1 简介
论文题目:Verb Knowledge Injection for Multilingual Event Processing
论文来源:ACL 2021
论文链接:https://arxiv.org/pdf/2012.15421.pdf
1.1 创新
- 提出一个辅助的预训练(pretraining)任务,将动词的相关信息融入到adapter modules中,利用VerbNet 和FrameNet动词中的语义-句法知识提高推理事件的能力。
- 将动词信息从资源丰富的语言扩展到其他资源较少的语言。
2 方法
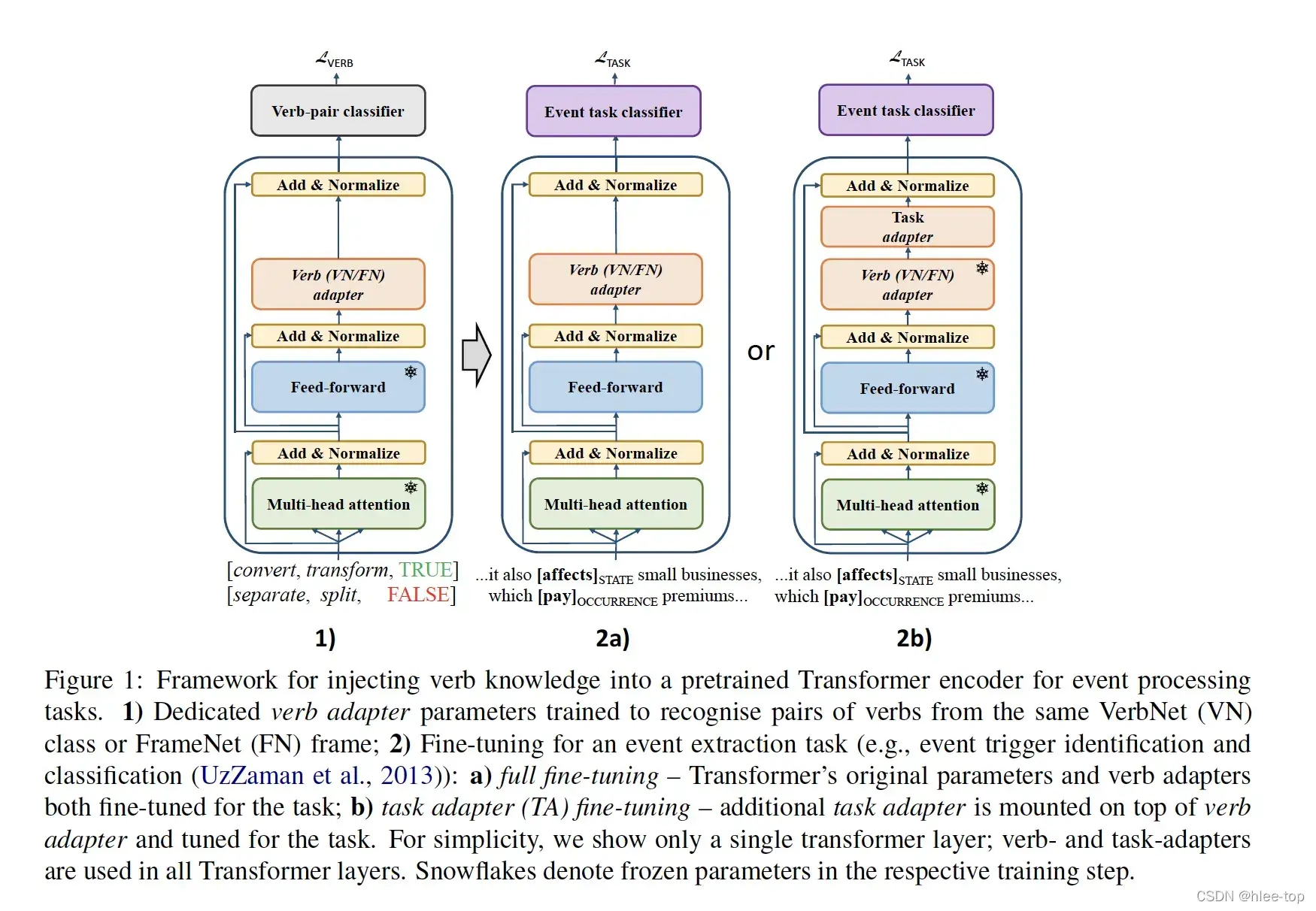
模型的整体框架如上图所示,主要包括以下几个部分:
- Training Task:为了编码(code)动词的信息,设计辅助的预训练(pretraining)任务为词对的二分类(Binary classification)任务(正例和反例),使用Transformer编码(code)的CLS向量,进行分类,Loss为交叉熵(Cross entropy)。
