接上一篇文章
AdaBoost-SAMME 算法推导
同算法步骤中的前提条件一样,假设训练集 T = { X_i, y_i },i = 1,…,N,y 的取值有 M 种可能,h(x) 为估计器,估计器的数量为 K。
为了适应多分类问题,AdaBoost-SAMME 算法将原本为数值的标签 y 转化成一个向量的形式,如式 4-9 所示:
下面用一个例子来说明式 4-9 的含义,假设标签 y 可取 1,2,3,标签集 y = { 2,1,2,3 },这时根据式 4-9 可以得到对应的转换后的标签集如式 4-10 所示:
同样将算法解释为加法模型,通过多个估计器 h(x) 加权以后得到最后的强估计器 H(x),代价函数使用指数函数
(1)代价函数,这里比原始算法多了一个 1 / M,是为了后面计算方便,同时 H(X_i) 也是一个向量
(2)带入式 4-1 中的(3)式
(3)同样定义一个 ω,包含前一轮的强估计器等与 α 无关的值
(4)带入 ω 得到代价函数的表达式
(5)目标为找到最优的估计器权重 α 使得代价函数的取值最小
我们先来看代价函数的指数部分,即预测值与标签值的点积。讨论以下两种情况:
当预测值与标签值相同的时候,向量中 1 的位置一致,-1 / (M – 1) 一共有 M – 1 个,得到如下的点积结果:
当预测值与标签值不相同的时候,向量中 1 的位置不一致,-1 / (M – 1) 一共有 M – 2 个,得到如下的点积结果:
结合以上两种情况,得到如下结果:
(1)代价函数 Cost(α)
(2)分两种情况带入式 4-14
(3)增加第二、三两项,不影响最后的结果
(4)将(3)式中前两项和后两项分别合并得到
(1)对代价函数求导数并令其为零
(2)定义错误率 e_k 的表达式
(3)将错误率 e_k 带入(2)式
(4)两边同时乘以 exp(α / (M – 1))
(5)移项后整理得
(6)求得最后的估计器权重 α 的表达式
式 4-16 中估计器权重 α 的表达式前面的常数在进过归一化后对结果没有影响,后面的样本权重更新的公式一样也是简化后的结果。更多详细的算法说明请参考原始论文——Multi-class AdaBoost7
AdaBoost-SAMME.R 算法推导
AdaBoost-SAMME.R 算法是 AdaBoost-SAMME 算法的变体,该算法是使用加权概率估计来更新加法模型,如式 4-17 所示:
代价函数使用的依然是指数函数,不同的是已经没有了估计器权重或者说每一个估计器的权重都为 1,且改成了期望的形式,其中 h(x) 返回的是 M 维的向量,同时为保证求出的 h(x) 唯一,加上了向量的各个元素之和为 0 的限制条件。
成本函数可以拆分为每个类的单独期望,然后相加:
先来看看当 y = 1 时,y * h(x) 的结果:
(1)当 y = 1 时,转换后 y 的向量形式
(2)计算点积的结果
(3)合并最后的项
(4)根据限制条件替换
(5)得到化简后的结果
(1)带入式 4-20
(2)提出与期望无关的项
(3)另后面的期望为 P(y = 1 | x)
(4)同理可以得每一类的期望结果
将上述结果代入代价函数得到:
这时可以使用拉格朗日乘数法来求解上述问题,其拉格朗日函数 L 如下:
拉格朗日函数分别对 h(x) 的各个分量求导数:
两两联立式 4-24 ,分别求出各个分量的结果,下面以第一个为例:
(1)联立导数中的第 1,2 式子
(2)消掉相同的常数项再两边同时取对数
(3)移项化简后得
(1)~(3)同理可得
(4)将(1)~(3)式累加起来根据限制条件化简
(5)将最后一项补充完整
(6)得到第一个分量的结果
同理可得 h(x) 各个分量的结果
样本权重的更新如下,将 h(x) 带入更新方法中,可以看到更新方法只保留了前面一项,因为后面一项为每一类的 p(x) 求和,可以认为是一个常数,归一化以后不影响最后的结果。
这样就得到了算法步骤中的样本权重的更新公式,更多详细的算法说明也请参考原始论文——Multi-class AdaBoost7
五、代码实现
使用 Python 实现 AdaBoost 算法
import numpy as np
from sklearn.tree import DecisionTreeClassifier
class adaboostc():
"""
AdaBoost 分类算法
"""
def __init__(self, n_estimators = 100):
# AdaBoost弱学习器数量
self.n_estimators = n_estimators
def fit(self, X, y):
"""
AdaBoost 分类算法拟合
"""
# 初始化样本权重向量
sample_weights = np.ones(X.shape[0]) / X.shape[0]
# 估计器数组
estimators = []
# 估计器权重数组
weights = []
# 遍历估计器
for i in range(self.n_estimators):
# 初始化最大深度为1的决策树估计器
estimator = DecisionTreeClassifier(max_depth = 1)
# 按照样本权重拟合训练集
estimator.fit(X, y, sample_weight=sample_weights)
# 预测训练集
y_predict = estimator.predict(X)
# 计算误差率
e = np.sum(sample_weights[y_predict != y])
# 当误差率大于等于0.5时跳出循环
if e >= 0.5:
self.n_estimators = i
break
# 计算估计器权重
weight = 0.5 * np.log((1 - e) / e)
