作为kaggle最最入门的新手村长期比赛之一,通过参考大佬们的作业,自己尝试了一下这个demo,可以很好的让萌新体验一次传统机器学习的大体流程。
首先附上本博客原文地址供参考,欢迎大家加入我们:
Kaggle平台Titanic生存率预测项目(TOP3%) – 知乎![]() https://zhuanlan.zhihu.com/p/50194676
https://zhuanlan.zhihu.com/p/50194676
作为一个新入行的记录,我会提一下我当时遇到的一些细节,以及一些我个人理解(不是)的暴力理论,请多多指教。
1. 数据采集
kaggle注册这方面我就先不说了,这里附上网址,可以根据这里的下载图标进行数据集下载
Kaggle-Titanic![]() https://www.kaggle.com/competitions/titanic/overview
https://www.kaggle.com/competitions/titanic/overview
当然也可以通过代码直接下载到本地,但是对萌新可能不太友好。我不会在这里详细介绍。你可以自己找到方法。
一共三个csv文件,训练集和测试集,还有一个提交版本的csv样例。我们最终提交的文件是根据测试集预测出来的文件,该文件格式需要与gender_submission相一致。网络不好的同学可以根据文末链接下载对应数据。

2.数据观察
这部分不是必须的,但是可以让我们对数据有个大概的了解,有一定基础的可以直接跳到第三部分。
import warnings
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt# 忽略部分版本警告
warnings.filterwarnings('ignore')
#设置sns样式
sns.set(style='white',context='notebook',palette='muted')
#导入数据
train=pd.read_csv('./train.csv')
test=pd.read_csv('./test.csv')# 合并数据集
full = train.append(test, ignore_index=True)
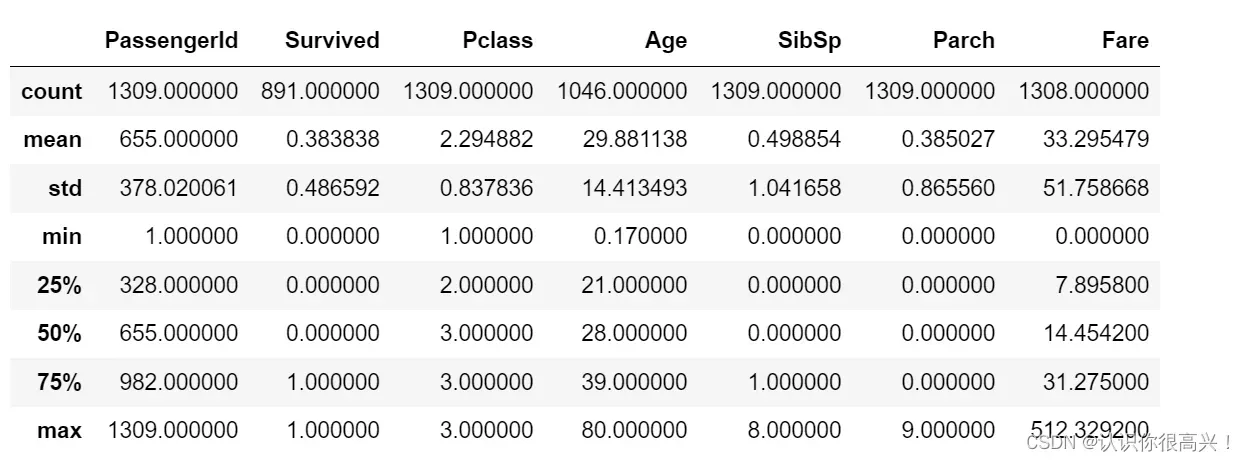
full.describe()
# full.info()可以看到一些数据的大致分布和比例,但是这些列意义不大。
这里可以看出港口不同对生存率的影响,也可以试试其他参数,将‘Embarked’以及S、C、Q等相应参数进行替换即可。
# 计算不同类型embarked的乘客,其生存率为多少
# S:南安普顿港southampton;Q:皇后镇 Queentown;C:瑟堡 Cherbourg
print('Embarked为"S"的乘客,其生存率为%.2f' % full['Survived'][full['Embarked'] == 'S'].value_counts(normalize=True)[1])
print('Embarked为"C"的乘客,其生存率为%.2f' % full['Survived'][full['Embarked'] == 'C'].value_counts(normalize=True)[1])
print('Embarked为"Q"的乘客,其生存率为%.2f' % full['Survived'][full['Embarked'] == 'Q'].value_counts(normalize=True)[1])法国登机旅客存活率较高的原因可能与头等舱旅客比例较高有关。
sns.catplot('Pclass', col='Embarked', data=train, kind='count', height=3)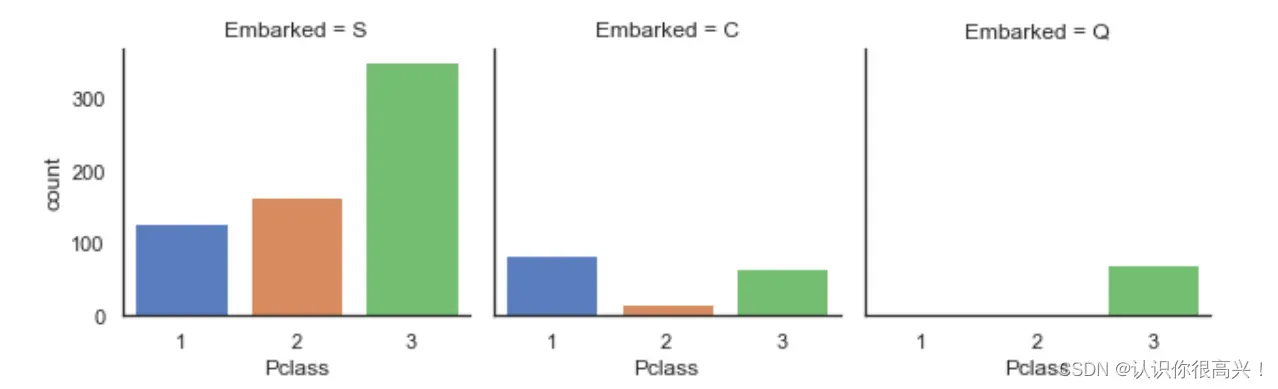
Parch与Survived:当乘客同行的父母及子女数量适中时,生存率较高。
sns.barplot(data=train, x='Parch', y='Survived')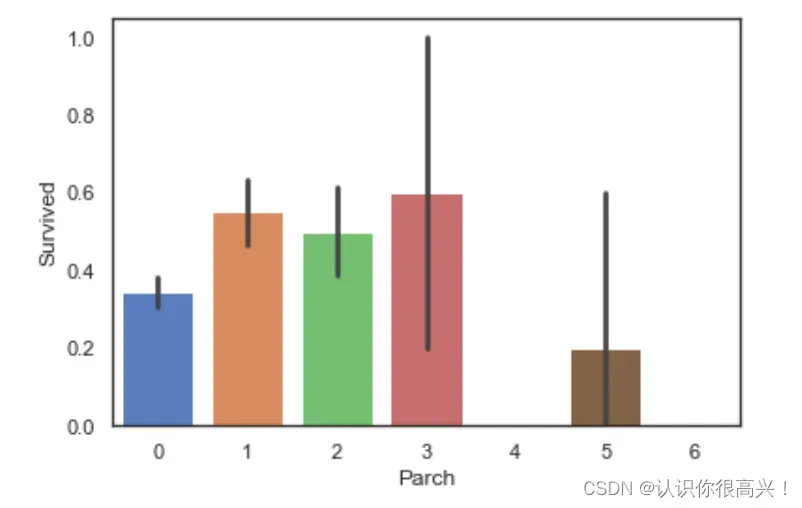
同理可以比较不同的数据,这里就不放结果图了。
# SibSp与Survived:当乘客同行的同辈数量适中时生存率较高
sns.barplot(data=train, x='SibSp', y='Survived')
# Pclass与Survived:乘客客舱等级越高,生存率越高
sns.barplot(data=train, x='Pclass', y='Survived')
