



Abstract
因此在本文中,我们提出了中文预训练(pretraining)语言模型(language model) StyleBERT,它结合了以下嵌入(Embedding)信息来增强语言模型(language model)的 savvy,例如单词、拼音、五笔和chaizi(拆字)。
Introduction
大规模预训练(pretraining)模型BERT
文本分类的应用
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks, 2019.
Chi Sun, Xipeng Qiu, Yige Xu, and Xuanjing Huang. How to fine-tune bert for text classification?, 2020.中文申请
Haiqin Y ang. Bert meets chinese word segmentation, 2019.
Chen Jia, Y uefeng Shi, Qinrong Yang, and Y ue Zhang。Entity enhanced BERT pre-training for Chinese NER。In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6384– 6396, Online, November 2020。Association for Computational Linguistics。doi:10.18653/v1/2020.emnlp-main.518。URL https://aclanthology.org/2020.emnlp-main.518.很多作品都将汉字字形信息纳入神经模型,但并没有进行大规模的前训练,Sun等[2014],Liu等[2017],Tao等[2019],孟等[2020]。
同一个汉字“数”在语义和句法两个层次上表达不同的读音、不同的意义甚至不同的词类。
提出了 StyleBERT,它首先将“拆字”信息引入到中文预训练(pretraining)过程中,这被证明比其他中文字形信息(例如不同的字体样式信息Chinese bert)更具表现力。为了更好地掌握原始汉字的语义信息,也将单词、拼音、五笔和柴子信息放在一起。
Related work
Bert-wmm
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, and Ziqing Y ang。Pre-training with whole word masking for chinese bert。IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3504–3514, 2021。ISSN 2329-9304。doi:10.1109/taslp.2021.3124365。URL http://dx.doi.org/10.1109/TASLP.2021.3124365.
wmm(whole word masking),中文与英文相比,英文是掩蔽一个单词中的若干个字母,而中文的最小语义是一个汉字,因此与传统掩蔽中文词语中的一个汉字不同,我们可以采用传统的中文分词工具将文本分割成单词,并采用中文整词掩蔽来代替单个汉字

MacBERT
调整掩蔽策略,将15%的输入(input)词进行屏蔽,这部分的80%用相似词替换,10%的部分用随机词替换,剩下的10%作为原词。
Chinese Bert
将汉字的字形和拼音信息纳入语言预训练(pretraining)
因此,我们可以通过结合字形嵌入(Embedding)、拼音嵌入(Embedding)和字符嵌入(Embedding)的融合嵌入(Embedding)来对汉字的独特语义属性进行建模。
字形嵌入(Embedding)适用于不同的中文字体:梨树、行楷、仿宋
Style-Bert
Overview
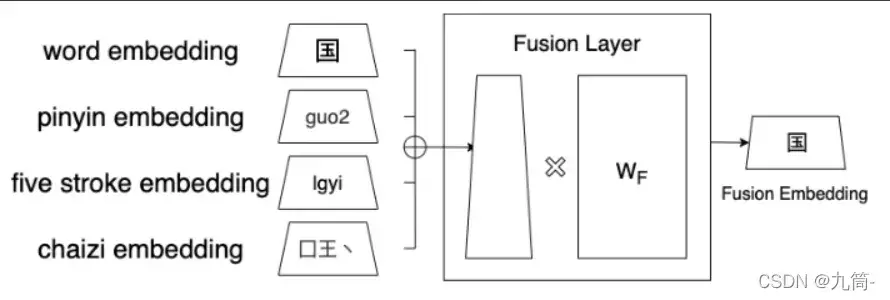
每个输入(input)的汉字都嵌入(Embedding)到词向量、拼音向量、五笔画向量和柴子向量中。这些嵌入(Embedding)向量被发送到融合层以合并到融合向量中。
代替原BERT-base模型中的token embedding
Input
拼音嵌入(Embedding)
在拼音编码(code)过程中,每个给定的符号(symbol)映射为一个8维向量。 每个拼音向量由两部分组成,拼音字母+声调
字形嵌入(Embedding)
汉字结构复杂,不像英文只有横排
因此,汉字的部首结构采用五笔编码(code)和分字编码(code)进行编码(code)。
Wubi Code
中文部首的总量约为1.6k。 五笔编码(code)大大减少了特征空间的大小并捕获了每个字符的几何结构。
然而,五笔画的一个显着缺点是它减少了特征空间,使模型更难收敛(Convergence)。为了减少这个问题的影响,模型中引入了分词编码(code)。
分词编码(code)
分字编码(code)为每个汉字部首分配不同的印记,大大增加了编码(code)空间,保留了更多信息。
在拆字编码(code)过程中引用了一个开源的 github 存储库 Doherty [2015],其中包含每个汉字的部首组合。
Liam Doherty。kfcd/chaizi。https://github.com/kfcd/chaizi, 2015.
在生成拼音、五笔和拆字编码(code)向量后,将这些向量嵌入(Embedding)到embedding向量中,本文对多种嵌入(Embedding)方法进行了测试:
- TextCNN:特征编码(code)向量被送入Text-CNN层,该层使用多个过滤器捕捉编码(code)特征。 这种方法在许多下游任务中表现良好。 然而,Text-CNN层的一个缺点是在训练阶段花费的时间太多,特别是对于较长的语料库。
- 带有注意机制的RNN:为了加速训练过程,Zhou等人[2016]将Text-CNN层替换为RNN层,然后再引入注意层。 此外,该团队还增加了一个跳跃式连接,将输入(input)编码(code)向量添加到RNN层的输出向量中。 这种方法不仅效果好,而且花费的时间也少。
Peng Zhou, Wei Shi, Jun Tian, Zhenyu Qi, Bingchen Li, Hao Hongwei, and Bo Xu. Attention-based bidirectional long short-term memory networks for relation classification. In Meeting of the Association for Computational Linguistics, 2016.
嵌入(Embedding)字符(单词)、语音(拼音)和字形(五笔、拆分字符)

文章出处登录后可见!