# 计算样本权重
temp_weights = np.multiply(sample_weights, np.exp(- weight * np.multiply(y, y_predict)))
# 归一化样本权重
sample_weights = temp_weights / np.sum(temp_weights)
weights.append(weight)
estimators.append(estimator)
self.weights = weights
self.estimators = estimators
def predict(self, X):
"""
AdaBoost 分类算法预测
"""
y = np.zeros(X.shape[0])
# 遍历估计器
for i in range(self.n_estimators):
estimator = self.estimators[i]
weight = self.weights[i]
# 预测结果
predicts = estimator.predict(X)
# 按照估计器的权重累加
y += weight * predicts
# 根据权重的正负号返回结果
return np.sign(y)
使用 Python 实现 AdaBoost-SAMME 算法
import numpy as np
from sklearn.tree import DecisionTreeClassifier
class adaboostmc():
"""
AdaBoost 多分类SAMME算法
"""
def __init__(self, n_estimators = 100):
# AdaBoost弱学习器数量
self.n_estimators = n_estimators
def fit(self, X, y):
"""
AdaBoost 多分类SAMME算法拟合
"""
# 标签分类
self.classes = np.unique(y)
# 标签分类数
self.n_classes = len(self.classes)
# 初始化样本权重向量
sample_weights = np.ones(X.shape[0]) / X.shape[0]
# 估计器数组
estimators = []
# 估计器权重数组
weights = []
# 遍历估计器
for i in range(self.n_estimators):
# 初始化最大深度为1的决策树估计器
estimator = DecisionTreeClassifier(max_depth = 1)
# 按照样本权重拟合训练集
estimator.fit(X, y, sample_weight=sample_weights)
# 训练集预测结果
y_predict = estimator.predict(X)
incorrect = y_predict != y
# 计算误差率
e = np.sum(sample_weights[incorrect])
# 计算估计器权重
weight = np.log((1 - e) / e) + np.log(self.n_classes - 1)
# 计算样本权重
temp_weights = np.multiply(sample_weights, np.exp(weight * incorrect))
# 归一化样本权重
sample_weights = temp_weights / np.sum(temp_weights)
weights.append(weight)
estimators.append(estimator)
self.weights = weights
self.estimators = estimators
def predict(self, X):
"""
AdaBoost 多分类SAMME算法预测
"""
# 加权结果集合
results = np.zeros((X.shape[0], self.n_classes))
# 遍历估计器
for i in range(self.n_estimators):
estimator = self.estimators[i]
weight = self.weights[i]
# 预测结果
predicts = estimator.predict(X)
# 遍历标签分类
for j in range(self.n_classes):
# 对应标签分类的权重累加
results[predicts == self.classes[j], j] += weight
# 取加权最大对应的分类作为最后的结果
return self.classes.take(np.argmax(results, axis=1), axis=0)
使用 Python 实现 AdaBoost-SAMME.R 算法
import numpy as np
from sklearn.tree import DecisionTreeClassifier
class adaboostmcr():
"""
AdaBoost 多分类SAMME.R算法
"""
def __init__(self, n_estimators = 100):
# AdaBoost弱学习器数量
self.n_estimators = n_estimators
def fit(self, X, y):
"""
AdaBoost 多分类SAMME.R算法拟合
"""
# 标签分类
self.classes = np.unique(y)
# 标签分类数
self.n_classes = len(self.classes)
# 初始化样本权重
sample_weights = np.ones(X.shape[0]) / X.shape[0]
# 估计器数组
estimators = []
# 论文中对 y 的定义
y_codes = np.array([-1. / (self.n_classes - 1), 1.])