# Sex与Survived:女性的生存率远高于男性
sns.barplot(data=train, x='Sex', y='Survived')Age与Survived:当乘客年龄段在0-10岁期间时生存率会较高。
ageFacet = sns.FacetGrid(train, hue='Survived', aspect=3) # 创建坐标轴
ageFacet.map(sns.kdeplot, 'Age', shade=True) # 作图,选择图形类型
ageFacet.set(xlim=(0, train['Age'].max())) # 其他信息:坐标轴范围、标签等
ageFacet.add_legend()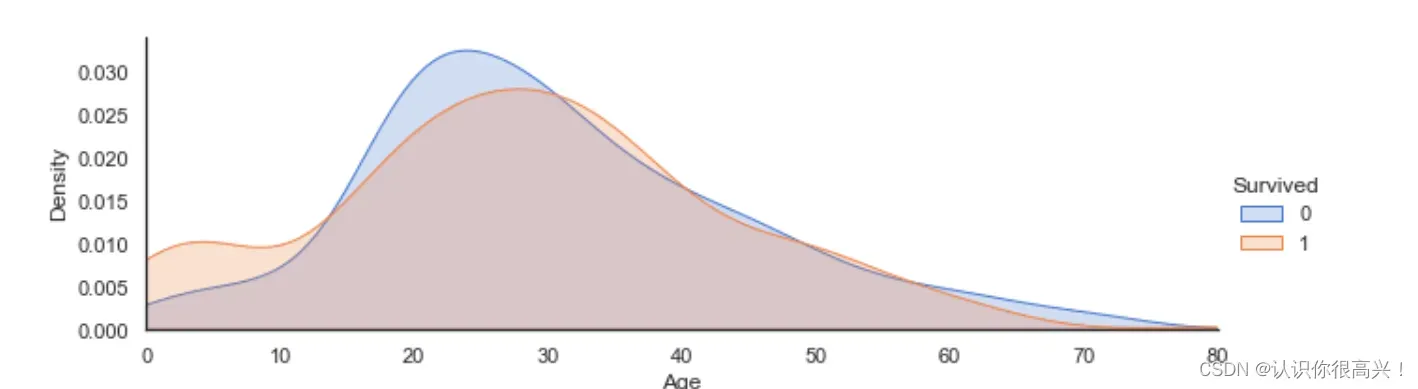
Fare与Survived:当票价低于18左右时乘客生存率较低,票价越高生存率一般越高。
ageFacet = sns.FacetGrid(train, hue='Survived', aspect=3) # 创建坐标轴
ageFacet.map(sns.kdeplot, 'Fare', shade=True)
ageFacet.set(xlim=(0, 150))
ageFacet.add_legend()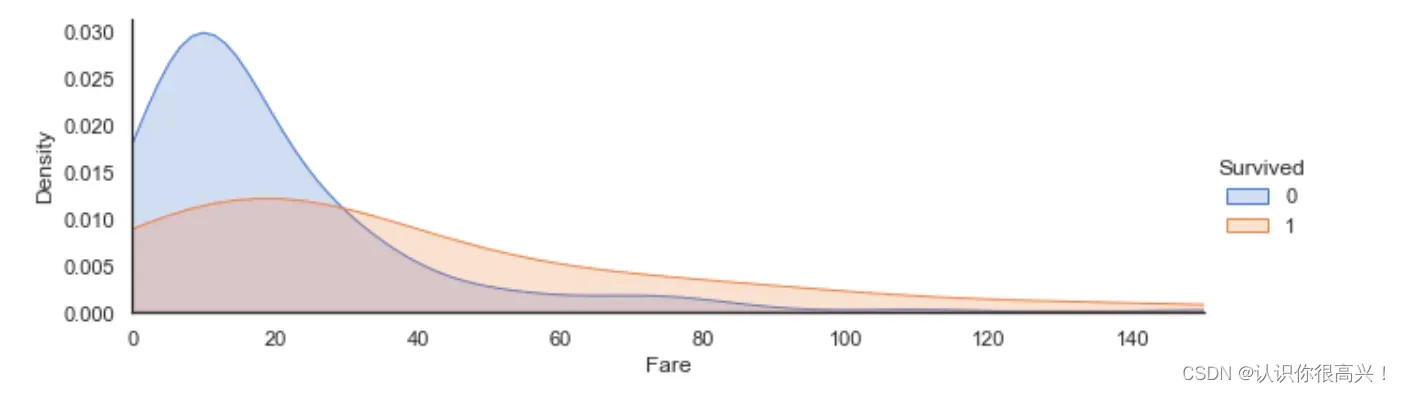
查看fare(票价)分布。
farePlot = sns.distplot(full['Fare'][full['Fare'].notnull()], label='skewness:%.2f' % (full['Fare'].skew()))
farePlot.legend(loc='best')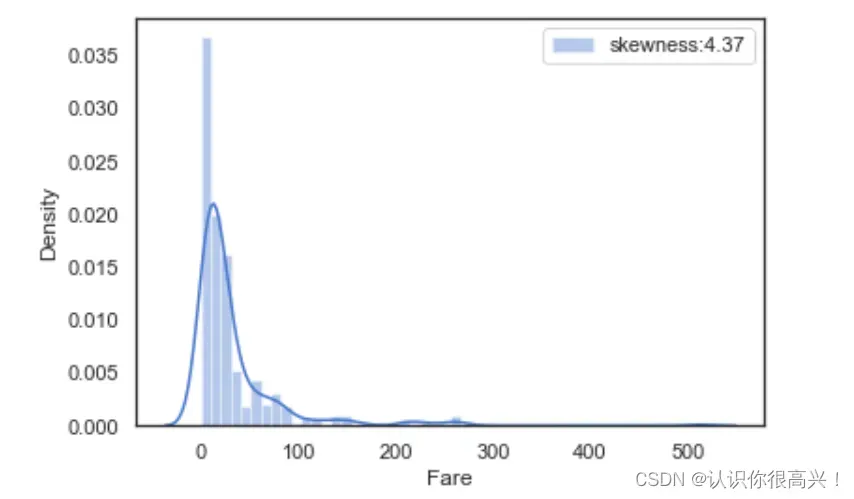
以上查看方式同样适用于其他基础机器学习数据集。可以尝试改变参数,更好地观察数据的相关性,为后续构建特征工程和群体识别做准备。
3. 数据预处理
这里新开一个jupyter,需要导入的包如下(调包侠是我了)。
import warnings
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import roc_curve, auc
from sklearn.ensemble import RandomForestClassifier,GradientBoostingClassifier,ExtraTreesClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV,cross_val_score,StratifiedKFold# 忽略部分版本警告
warnings.filterwarnings('ignore')
#设置sns样式
sns.set(style='white',context='notebook',palette='muted')
#导入数据
train=pd.read_csv('./train.csv')
test=pd.read_csv('./test.csv')
full = train.append(test, ignore_index=True)3.1对cabin船舱标签进行缺失值填充
这里要介绍几种缺失值的处理方式,我们会一一使用。
第一种是直接填写“不创建”,我想称之为“烂数据”,一般意义不大的数据可以尝试填写。而且就算让我们填好,也填不上(捂脸)。
#对Cabin缺失值进行处理,利用U(Unknown)填充缺失值
full['Cabin']=full['Cabin'].fillna('U')
full['Cabin'].head()3.2对Embarked登船港口标签进行缺失值填充
第二种:填写众数,平均值,或者概率最高的一个标签。
#对Embarked缺失值进行处理,查看缺失值情况
full[full['Embarked'].isnull()]
查看Embarked数据分布情况,可知在英国南安普顿登船可能性最大,因此以此填充缺失值。
full['Embarked']=full['Embarked'].fillna('S')
full['Embarked'].value_counts()fare票价同样的处理方式,不过这次采取的是平均值。
