YOLOv1基本设计原理
Yolo算法采用一个单独的CNN模型实现end-to-end的目标目标检测,将其视为一个单一回归(Regression)问题。
一.一张图片首先Resize到448×448的size;原论文中给出的理由是:目标检测通常需要细粒度的视觉信息,因此我们将网络的输入(input)分辨率从 224 × 224 增加到 448 × 448。
二.将输入(input)的图片变成切割成 S*S的网格(单元格);(在文章后边令S=7。)
三.每一个单元格要预测B个边界框(bounding box)以及边界框的置信度(Confidence)(confidence score);
置信度(Confidence)包含两方面内容:(原谅我直接从写好的Typora上截图)

四.边界框的大小与位置可以用4个值来表征。

五.对于每一个单元格其还要给出预测出 C个类别概率值,表示该单元格负责预测的边界框中的目标属于各个类别的概率。

六.Yolo算法将目标目标检测看成回归(Regression)问题,所以采用的是均方差损失函数(Loss function)。(这块内容不进行过多解释。)
但我将从原始论文中给出两个更重要的词:
1.平方和误差 (sum-squared error),但是需要最大化平均精度。平方和误差使位置误差和分类误差等权相加,这并不理想。(This pushes the“confidence” scores of those cells towards zero, often overpowering the gradient from cells that do contain objects.)
2.误差度量(error metric)应该反映大盒子中的小偏差(Bias 偏置 )比小盒子中的小偏差(Bias 偏置 )更重要 。(To partially address this we predict the square root of the bounding box width and height instead of the width and height directly.)
七.原论文中的网络设计图
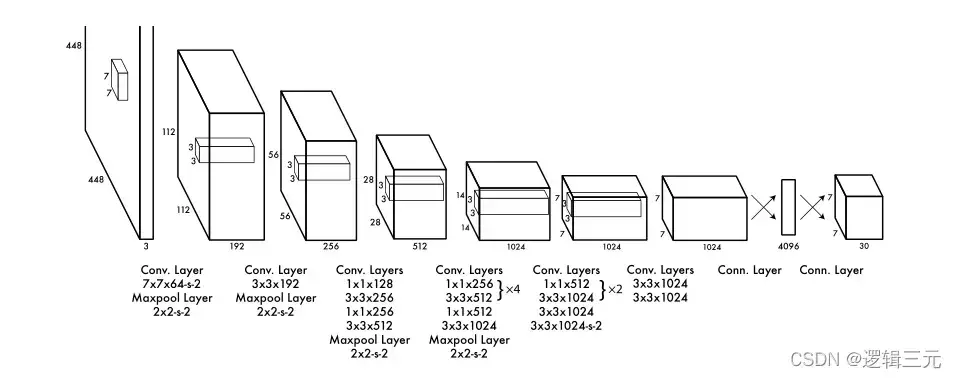
在下一篇文章中我打算将手算的各个步骤的kernel,padding,stride均以图示给出,并且用Pytorch搭建网络并且给出代码。
八.非极大值(maxima)抑制算法(non maximum suppression, NMS)

参考:
目标目标检测|YOLO原理与实现 – 知乎 (zhihu.com)
(26条消息) (pytorch-深度学习(Deep learning)系列)pytorch卷积(convolution)层与池化(Pooling)层输出的尺寸的计算公式详解_我是一颗棒棒糖的博客-CSDN博客_卷积(convolution)和池化(Pooling)输出大小计算
Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 779-788.
文章出处登录后可见!