# 将训练集中的标签值转换成论文中的矩阵形式
y_coding = y_codes.take(self.classes == y[:, np.newaxis])
# 遍历估计器
for i in range(self.n_estimators):
# 初始化最大深度为1的决策树估计器
estimator = DecisionTreeClassifier(max_depth = 1)
# 根据样本权重拟合训练集
estimator.fit(X, y, sample_weight=sample_weights)
# 预测训练集标签值的概率
y_predict_proba = estimator.predict_proba(X)
# 处理概率为0的结果,避免取对数是结果为负无穷大的问题
np.clip(y_predict_proba, np.finfo(y_predict_proba.dtype).eps, None, out=y_predict_proba)
# 计算样本权重
temp_weights = sample_weights * np.exp(- ((self.n_classes - 1) / self.n_classes) * np.sum(np.multiply(y_coding, np.log(y_predict_proba)), axis=1))
# 归一化样本权重
sample_weights = temp_weights / np.sum(temp_weights)
estimators.append(estimator)
self.estimators = estimators
def predict(self, X):
"""
AdaBoost 多分类SAMME.R算法预测
"""
# 结果集合
results = np.zeros((X.shape[0], self.n_classes))
# 遍历估计器
for i in range(self.n_estimators):
estimator = self.estimators[i]
# 预测标签值的概率
y_predict_proba = estimator.predict_proba(X)