# 利用3等舱,登船港口为英国,舱位未知旅客的平均票价来填充缺失值。
full['Fare']=full['Fare'].fillna(full[(full['Pclass']==3)&(full['Embarked']=='S')&(full['Cabin']=='U')]['Fare'].mean())第三种:预测后填充
某些类型的数据对我们来说太重要了,无法以常规方式直接添加。比如这个案例的年龄数据,稍微头脑风暴一下就可以感受到。预测最终的存活率非常重要。我们可以尝试“预测年龄”并稍后填写。但是我们需要在预测年龄之前对数据进行进一步的处理,所以我们先挖个坑。
4. 特征工程
首先,我们愿意相信某些标签下只有几条数据,所以预测效果肯定不会很好。我们可以尝试“暴力更改”它们的一些标签,将大致相同类型的标签合并。在这种情况下,名称就是标题。例子。
4.1name中头衔信息提取
旅客姓名数据中包含头衔信息,不同头衔也可以反映旅客的身份,而不同身份的旅客其生存率有可能会出现较大差异。因此通过Name特征提取旅客头衔Title信息,并分析Title与Survived之间的关系。
#构造新特征Title
full['Title']=full['Name'].map(lambda x:x.split(',')[1].split('.')[0].strip())
#查看title数据分布
full['Title'].value_counts()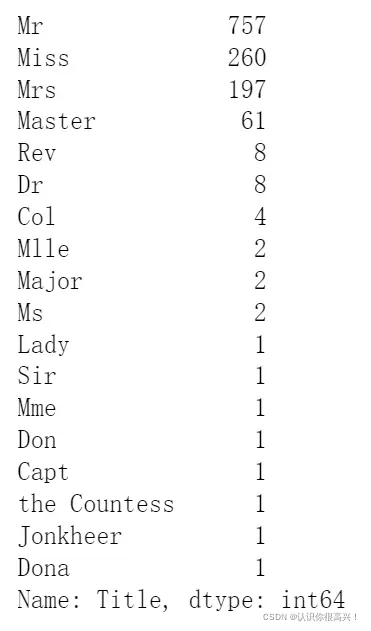
如您所见,有很多标题,我们可以选择合并一些标题
# 将相近的特征整合在一起
TitleDict={}
TitleDict['Mr']='Mr'
TitleDict['Mlle']='Miss'
TitleDict['Miss']='Miss'
TitleDict['Master']='Master'
TitleDict['Jonkheer']='Master'
TitleDict['Mme']='Mrs'
TitleDict['Ms']='Mrs'
TitleDict['Mrs']='Mrs'
TitleDict['Don']='Royalty'
TitleDict['Sir']='Royalty'
TitleDict['the Countess']='Royalty'
TitleDict['Dona']='Royalty'
TitleDict['Lady']='Royalty'
TitleDict['Capt']='Officer'
TitleDict['Col']='Officer'
TitleDict['Major']='Officer'
TitleDict['Dr']='Officer'
TitleDict['Rev']='Officer'
full['Title']=full['Title'].map(TitleDict)
full['Title'].value_counts()合并后的结果如下,将较少的标签合并到剩余的类别中。

4.2FamilyNum及FamilySize信息提取
是时候再次弥补它了。如果发生海难,七八口之家的生存率与普通三口之家的生存率应该会有很大差异。人数越多,存活率越低。如果人数太少,可能是因为无用的原因。导致较低的存活率。
于是我们将Parch及SibSp字段整合,得到一名乘客同行家庭成员总人数FamilyNum的字段。再根据家庭成员具体人数的多少得到家庭规模FamilySize这个新字段。
full['familyNum']=full['Parch']+full['SibSp']+1
# 查看familyNum与Survived
sns.barplot(data=full,x='familyNum',y='Survived')
可以看出,家庭成员人数在2-4人时,乘客的生存率较高,当没有家庭成员同行或家庭成员人数过多时生存率较低,脑补成功。
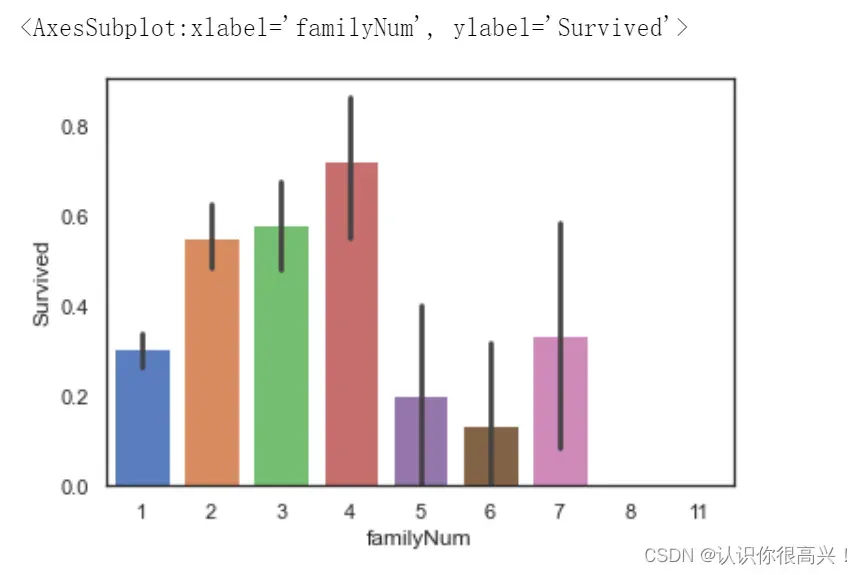
但是这里我们虽然挖掘到了数据中本不存在的信息,但是凭空增加了一类标签,而且观察发现,2-4类别的生存率可能不会有太大差别,在这里可以尝试将类别合并,按照家庭成员人数多少,将家庭规模分为“小、中、大”三类:
# 按照家庭成员人数多少,将家庭规模分为“小、中、大”三类:
def familysize(familyNum):
if familyNum==1:
return 0
elif (familyNum>=2)&(familyNum<=4):
return 1
else:
return 2
full['familySize']=full['familyNum'].map(familysize)
