论文地址:https://arxiv.org/pdf/2102.00240.pdf
Github地址:https://github.com/wofmanaf/SA-Net/blob/main/models/sa_resnet.py
注意机制使神经网络能够准确地聚焦于输入的所有相关元素,已成为改善深层神经网络性能的重要组成部分。计算机视觉研究中广泛使用的注意机制主要有两种:空间注意力和通道注意力,它们分别用于捕捉像素级的成对关系和通道依赖。尽管将它们融合在一起可能会获得比各自实现更好的性能,但这将不可避免地增加计算开销。在本文中,作者提出了一个有效的Shuffle Attention(SA)模块来解决这个问题,该模块采用Shuffle单元来有效地结合两种类型的注意机制。具体来说,SA首先将通道尺寸分组为多个子特征,然后再并行处理它们。然后,对于每个子特征,SA利用一个Shuffle单元来描述空间和通道维度上的特征依赖关系。然后,对所有子特征进行聚合,并采用“channel shuffle”算子来实现不同子特征之间的信息通信。
一、文章介绍
本文的主要贡献总结如下:
1)为深度CNN引入了一个轻量级但有效的注意模块SA,该模块将通道维度分为多个子特征,然后利用Shuffle单元为每个子特征集成互补通道和空间注意模块。
2) 在ImageNet-1k和MS COCO上的大量实验结果表明,与最先进的注意方法相比,所提出的SA具有更低的模型复杂度,同时实现了优异的性能。
2. 实施细节
SA模块将输入的特征映射划分为多个组,并使用Shuffle单元将通道注意和空间注意集成到每个组的一个块中。之后,所有子特征被聚合,并使用“channel shuffle”操作符来实现不同子特征之间的信息通信。SA模块的总体架构如下所示。 它采用“通道分割”来并行处理每组的子特征。对于通道注意分支,使用GAP生成通道统计信息,然后使用一对参数缩放和移动通道向量。对于空间注意分支,采用群体范数生成空间统计信息,然后创建一个类似于通道分支的紧凑特征。然后将这两个分支连接起来。之后,所有子特征被聚合,最后使用“channel shuffle”操作符来实现不同子特征之间的信息通信。
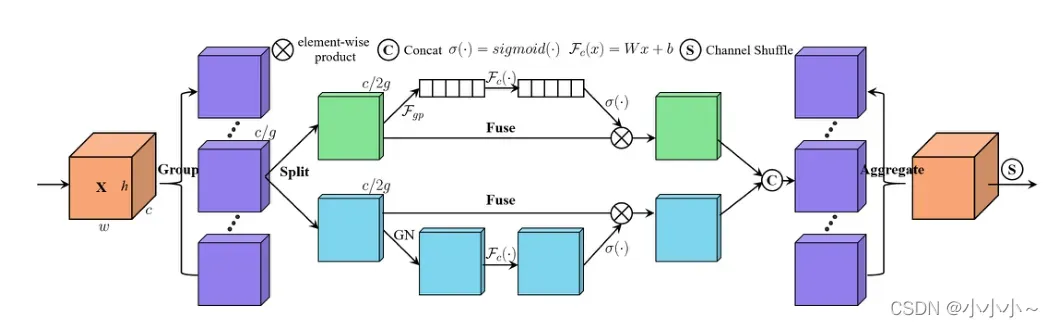
Channel Attention:对于给定的特征映射,其中C、H、W分别表示通道、空间高度和宽度,SA首先沿通道尺寸将X分为G组,即
,
,其中每个子功能
逐渐捕获训练过程中的特定语义响应。然后,通过注意模块为每个子特征生成相应的重要性系数。具体来说,在每个注意单元的开始,
的输入沿着通道维度分为两个分支,即
。如上所示,一个分支通过利用通道之间的关系来生成通道注意力图,而另一个分支通过利用特征之间的空间关系来生成空间注意力图,因此模型可以关注“什么”和“哪里”是有意义的。