# 同样需要处理零概率的问题
np.clip(y_predict_proba, np.finfo(y_predict_proba.dtype).eps, None, out=y_predict_proba)
# 对概率取对数
y_predict_proba_log = np.log(y_predict_proba)
# 计算 h(x)
h = (self.n_classes - 1) * (y_predict_proba_log - (1 / self.n_classes) * np.sum(y_predict_proba_log, axis=1)[:, np.newaxis])
# 累加
results += h
# 取累加最大对应的分类作为最后的结果
return self.classes.take(np.argmax(results, axis=1), axis=0)
使用 Python 实现 AdaBoost.R2 算法
import numpy as np
from sklearn.tree import DecisionTreeRegressor
class adaboostr():
"""
AdaBoost 回归算法
"""
def __init__(self, n_estimators = 100):
# AdaBoost弱学习器数量
self.n_estimators = n_estimators
def fit(self, X, y):
"""
AdaBoost 回归算法拟合
"""
# 初始化样本权重向量
sample_weights = np.ones(X.shape[0]) / X.shape[0]
# 估计器数组
estimators = []
# 估计器权重数组
weights = []
# 遍历估计器
for i in range(self.n_estimators):
# 初始化最大深度为3的决策树估计器
estimator = DecisionTreeRegressor(max_depth = 3)
# 根据样本权重拟合训练集
estimator.fit(X, y, sample_weight=sample_weights)
# 预测结果
y_predict = estimator.predict(X)
# 计算误差向量(线性误差)
errors = np.abs(y_predict - y)