full['familySize'].value_counts()
# 查看familySize与Survived
sns.barplot(data=full,x='familySize',y='Survived')
# 当家庭规模适中时,乘客的生存率更高。看图说话,有理有据,有说服力。 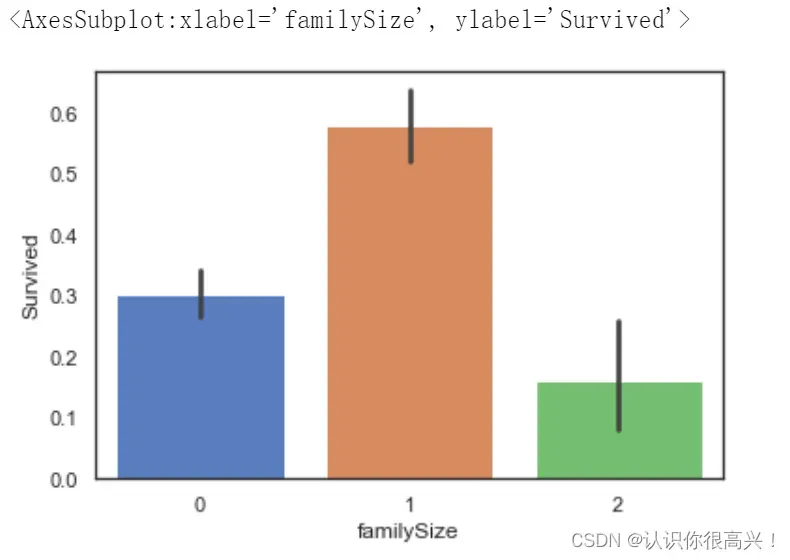
4.3共票号乘客数量TickCot及TickGroup
这里思路与上方思路一致,同一票号的乘客数量可能不同,可能也与乘客生存率有关系。我们构建这一关系,并且发现当TickCot大小适中时,乘客生存率较高。并且为了降低数据的复杂性,可以按照TickCot大小,将TickGroup分为三类。在代码中进行了详细说明,此处不在赘述。
4.4Age缺失值填充-构建随机森林模型预测缺失的数据
你还记得我们的时代还没有完成吗?在我们进行了上述数据处理和特征工程之后,数据变得更加“立体”了,我们可以开始预测年龄了,但这毕竟不是。要直接预测存活率,我们只能挑出部分数据和一个模型。
查看Age与Parch、Pclass、Sex、SibSp、Title、familyNum、familySize、Deck、TickCot、TickGroup等变量的相关系数大小,筛选出相关性较高的变量构建预测模型。
full[full['Age'].isnull()].head()这里可以粗略的看一下前5条没有年龄的数据,从中挑选几条对应特征较好的数据进行后续预测。列数很大,这里没有截断。 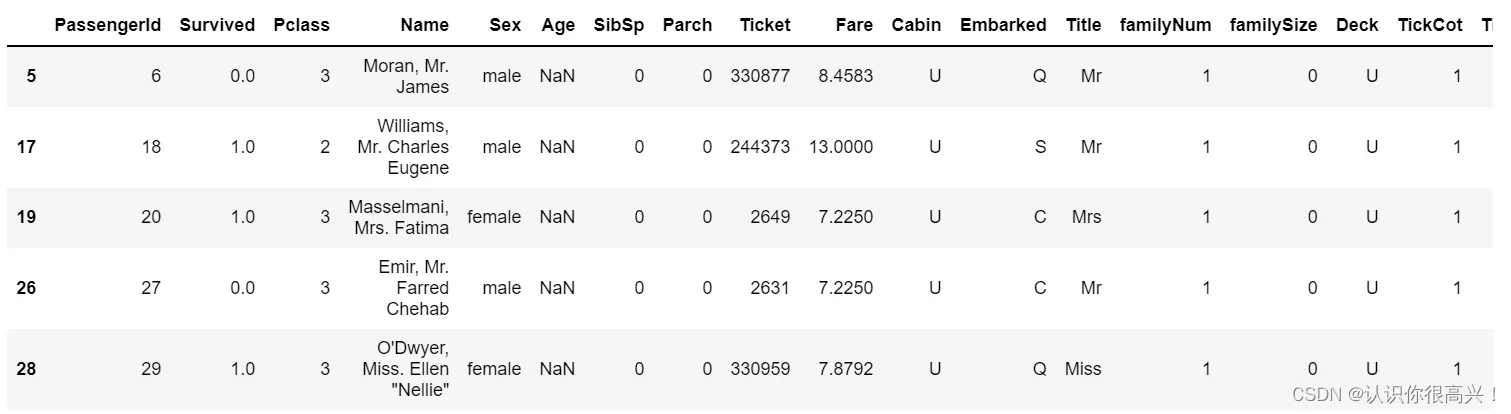
4.4.1筛选数据
#筛选数据集
AgePre=full[['Age','Parch','Pclass','SibSp','Title','familyNum','TickCot']]
#进行one-hot编码
AgePre=pd.get_dummies(AgePre)
ParAge=pd.get_dummies(AgePre['Parch'],prefix='Parch')
SibAge=pd.get_dummies(AgePre['SibSp'],prefix='SibSp')
PclAge=pd.get_dummies(AgePre['Pclass'],prefix='Pclass')
#查看变量间相关性
AgeCorrDf=pd.DataFrame()
AgeCorrDf=AgePre.corr()
AgeCorrDf['Age'].sort_values()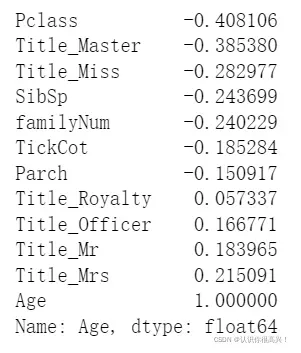
根据相关性,将相关数据拼接起来,看前5个,因为之前已经进行了one-hot编码,列数明显增加。
AgePre=pd.concat([AgePre,ParAge,SibAge,PclAge],axis=1)
AgePre.head()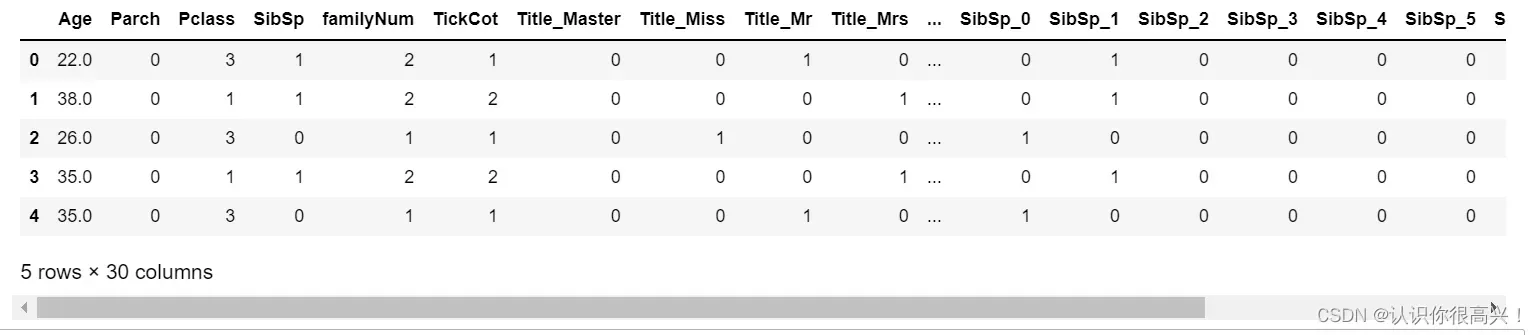
4.4.2拆分数据并建立模型(利用随机森林构建模型)
#拆分实验集和预测集
AgeKnown=AgePre[AgePre['Age'].notnull()]
AgeUnKnown=AgePre[AgePre['Age'].isnull()]
#生成实验数据的特征和标签
AgeKnown_X=AgeKnown.drop(['Age'],axis=1)
AgeKnown_y=AgeKnown['Age']
#生成预测数据的特征
AgeUnKnown_X=AgeUnKnown.drop(['Age'],axis=1)
#利用随机森林构建模型
rfr=RandomForestRegressor(random_state=None,n_estimators=500,n_jobs=-1)
rfr.fit(AgeKnown_X,AgeKnown_y)4.43利用模型进行预测并填入原数据集中
#预测年龄
AgeUnKnown_y=rfr.predict(AgeUnKnown_X)
#填充预测数据
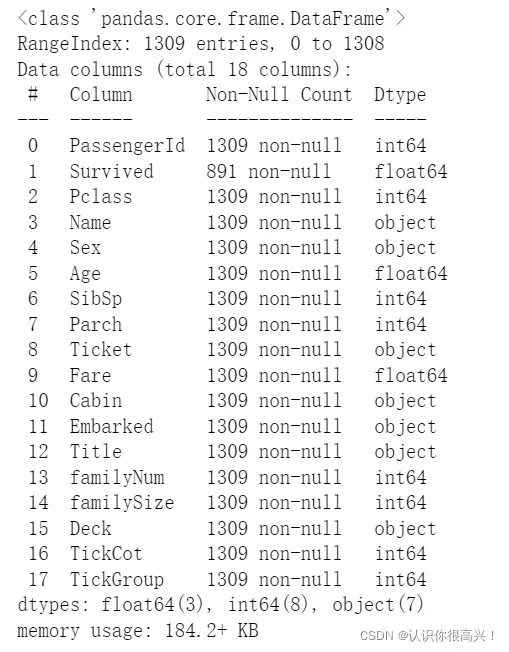
full.loc[full['Age'].isnull(),['Age']]=AgeUnKnown_y
full.info() 至此,没有缺失值,数据处理完成。
五、同组识别
虽然可以通过分析数据中已有特征和标签之间的关系来构建有效的预测模型,但一些具有明显共同特征的用户可能与整体模型逻辑不一致。