- Adapter Architecture:代替微调(Fine-tuning)全部的Transformer的参数,使用一个Adapter Architecture结构将动词的知识与通用(GPU general purpose GPU)的语言知识分离。该结构包含残差连接的两个全连接层(上投影和下投影),公式如下:
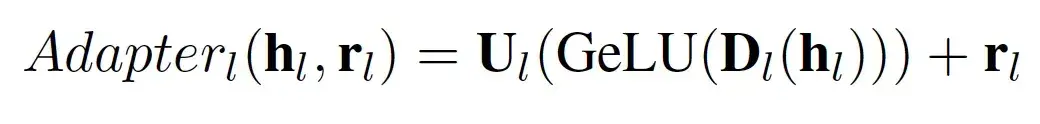
- Fine-Tuning Downstream Task: 下流(stream)任务包括token级的触发词识别和分类(全连接层+分类)、span的事件触发词和论元抽取(序列标注,+CRF)。微调(Fine-tuning)策略包括两个:全部微调(Fine-tuning)(上图2a)、task-adapter微调(Fine-tuning)(上图2b)。
- Cross-Lingual Transfer:包括两种方案,1)在英语动词知识库(Knowledge base)上微调(Fine-tuning)mBERT(multilingual BERT),然后对目标语言的数据进行预测;2)对数据进行翻译,包括三个步骤: (1)使用Relaxed Cross domain Similarity