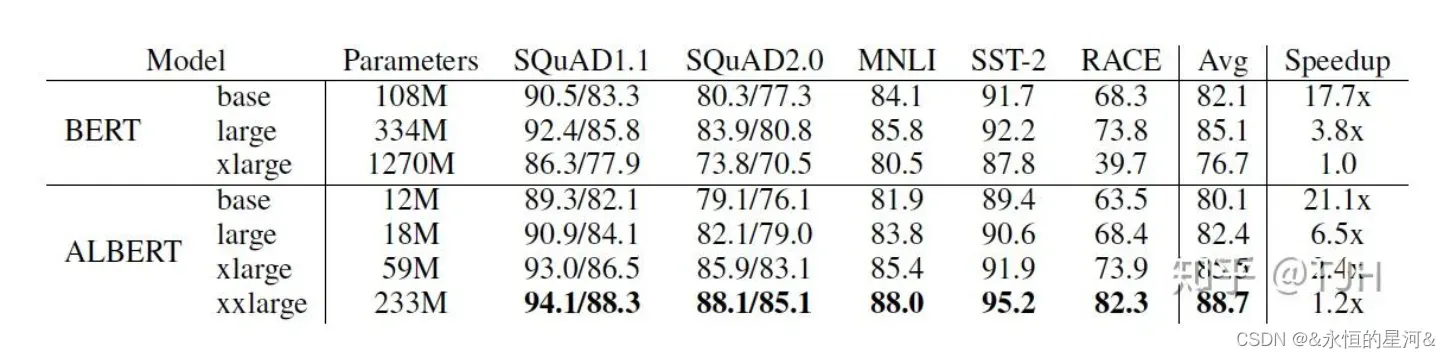

从上图的实验结果可见,ALBERT的训练速度明显比BERT快,ALBERT-xxlarge的表现更是全方面超过了BERT。
4. SpanBert
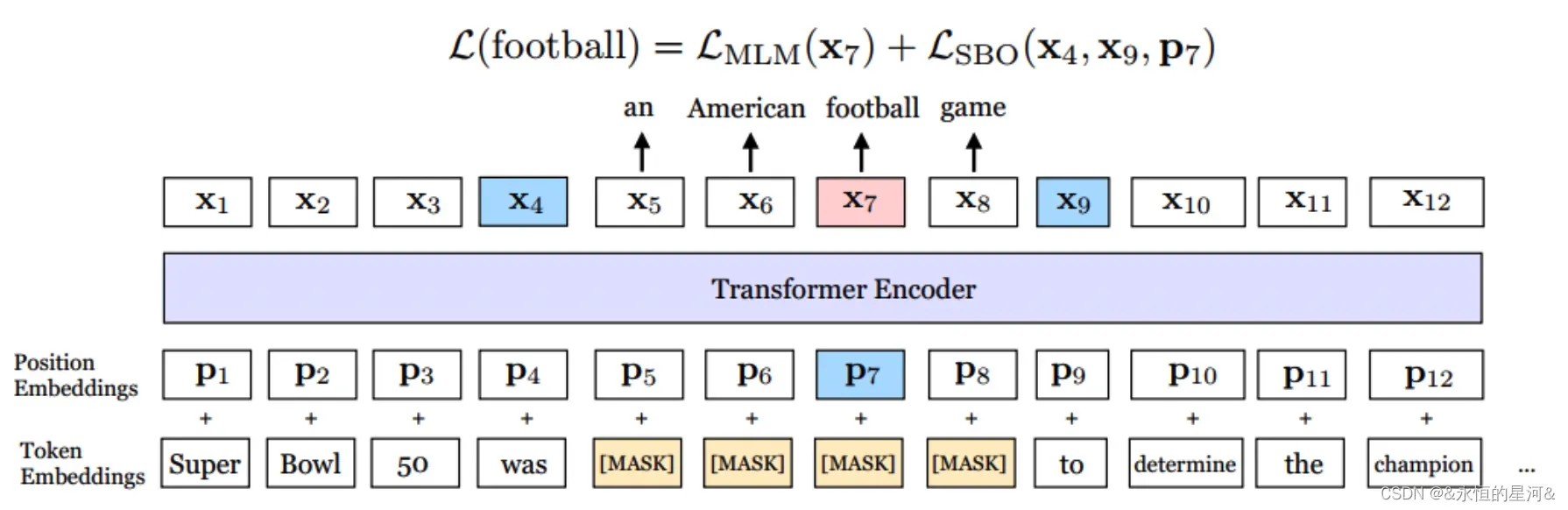