如果将这部分具有同组效应的用户识别出来并对其数据加以修正,就可以有效提高模型的准确率。在Titancic案例中,我们主要探究相同姓氏的乘客是否存在明显的同组效应。提取两部分数据,分别查看其“姓氏”是否存在同组效应。因为性别和年龄与乘客生存率关系最为密切,因此用这两个特征作为分类条件。
人类版:有些数据太离谱了。数据虽然烂了,但我们不舍得丢弃。以暴力改变性别”、“以暴力改变年龄”等。
5.1 12岁以上男性:找出男性中同姓氏均获救的部分
#提取乘客的姓氏及相应的乘客数
full['Surname']=full['Name'].map(lambda x:x.split(',')[0].strip())
SurNameDict={}
SurNameDict=full['Surname'].value_counts()
full['SurnameNum']=full['Surname'].map(SurNameDict)
#将数据分为两组
MaleDf=full[(full['Sex']=='male')&(full['Age']>12)&(full['familyNum']>=2)]
FemChildDf=full[((full['Sex']=='female')|(full['Age']<=12))&(full['familyNum']>=2)]
MSurNamDf=MaleDf['Survived'].groupby(MaleDf['Surname']).mean()
MSurNamDf.head()
MSurNamDf.value_counts()
大多数同姓氏的男性存在“同生共死”的特点,因此利用该同组效应,对生存率为1的姓氏里的男性数据进行修正,提升其预测为“可以幸存”的概率。
MSurNamDict={}
MSurNamDict=MSurNamDf[MSurNamDf.values==1].index
MSurNamDict以下是符合调整的乘客姓名:

5.2 女性以及年龄在12岁以下儿童:找出女性及儿童中同姓氏均遇难的部分。
#分析女性及儿童同组效应
FCSurNamDf=FemChildDf['Survived'].groupby(FemChildDf['Surname']).mean()
FCSurNamDf.head()
FCSurNamDf.value_counts()与男性组特征相似,女性及儿童也存在明显的“同生共死”的特点,因此利用同组效应,对生存率为0的姓氏里的女性及儿童数据进行修正,提升其预测为“并未幸存”的概率。
#获得生存率为0的姓氏
FCSurNamDict={}
FCSurNamDict=FCSurNamDf[FCSurNamDf.values==0].index
FCSurNamDict
下面是变化数据,可以看到新手难以理解的操作:
#对数据集中这些姓氏的男性数据进行修正:1、性别改为女;2、年龄改为5。
full.loc[(full['Survived'].isnull())&(full['Surname'].isin(MSurNamDict))&(full['Sex']=='male'),'Age']=5
full.loc[(full['Survived'].isnull())&(full['Surname'].isin(MSurNamDict))&(full['Sex']=='male'),'Sex']='female'
#对数据集中这些姓氏的女性及儿童的数据进行修正:1、性别改为男;2、年龄改为60。
full.loc[(full['Survived'].isnull())&(full['Surname'].isin(FCSurNamDict))&((full['Sex']=='female')|(full['Age']<=12)),'Age']=60
full.loc[(full['Survived'].isnull())&(full['Surname'].isin(FCSurNamDict))&((full['Sex']=='female')|(full['Age']<=12)),'Sex']='male'6.过滤子集
在对数据进行分析处理的过程中,数据的维度上升,为提升数据有效性需要对数据进行降维处理。通过找出与乘客生存率“Survived”相关性更高的特征,剔除重复的且相关性较低的特征,从而实现数据降维。
人类版:数据太多,但是机器不认为年龄比舱名更重要,我们删除一些数据,或者其他降维处理。
这里只展示人工去除的方式,因为在本demo中,盲目使用sklearn自带的降维函数,准确率波动太大,得不偿失,而手撕降维代码或者更改参数不在本萌新讨论范围之内(留下了菜狗的泪水)。