Local Scaling对动词对进行翻译(选择共享语义空间中最近的向量);(2)使用一个二分类(Binary classification)模型(在跨语言的词编码(code)空间进行训练),除去带噪声对翻译数据;(3)使用过滤后的数据进行训练。
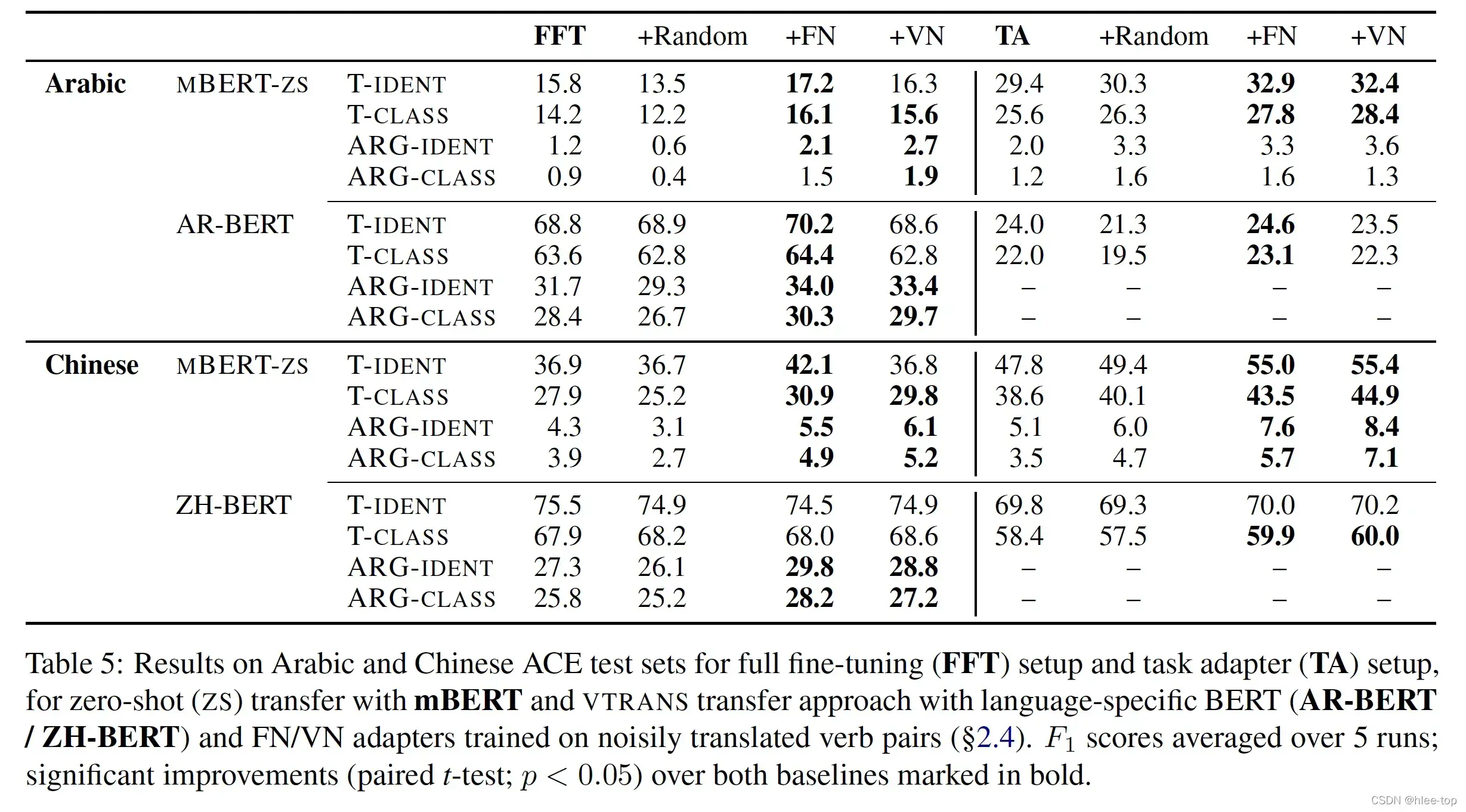
3 实验
实验的数据集(Dataset)为TempEval(进行token的触发词识别和分类)和ACE,实验结果如下图: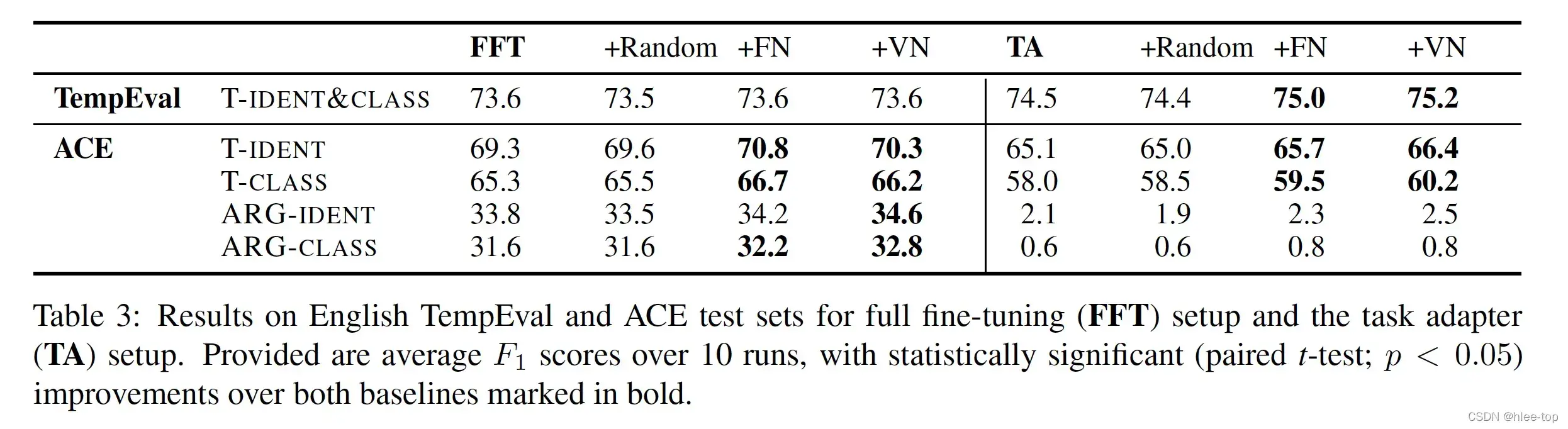