errors = errors / np.max(errors)
# 计算误差率
e = np.sum(np.multiply(errors, sample_weights))
# 当误差率大于等于0.5时跳出循环
if e >= 0.5:
self.n_estimators = i
break
# 计算估计器权重
weight = e / (1 - e)
# 计算样本权重
temp_weights = np.multiply(sample_weights, np.power(weight, 1 - errors))
# 归一化样本权重
sample_weights = temp_weights / np.sum(temp_weights)
weights.append(weight)
estimators.append(estimator)
self.weights = np.array(weights)
self.estimators = np.array(estimators)
def predict(self, X):
"""
AdaBoost 回归算法预测
"""
# 论文中权重的定义
weights = np.log(1 / self.weights)
# 预测结果矩阵
predictions = np.array([self.estimators[i].predict(X) for i in range(self.n_estimators)]).T
# 根据预测结果排序后的下标
sorted_idx = np.argsort(predictions, axis=1)
# 根据排序结果依次累加估计器权重,得到新的累积权重矩阵,类似累积分布函数的定义
weight_cdf = np.cumsum(weights[sorted_idx], axis=1, dtype=np.float64)
# 累积权重矩阵中大于其中中位数的结果
median_or_above = weight_cdf >= 0.5 * weight_cdf[:, -1][:, np.newaxis]
# 中位数结果对应的下标
median_idx = median_or_above.argmax(axis=1)