fullSel=full.drop(['Cabin','Name','Ticket','PassengerId','Surname','SurnameNum'],axis=1)
#查看各特征与标签的相关性
corrDf=pd.DataFrame()
corrDf=fullSel.corr()
corrDf['Survived'].sort_values(ascending=True)
# 查看Survived与其他特征间相关性大小。
plt.figure(figsize=(8,8))
sns.heatmap(fullSel[['Survived','Age','Embarked','Fare','Parch','Pclass',
'Sex','SibSp','Title','familyNum','familySize','Deck',
'TickCot','TickGroup']].corr(),cmap='BrBG',annot=True,
linewidths=.5)
# plt.xticks(rotation=45)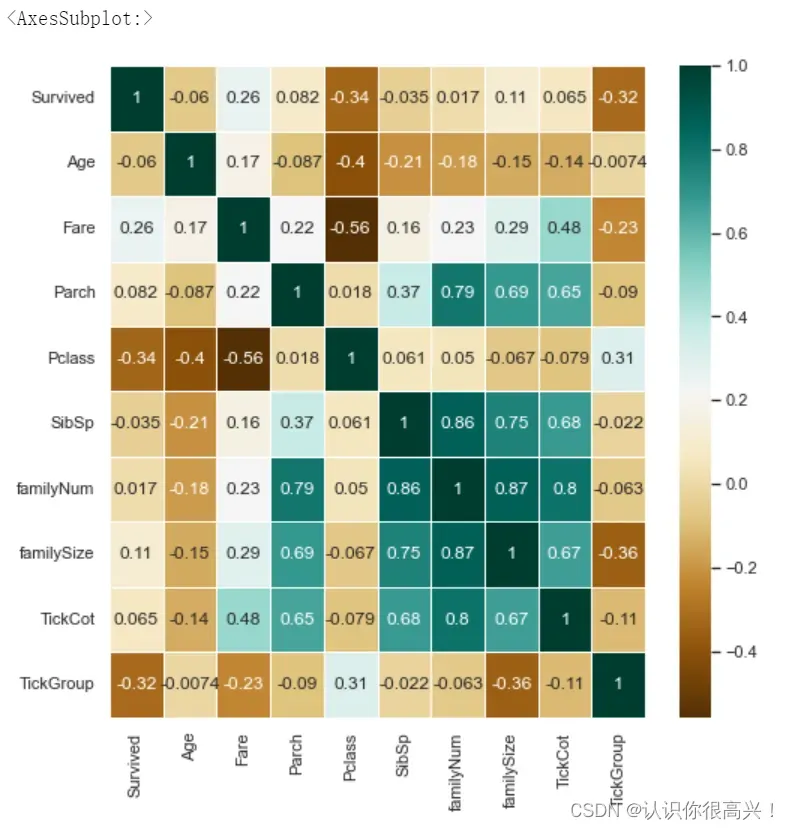
首先,对与标签预测明显不相关或相关性较低的特征进行初步人工筛选,然后检查剩余特征与标签的相关性,进一步降维。
fullSel=fullSel.drop(['familyNum','SibSp','TickCot','Parch'],axis=1)
#one-hot编码
fullSel=pd.get_dummies(fullSel)
PclassDf=pd.get_dummies(full['Pclass'],prefix='Pclass')
TickGroupDf=pd.get_dummies(full['TickGroup'],prefix='TickGroup')
familySizeDf=pd.get_dummies(full['familySize'],prefix='familySize')
fullSel=pd.concat([fullSel,PclassDf,TickGroupDf,familySizeDf],axis=1)七:建立预测模型
7.1模型选择
7.1.1建立各种模型
#拆分实验数据与预测数据
experData=fullSel[fullSel['Survived'].notnull()]
preData=fullSel[fullSel['Survived'].isnull()]
experData_X=experData.drop('Survived',axis=1)
experData_y=experData['Survived']
preData_X=preData.drop('Survived',axis=1)一般到这里,新的入门级机器学习之路可以暂时告一段落。接下来的路主要是调整包,这些包里面的内容比较深奥,而且参数调整也很讲究,我们可以暂时使用默认值(不传参数)。
有许多您从未听说过的算法。可以参考我的这个小总结,主要是从其他博主那里收集的(都不是你自己的),和这里出现的算法名称相对应。让我们看看图片。这是链接
#设置kfold,交叉采样法拆分数据集
kfold=StratifiedKFold(n_splits=10)
#汇总不同模型算法
classifiers=[]
classifiers.append(SVC())
classifiers.append(DecisionTreeClassifier())
classifiers.append(RandomForestClassifier())
classifiers.append(ExtraTreesClassifier())
classifiers.append(GradientBoostingClassifier())
classifiers.append(KNeighborsClassifier())
classifiers.append(LogisticRegression())
classifiers.append(LinearDiscriminantAnalysis())7.1.2比较各种算法结果,进一步选择模型
#不同机器学习交叉验证结果汇总
cv_results=[]
for classifier in classifiers:
cv_results.append(cross_val_score(classifier,experData_X,experData_y,
