Pytorch输出网络中间层特征可视化
本文主要介绍如何提取特定层的特征,然后将其可视化。最后给出了不同网络的应用案例。
推荐一个GITHUN实现可视化的工具地址
总体步骤
- 加载预训练模型
- 使用单个图像作为输入
- 记录要查看的特征提取层的结果
- 网络中的特征提取结果的 shape 为 batch_size, filter_nums, H, W , 因此要使用 transpose 函数对其维度进行转换
- 将 tensor 转为 numpy , 然后根据预处理中 transform 进行的操作将逆操作后得到 [0,1] 区间的图像
- 将得到的 filter_nums 张图片拼接后输出
案例1: 自定义的模型(可修改forward)
1. 存储特征提取结果
没听说过 SiameseNetwork 不重要,只需要知道如何临时存储特征结果并输出即可
最简单的做法就是在forward函数当中截取想要的结果并存储
网络结构如下图
class SiameseNetwork(nn.Module):
def __init__(self):
super().__init__()
self.cnn1 = nn.Sequential(
nn.ReflectionPad2d(1),
nn.Conv2d(1, 4, kernel_size=3),
nn.ReLU(inplace=True),
nn.BatchNorm2d(4),
nn.ReflectionPad2d(1),
nn.Conv2d(4, 8, kernel_size=3),
nn.ReLU(inplace=True),
nn.BatchNorm2d(8),
nn.ReflectionPad2d(1),
nn.Conv2d(8, 8, kernel_size=3),
nn.ReLU(inplace=True),
nn.BatchNorm2d(8),
)
self.fc1 = nn.Sequential(
nn.Linear(8 * 100 * 100, 500),
nn.ReLU(inplace=True),
nn.Linear(500, 500),
nn.ReLU(inplace=True),
nn.Linear(500, 5))
self.fc2 = torch.nn.Linear(5, 1)
def forward_once(self, x, type=1):
output = self.cnn1(x)
if type == 1:
self.featuremap1 = output
else:
self.featuremap2 = output
output = output.view(output.size()[0], -1)
output = self.fc1(output)
return output
def forward(self, input1, input2):
output1 = self.forward_once(input1, 1)
output2 = self.forward_once(input2, 2)
x = torch.abs(output1 - output2)
x = self.fc2(x)
return x
我们需要可视化的通常是卷积后的结果,也就是CNN层的输出,所以这里self.cnn1(x)的结果存放在self.featuremap中
核心代码如下,其中type不重要,与网络的应用有关。
if type == 1:
self.featuremap1 = output
else:
self.featuremap2 = output
2. 加载模型,输入单组图片
SiameseNetwork的输入需要有两张图片,这里我把它封装成一个函数
关键代码已注释
net = SiameseNetwork() # 定义模型
net.load_state_dict(torch.load(f'net30.pth')) # 加载与训练好的模型
transform_test = transforms.Compose([transforms.Resize((100, 100)),
transforms.ToTensor()]) # 定义预处理操作
def test_one(path1, path2):
'''单对图片测试'''
img1 = Image.open(path1).convert('L')
img2 = Image.open(path2).convert('L')
img_tensor1 = transform_test(img1)
img_tensor2 = transform_test(img2)
img_tensor1.unsqueeze_(0) # 给tensor添加一个维度,模拟为batch=1
img_tensor2.unsqueeze_(0)
output = net(img_tensor1, img_tensor2) # 单组图片进入网络得到结果
feature_output1 = net.featuremap1.transpose(1, 0).cpu()
feature_output2 = net.featuremap2.transpose(1, 0).cpu()
feature_out1 = torchvision.utils.make_grid(feature_output1)
feature_out2 = torchvision.utils.make_grid(feature_output2)
feature_imshow(feature_out1, 'feature_out1')
feature_imshow(feature_out2, 'feature_out2')