提出了一种新的mask的方法,以及一个新损失函数对象。并且讨论了bert中的NSP任务是否有用。
4.2 SpanBert改进点
4.2.1 单句训练 (Single-Sentence training)
不像Bert, SpanBert没有采用NSP(Next Sentence Prediction)进行预训练,而是直接采用单句进行训练,即不加入NSP任务判断上下句,直接用一句话来训练。作者给出的原因如下:
- 更长的上下文对模型更有利,模型可以获得更长的上下文;
- 加入另一个文本语境信息会给MLM任务带来噪音
因此,SpanBERT 就没采用 NSP 任务,仅采样一个单独的邻接片段,该片段长度最多为512个单词,其长度与 BERT 使用的两片段的最大长度总和相同,然后 MLM 加上 SBO 任务来进行预训练。
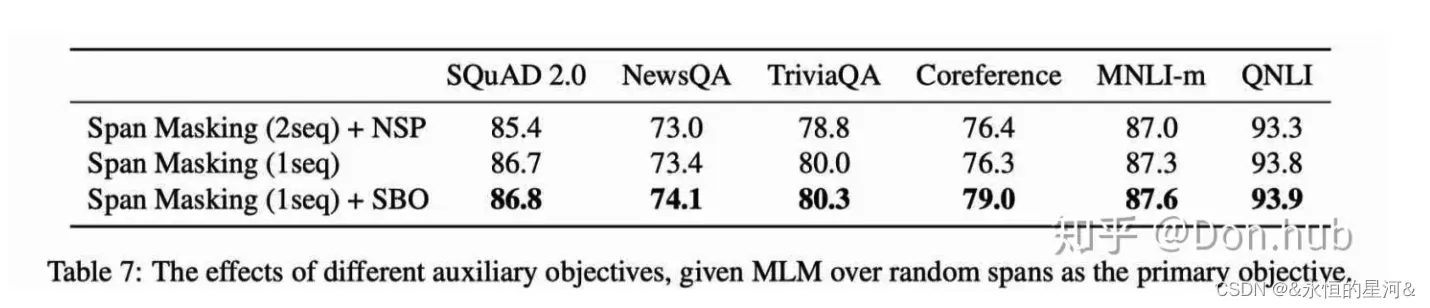

SpanBERT 不再对随机的单个 token 添加掩膜,而是对随机对邻接分词添加掩膜。
对于每一个单词序列 X = (x1, …, xn),作者通过迭代地采样文本的分词选择单词,直到达到掩膜要求的大小(例如 X 的 15%),并形成 X 的子集 Y。在每次迭代中,作者首先从几何分布 l ~ Geo(p) 中采样得到分词的长度,该几何分布是偏态分布,偏向于较短的分词。之后,作者随机(均匀地)选择分词的起点。
和在 BERT 中一样,作者将 Y 的规模设定为 X 的15%,其中 80% 使用 [MASK] 进行替换,10% 使用随机单词替换,10%保持不变。与之不同的是,作者是在分词级别进行的这一替换,而非将每个单词单独替换。
4.2.3 Span-Boundary Objective (SBO)
分词选择模型一般使用其边界词创建一个固定长度的分词表示。为了与该模型相适应,作者希望结尾分词的表示的总和与中间分词的内容尽量相同。为此,作者引入了 SBO ,其仅使用观测到的边界词来预测带掩膜的分词的内容(如下图)。
具体做法是,在训练时取 Span 前后边界的两个词,值得指出,这两个词不在 Span 内,然后用这两个词向量加上 Span 中被遮盖掉词的位置向量,来预测原词。
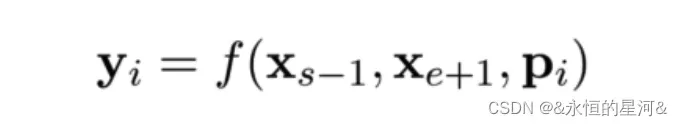

详细做法是将词向量和位置向量拼接起来,作者使用一个两层的前馈神经网络作为表示函数,该网络使用 GeLu 激活函数,并使用层正则化:


作者使用向量表示 yi 来预测 xi ,并和 MLM 一样使用交叉熵作为损失函数,就是 SBO 目标的损失,之后将这个损失和 BERT 的Mased Language Model (MLM)的损失加起来,一起用于训练模型。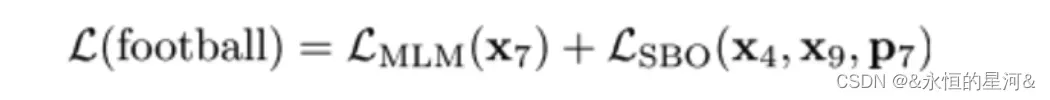

5. XLNet
待办的
文章出处登录后可见!