scoring='accuracy',cv=kfold,n_jobs=-1))# 求出模型得分的均值和标准差
cv_means=[]
cv_std=[]
for cv_result in cv_results:
cv_means.append(cv_result.mean())
cv_std.append(cv_result.std())
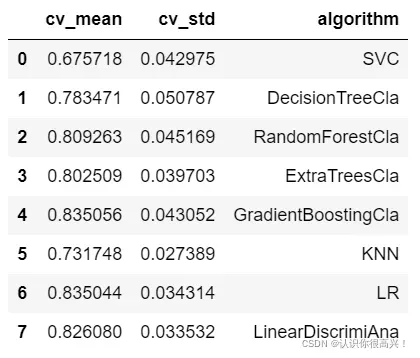
#汇总数据
cvResDf=pd.DataFrame({'cv_mean':cv_means,
'cv_std':cv_std,
'algorithm':['SVC','DecisionTreeCla','RandomForestCla','ExtraTreesCla',
'GradientBoostingCla','KNN','LR','LinearDiscrimiAna']})
cvResDf下面是结果,数字太抽象了,换个图吧。
# 可视化查看不同算法的表现情况
sns.barplot(data=cvResDf,x='cv_mean',y='algorithm',**{'xerr':cv_std})
cvResFacet=sns.FacetGrid(cvResDf.sort_values(by='cv_mean',ascending=False),sharex=False,
sharey=False,aspect=2)
cvResFacet.map(sns.barplot,'cv_mean','algorithm',**{'xerr':cv_std},
palette='muted')
cvResFacet.set(xlim=(0.7,0.9))
cvResFacet.add_legend()首先是0-1作为范围的总体图,但是某些模型的结果差不多,我们可以将坐标轴缩减至0.7-1.0
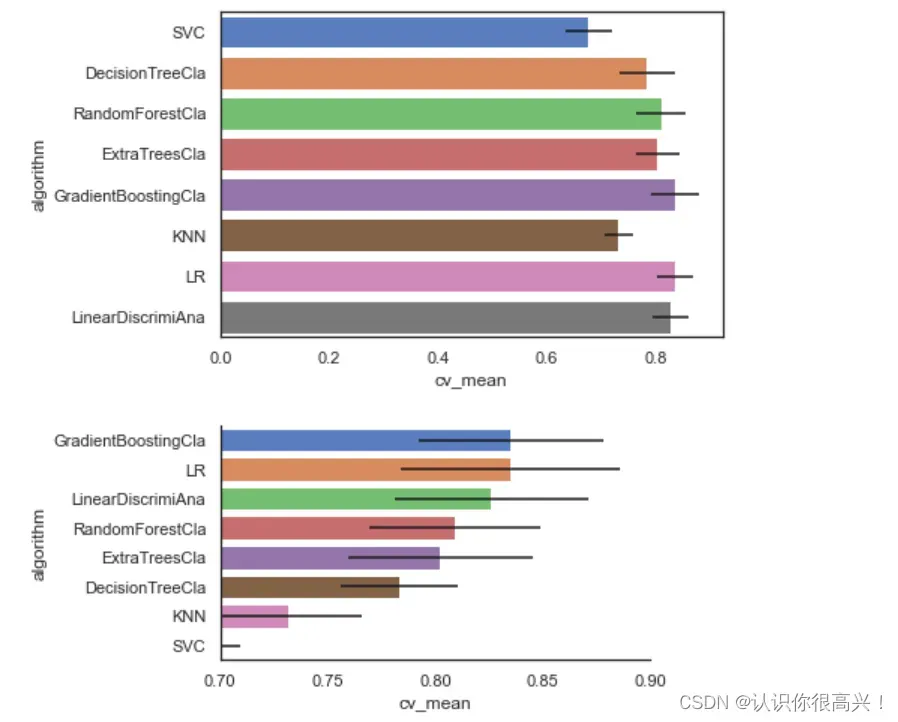
7.2确定选取LR和GradientBoostingCla模型
不问,只问肉眼
八、模型调优
8.1模型对比
综合以上模型表现,考虑选择GradientBoostingCla、LR两种模型进一步对比。分别建立GradientBoostingClassifier以及LogisticRegression模型,并进行模型调优。
#GradientBoostingClassifier模型
GBC = GradientBoostingClassifier()
gb_param_grid = {'loss' : ["deviance"],
'n_estimators' : [100,200,300],
'learning_rate': [0.1, 0.05, 0.01],
'max_depth': [4, 8],
'min_samples_leaf': [100,150],
'max_features': [0.3, 0.1]
}
modelgsGBC = GridSearchCV(GBC,param_grid = gb_param_grid, cv=kfold,
scoring="accuracy", n_jobs= -1, verbose = 1)
modelgsGBC.fit(experData_X,experData_y)
#LogisticRegression模型
modelLR=LogisticRegression()
LR_param_grid = {'C' : [1,2,3],
'penalty':['l1','l2']}
modelgsLR = GridSearchCV(modelLR,param_grid = LR_param_grid, cv=kfold,
scoring="accuracy", n_jobs= -1, verbose = 1)
modelgsLR.fit(experData_X,experData_y)
8.2 查看模型准确度
#modelgsGBC模型
print('modelgsGBC模型得分为:%.3f'%modelgsGBC.best_score_)
#modelgsLR模型
print('modelgsLR模型得分为:%.3f'%modelgsLR.best_score_)
# GBC模型得分(即模型准确性)更高,继续比较其他指标的差异。
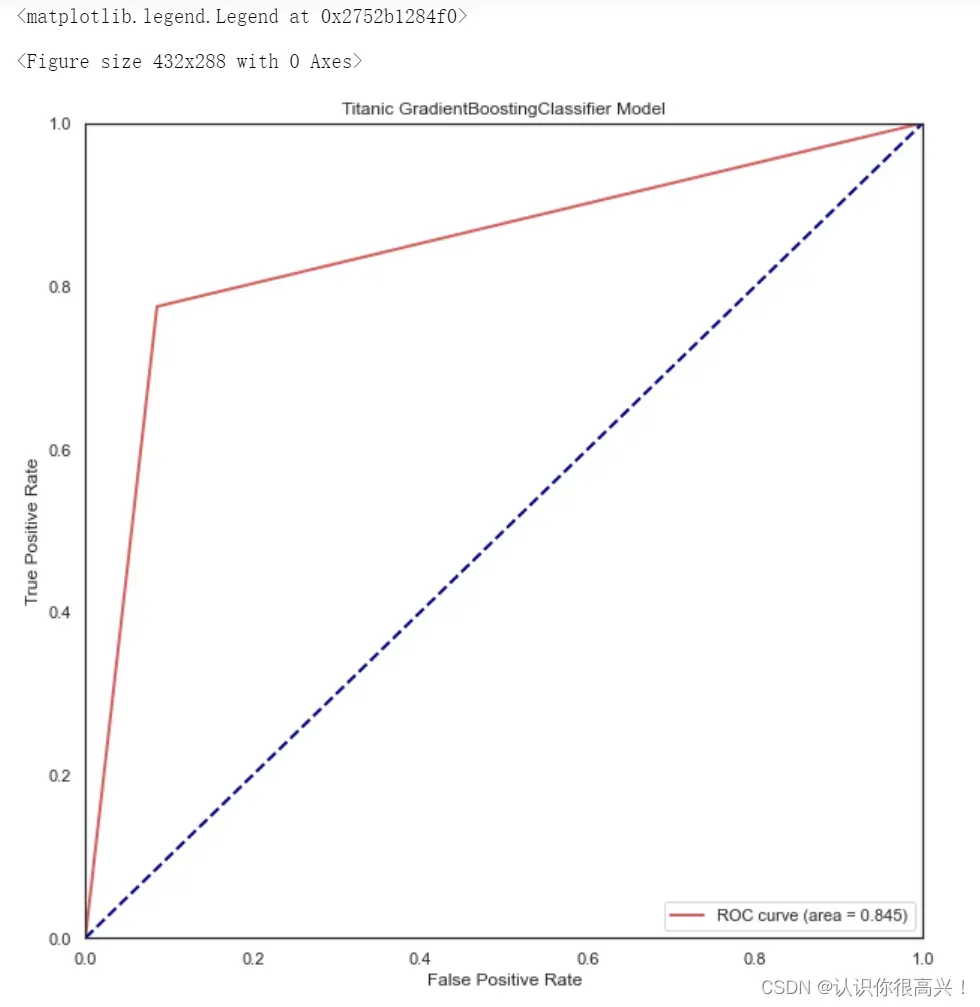
8.3 查看模型ROC曲线
#求出测试数据模型的预测值