# euclidean_distance = F.pairwise_distance(output1, output2)
euclidean_distance = torch.sigmoid(output)
concatenated = torch.cat((img_tensor1, img_tensor2), 0)
imshow(torchvision.utils.make_grid(concatenated), 'Similarity: {:.2f}'.format(euclidean_distance.item()))
下面详细介绍提取特征的功能。使用net.featuremap1操作获取特征。这里的featuremap1也对应我之前存放时的self.featuremap1。
transpose(1, 0).cpu()是因为此时的特征是torch.Size([1, 8, 100, 100]),也就是(batch_size, filter_nums, H, W)转换后可以很方便的输出
feature_output1 = net.featuremap1.transpose(1, 0).cpu()
feature_output2 = net.featuremap2.transpose(1, 0).cpu()
下面的代码是将若干幅图像拼成一幅图像, 在本文中feature_output有8张图片, 具体可以去百度搜torchvision.utils.make_grid功能
feature_out1 = torchvision.utils.make_grid(feature_output1)
feature_out2 = torchvision.utils.make_grid(feature_output2)
最重要的可视化功能是feature_imshow
先读入inp,转换成想要的plt格式
因为本文使用的transform没有针对mean和std进行处理,所以传入的图像默认在(0,1)之间,所以这里不需要进行逆向操作,下面的其他案例会针对这种情况给出解决方案。np.clip(inp, 0, 1) 小于0的像素变成0,大于1的像素变成1
否则会产生如下错误信息
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
剩下的就是简单的plt介绍,没什么好解释的。
def feature_imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.detach().numpy().transpose((1, 2, 0)) # 将通道数放在最后一维
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
3. 中间层特征结果
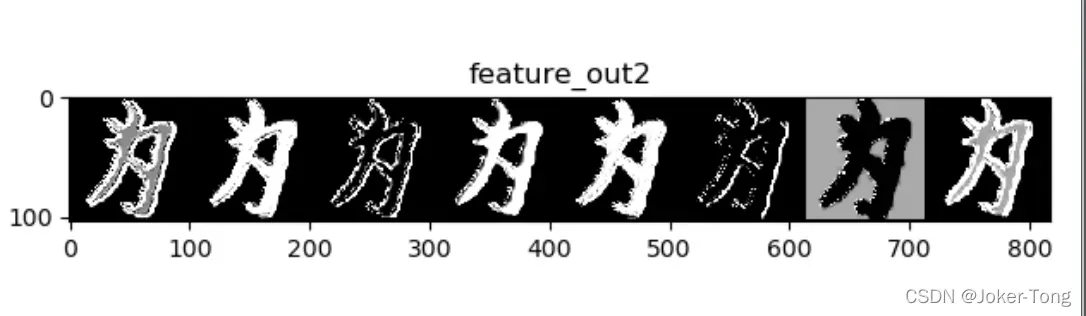
这里做的是汉字和输入图片的对比。下图是特征提取后的结果,汉字的特征学习的很清楚。
案例2: torchvision.models中的预训练模型
详细的流程已经在上面讲了, 这里就给出此类pretrain过的模型应该如果输出中间结果的思路, 以inceptionV3为例
1.加载模型
这个模型可以直接从自带的类中下载models
model = models.inception_v3(pretrained=True, aux_logits=False)

2. 便利模型
以下代码可用于方便联网,但通常在forwad中完成
for name, layer in model.named_modules():
if 'conv' in name:
print(layer)
扩展:卷积层的结构可以通过以下简单的方式保存
out_put = []
for name, layer in model.named_modules():
x = layer(x)
if 'conv' in name:
out_put.append(layer(x))

for name, layer in model.named_modules():
if name == '0':
feature_layer = nn.Sequential(*list(layer.children())[:2])
print(feature_layer)
这里,*list(layer.children())[:2]用于解包网络并选择所需的部分
因为这是网络的第一层,所以可以直接使用。如果要在网络的后面一层进行卷积操作,则需要确保前面的过程也完成。
3. 可视化中间特征
因为本案中的transforms,我去定制mean和std进行Normalize
tf = transforms.Compose([
transforms.Resize(299),
transforms.RandomRotation(15),
transforms.CenterCrop(resize),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
因此,在feature_imshow函数中,我们可以使用mean和std对图像进行归一化处理,以获得更好的呈现效果。
def feature_imshow(inp, title=None):
inp = inp.detach().numpy().transpose((1, 2, 0))
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.axis('off')
plt.pause(0.001) # pause a bit so that plots are updated
plt.clf()
输入图像
中级特征(这里没有专门训练,用pretrain跑就行了)
文章出处登录后可见!