SE模可以完全捕获通道依赖性。然而,它会带来太多的参数,这不利于在速度和准确性之间进行权衡。此外,ECA执行更快的大小为k的一维卷积来生成通道权重是不适合的,因为k往往更大。为了改进这一点,作者提供了一种替代方法,该方法首先通过简单地使用全局平均池(GAP)来嵌入全局信息,以生成通道统计信息,可通过空间尺寸
收缩
来计算:
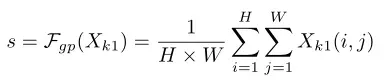
此外,还创建了一个紧凑的功能,以实现精确和自适应选择的指导。这是通过一个sigmoid实现的。然后,通道注意的最终输出为: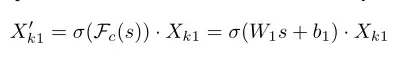
,
为用于缩放和移动s的参数。
Spatial Attention:与通道注意力不同,空间注意力侧重于“何处”是有用的信息,是通道注意力的补充。首先,使用上的Group Norm(GN)来获得空间统计信息。然后,采用
来增强
的表示性。空间注意的最终输出为
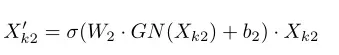
其中和
是形状
的参数。
然后连接这两个分支,使通道数与输入数相同,即。
之后,所有子特征都被聚合。最后,与ShuffleNet v2类似,采用了一个“通道shuffle”操作符,使跨组信息能够沿着通道维度流动。SA模块的最终输出与X的大小相同,这使得SA很容易与其他结构集成。
请注意,和 Group Norm超参数为SA中引入的参数。在单个SA模块中,每个分支中的通道数为C/2G。因此,总参数为3C/G(通常G为32或64),与整个网络的数百万个参数相比,这是微不足道的,这使得SA相当轻量级。
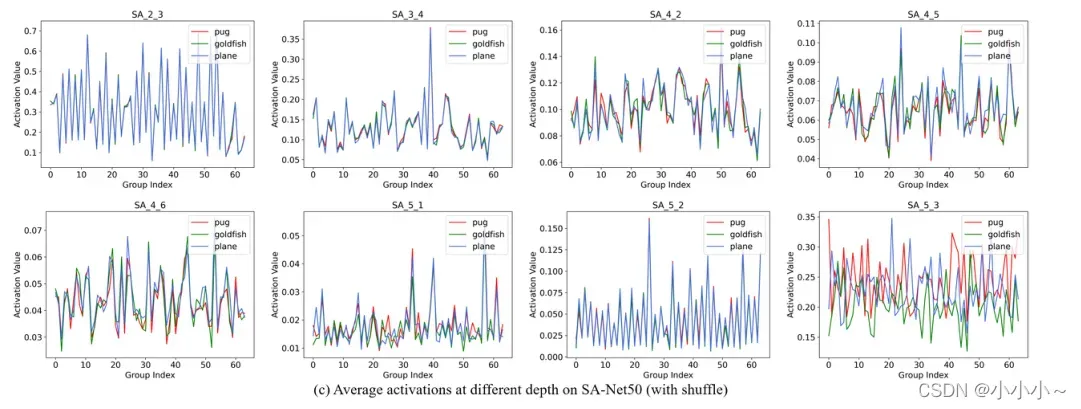
为了充分验证SA的有效性,作者绘制了SA-Net50(带shuffle)中不同深度的三个类别(“狗”、“金鱼”和“飞机”)的平均激活分布(每组通道特征图的平均值,类似于SE)。结果如上所示。对SA模块的作用进行了一些观察:
(1)在早期阶段,不同类别之间的分布非常相似(例如,SA 2_3和SA 3_4),这表明在早期阶段,不同类别可能共享特征组的重要性;
(2) 在更深的层次上,由于不同的类别对特征的鉴别价值表现出不同的表现(例如,SA 4_6和SA 5 _3),每个组的激活变得更具有类别特异性;
(3) SA 5_2在不同类别上表现出相似的模式,这意味着SA 5_2在为网络提供重新校准方面不如其他模块重要。
3. 实验结果
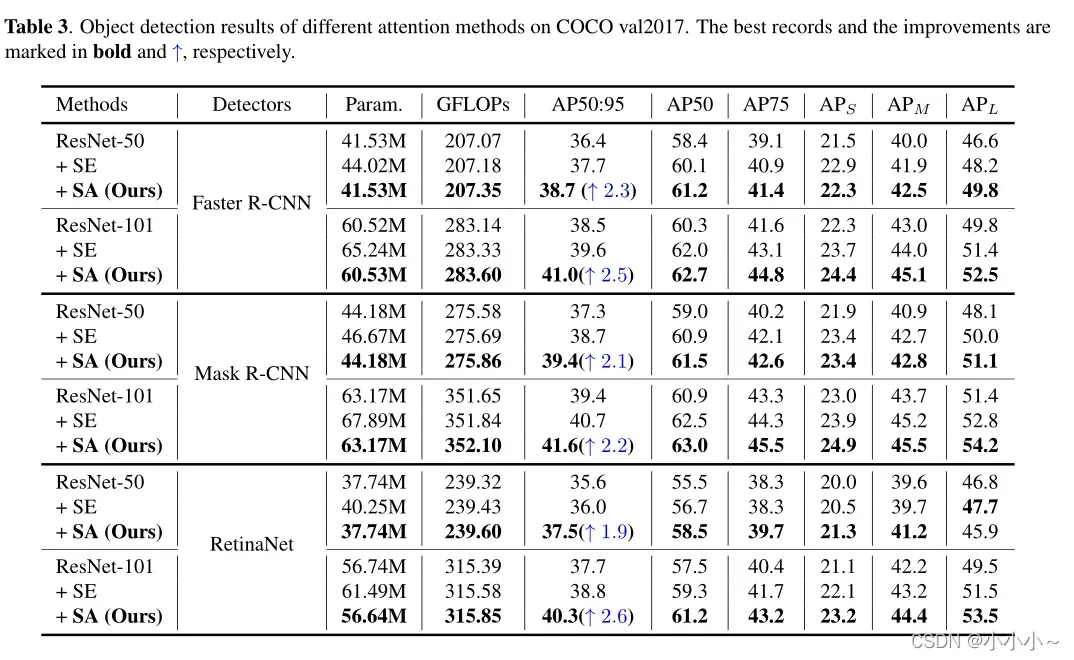
四、相关代码
class sa_layer(nn.Module):
"""Constructs a Channel Spatial Group module.