多语言实验结果如下: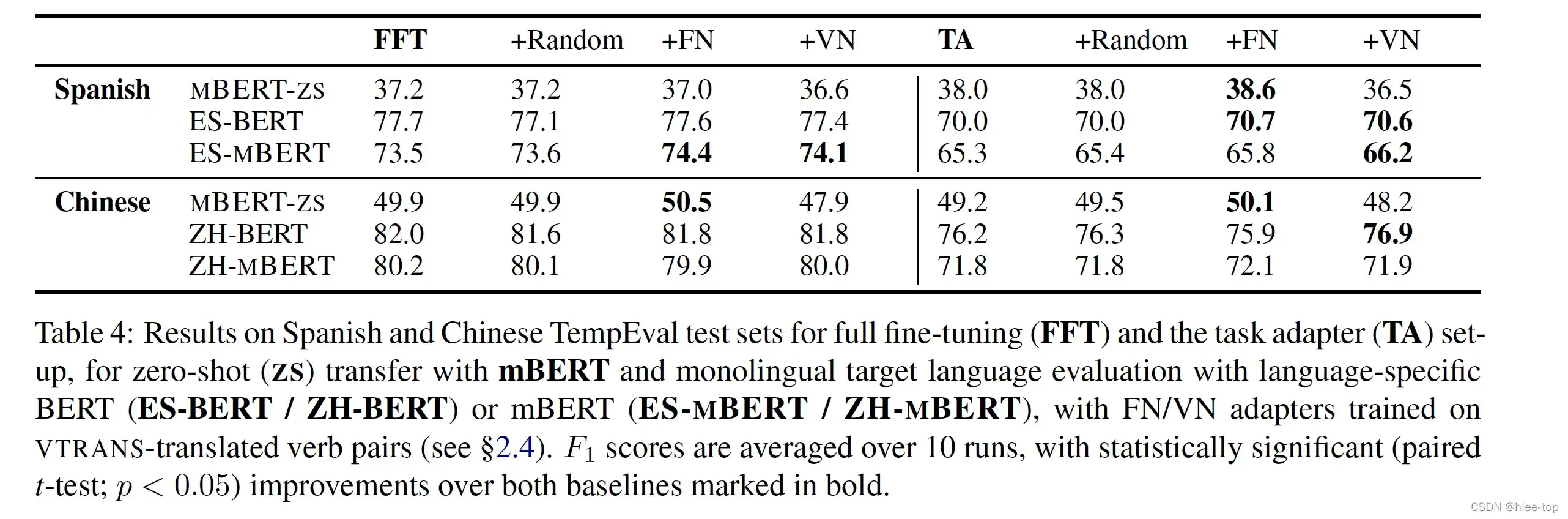
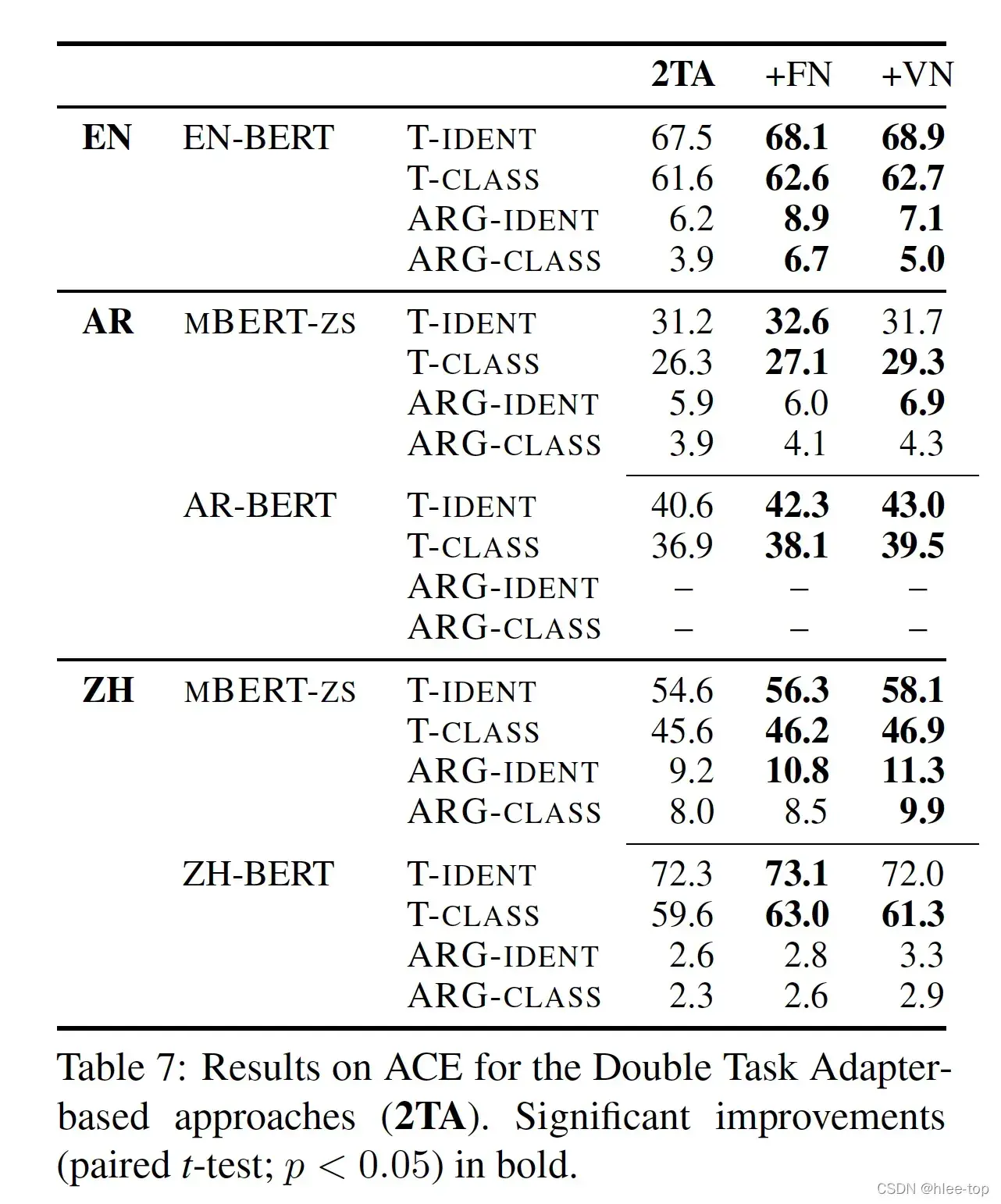
使用双倍参数的Task Adapter,探究Task Adapter的能力,结果如下: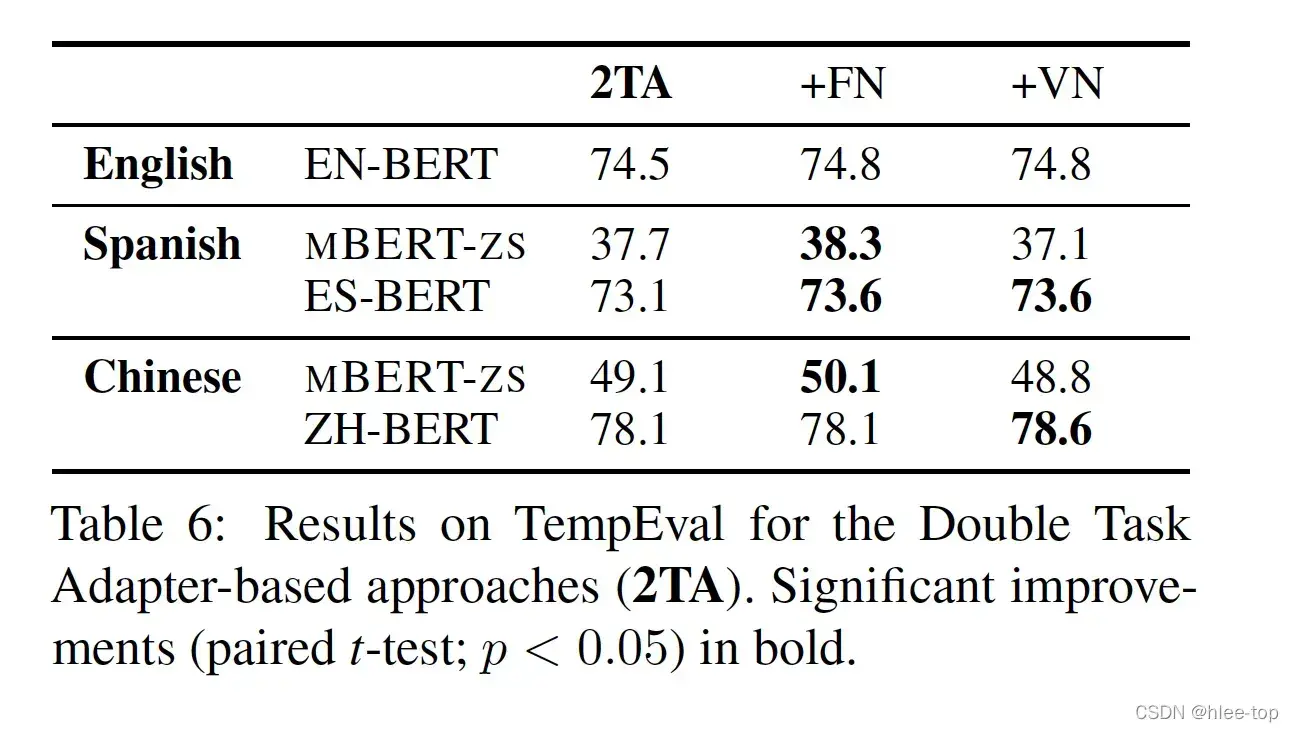
使用无噪声数据的实验效果: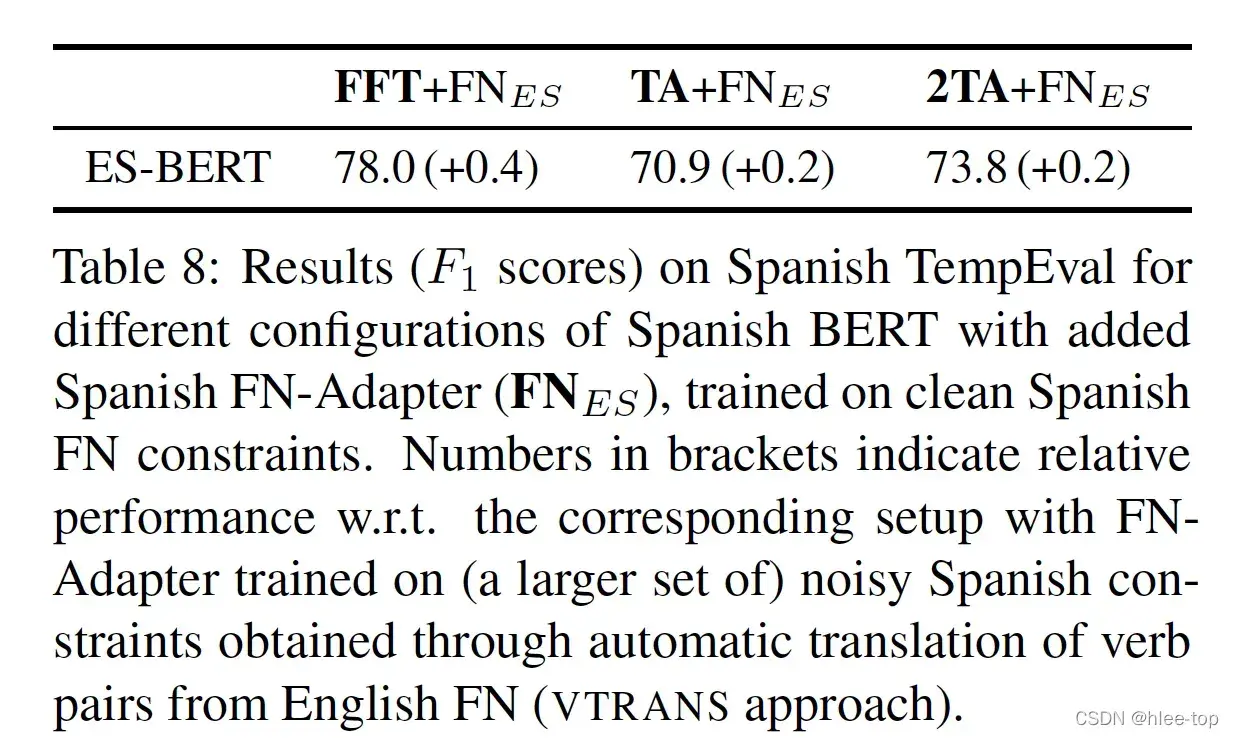
文章出处登录后可见!
已经登录?立即刷新