modelgsGBCtestpre_y=modelgsGBC.predict(experData_X).astype(int)
#画图
fpr,tpr,threshold = roc_curve(experData_y, modelgsGBCtestpre_y) ###计算真正率和假正率
roc_auc = auc(fpr,tpr) ###计算auc的值
plt.figure()
lw = 2
plt.figure(figsize=(10,10))
plt.plot(fpr, tpr, color='r',
lw=lw, label='ROC curve (area = %0.3f)' % roc_auc) ###假正率为横坐标,真正率为纵坐标做曲线
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Titanic GradientBoostingClassifier Model')
plt.legend(loc="lower right")也就是说,我总觉得镜框是平的(右上角是下..),因为两个模型的精度差不多,所以这个曲线的观感基本一致。至于评价指标的具体内容,请参考其他博文,这里不再赘述。
#求出测试数据模型的预测值
testpre_y=modelgsLR.predict(experData_X).astype(int)
#画图
fpr,tpr,threshold = roc_curve(experData_y, testpre_y) ###计算真正率和假正率
roc_auc = auc(fpr,tpr) ###计算auc的值
plt.figure()
lw = 2
plt.figure(figsize=(10,10))
plt.plot(fpr, tpr, color='r',
lw=lw, label='ROC curve (area = %0.3f)' % roc_auc) ###假正率为横坐标,真正率为纵坐标做曲线
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Titanic LogisticRegression Model')
plt.legend(loc="lower right")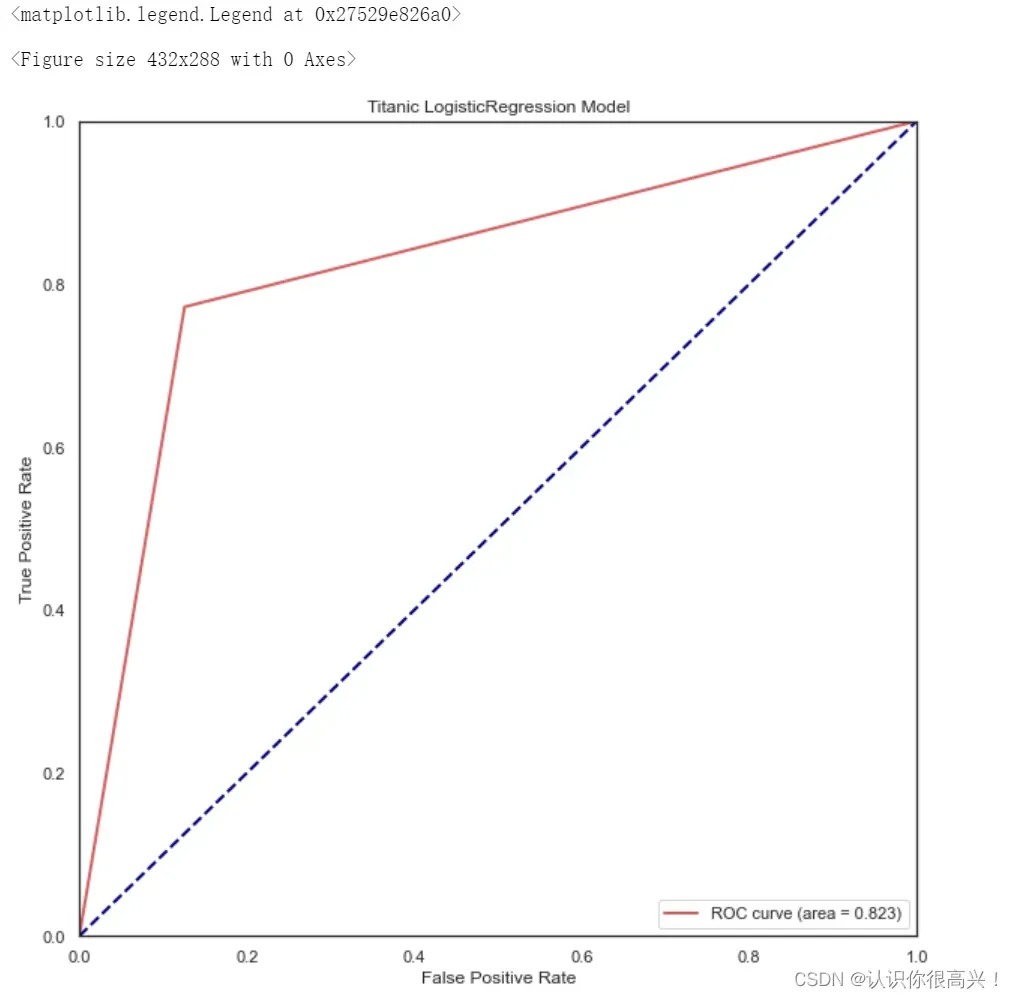
8.4 查看混淆矩阵
from sklearn.metrics import confusion_matrix
print('GradientBoostingClassifier模型混淆矩阵为\n',confusion_matrix(experData_y.astype(int).astype(str),modelgsGBCtestpre_y.astype(str)))
print('LinearRegression模型混淆矩阵为\n',confusion_matrix(experData_y.astype(int).astype(str),testpre_y.astype(str)))这里涉及召回率等其他评价指标,萌新可以简单理解为,主对角线上的数字越大越好。那从这里可以看出,这个小G模型效果应该比较好。

9.模型预测
#TitanicGBSmodle
GBCpreData_y=modelgsGBC.predict(preData_X)
GBCpreData_y=GBCpreData_y.astype(int)
#导出预测结果
GBCpreResultDf=pd.DataFrame()
GBCpreResultDf['PassengerId']=full['PassengerId'][full['Survived'].isnull()]
GBCpreResultDf['Survived']=GBCpreData_y
GBCpreResultDf
#将预测结果导出为csv文件
GBCpreResultDf.to_csv(r'C:\Users\demo\Titanic\TitanicGBSmodle.csv',index=False)这里注意更改一下保存路径,接下来我们可以在kaggle官网进行提交啦。
还是建议萌新点击这里的上传按钮,而不是选择代码提交的方式。不过这里注意走个梯子,一般科学上网都能顺利投稿。
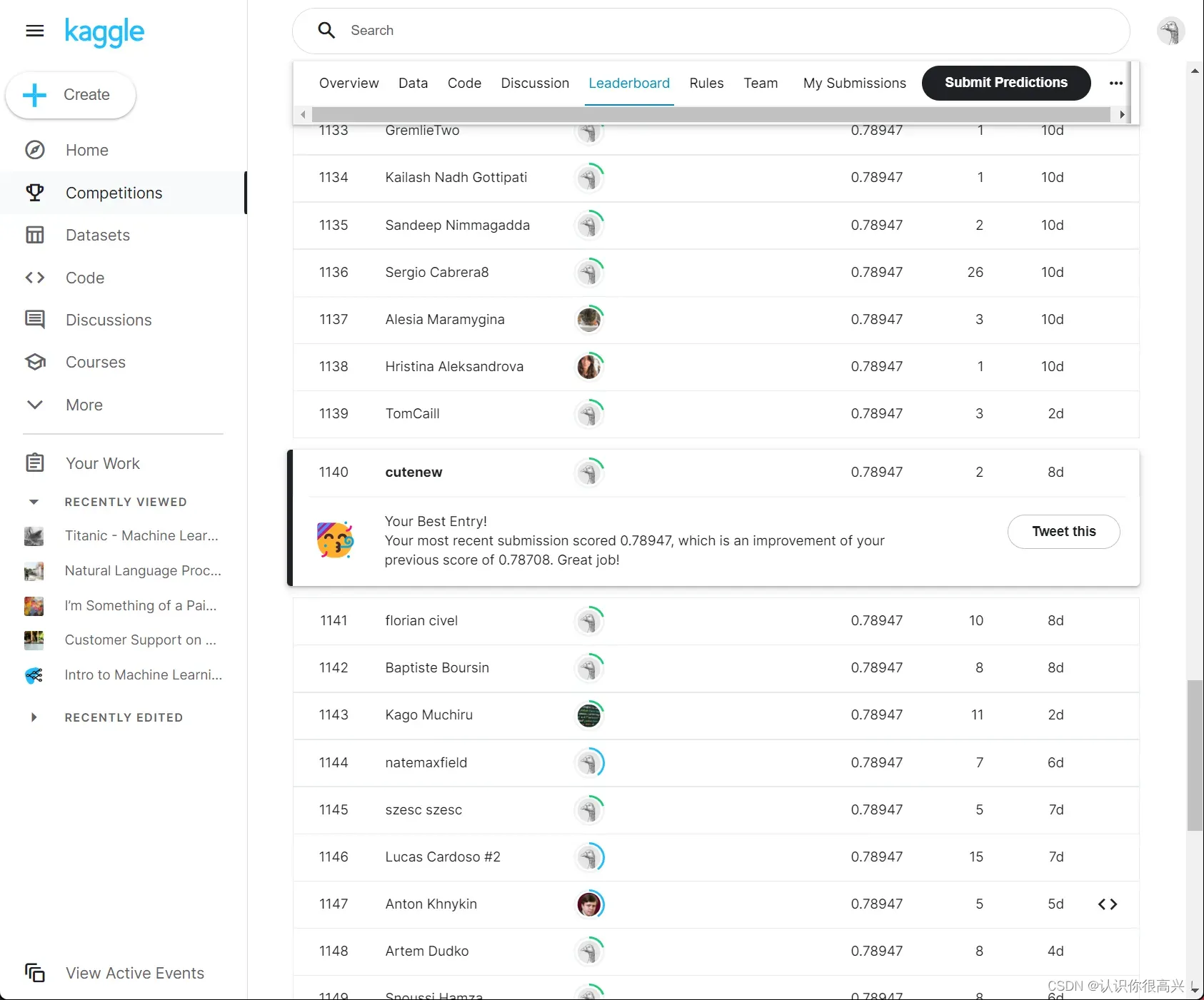
上面就是提交结果啦,可以看到小G结果比LR结果高出了一丢丢。
代码链接:https://pan.baidu.com/s/14F87WTGJFDHlpCF91xlt5Q
提取码:f6x5
文章出处登录后可见!