Args:
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel, groups=64):
super(sa_layer, self).__init__()
self.groups = groups
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.cweight = Parameter(torch.zeros(1, channel // (2 * groups), 1, 1))
self.cbias = Parameter(torch.ones(1, channel // (2 * groups), 1, 1))
self.sweight = Parameter(torch.zeros(1, channel // (2 * groups), 1, 1))
self.sbias = Parameter(torch.ones(1, channel // (2 * groups), 1, 1))
self.sigmoid = nn.Sigmoid()
self.gn = nn.GroupNorm(channel // (2 * groups), channel // (2 * groups))
@staticmethod
def channel_shuffle(x, groups):
b, c, h, w = x.shape
x = x.reshape(b, groups, -1, h, w)
x = x.permute(0, 2, 1, 3, 4)
# flatten
x = x.reshape(b, -1, h, w)
return x
def forward(self, x):
b, c, h, w = x.shape
x = x.reshape(b * self.groups, -1, h, w)
x_0, x_1 = x.chunk(2, dim=1)
# channel attention
xn = self.avg_pool(x_0)
xn = self.cweight * xn + self.cbias
xn = x_0 * self.sigmoid(xn)
# spatial attention
xs = self.gn(x_1)
xs = self.sweight * xs + self.sbias
xs = x_1 * self.sigmoid(xs)
# concatenate along channel axis
out = torch.cat([xn, xs], dim=1)
out = out.reshape(b, -1, h, w)
out = self.channel_shuffle(out, 2)
return out
文章出处登录后可见!