# 对应的估计器
median_estimators = sorted_idx[np.arange(X.shape[0]), median_idx]
# 取对应的估计器的预测结果作为最后的结果
return predictions[np.arange(X.shape[0]), median_estimators]
6.第三方库实现
scikit-learn3实现自适应增强分类
from sklearn.ensemble import AdaBoostClassifier
# 自适应增强分类器 SAMME 算法
clf = AdaBoostClassifier(n_estimators = 50, random_state = 0, algorithm = "SAMME")
# 自适应增强分类器 SAMME.R 算法
clf = AdaBoostClassifier(n_estimators = 50, random_state = 0, algorithm = "SAMME.R")
# 拟合数据集
clf = clf.fit(X, y)
scikit-learn4实现自适应增强回归
from sklearn.ensemble import AdaBoostRegressor
# 自适应增强回归器
clf = AdaBoostRegressor(n_estimators = 50, random_state = 0)
# 拟合数据集
clf = clf.fit(X, y)
七、实例演示
图 7-1 展示了使用自适应增强算法进行二分类的结果,红色表示标签值为 -1 的样本点,蓝色代表标签值为 1 的样本点。浅红色的区域为预测值为 -1 的部分,浅蓝色的区域则为预测值为 1 的部分
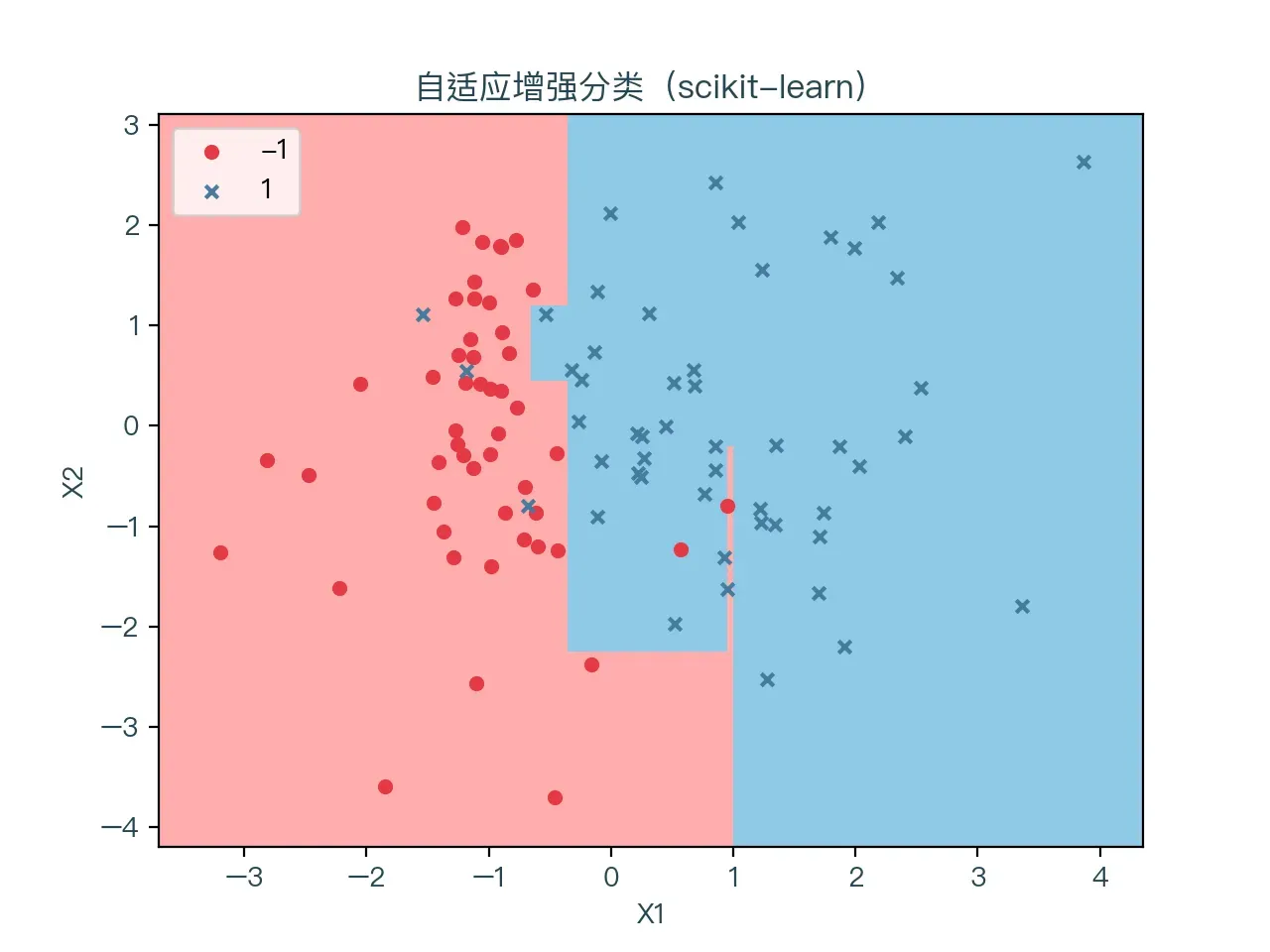
图 7-2 、图 7-3 分别展示了使用 SAMME 和 SAMME.R 算法进行多分类的结果,红色表示标签值为 0 的样本点,蓝色代表标签值为 1 的样本点,绿色代表标签值为 2 的样本点。浅红色的区域为预测值为 0 的部分,浅蓝色的区域则为预测值为 1 的部分,浅绿色的区域则为预测值为 1 的部分
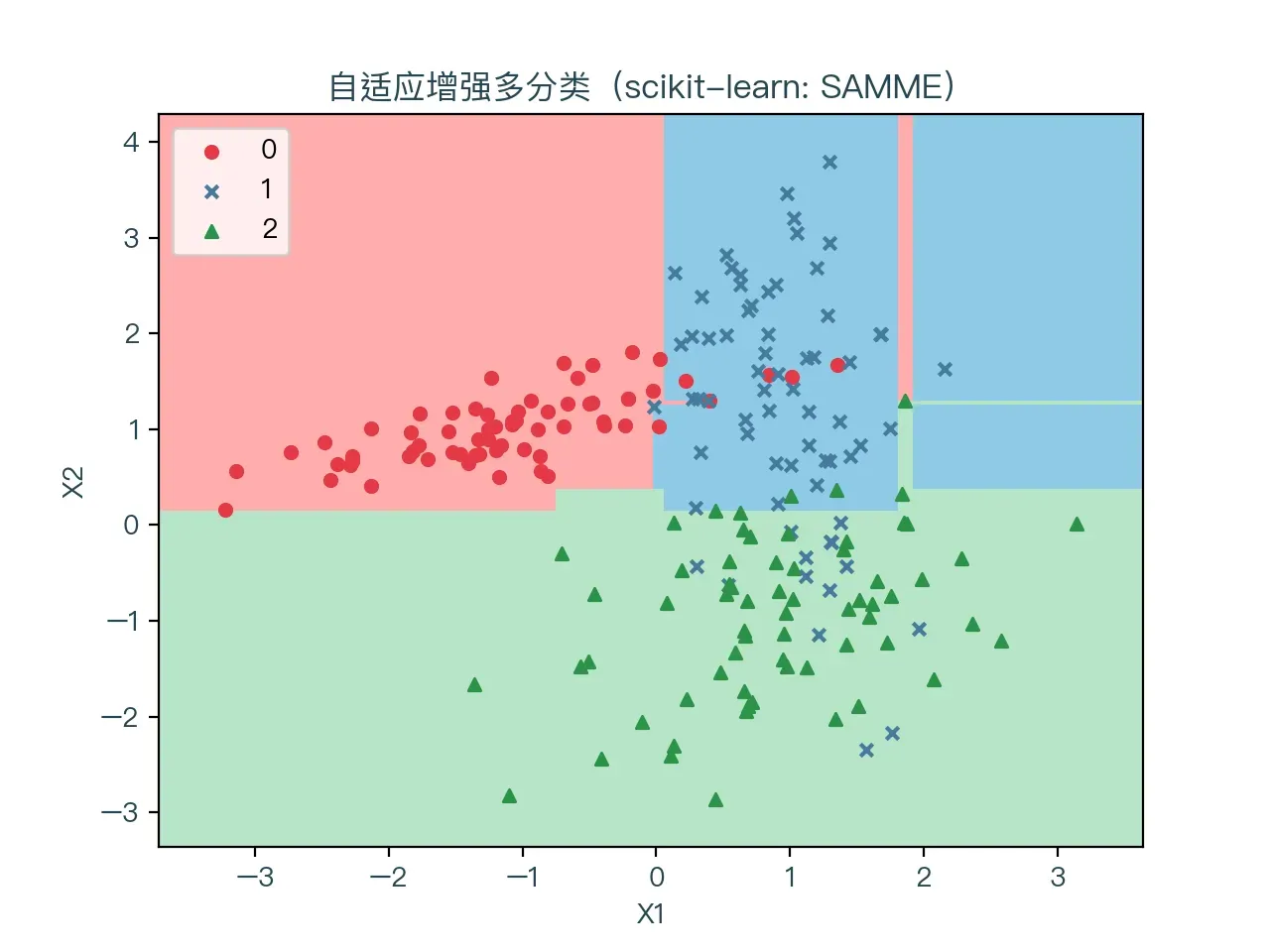
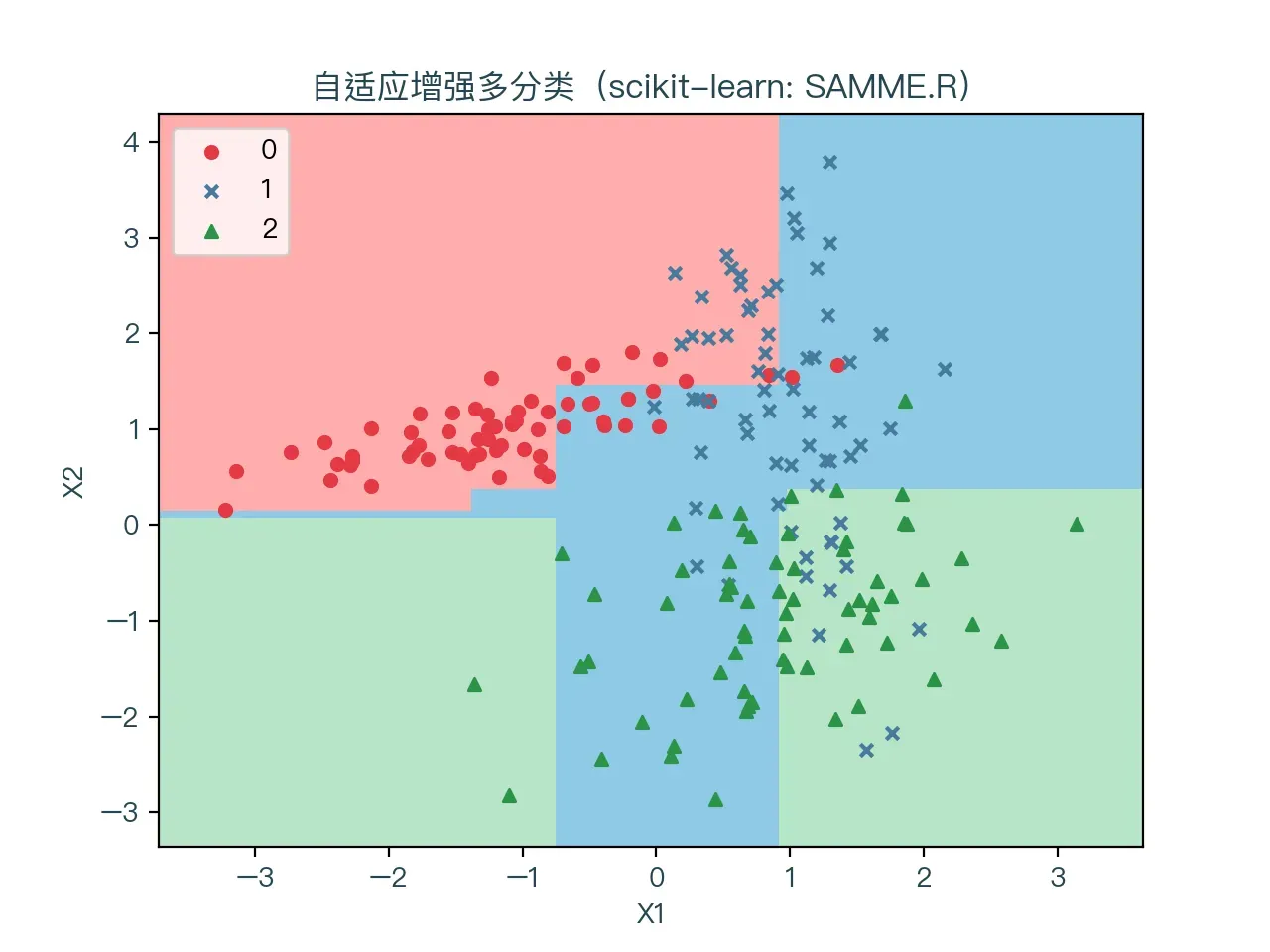
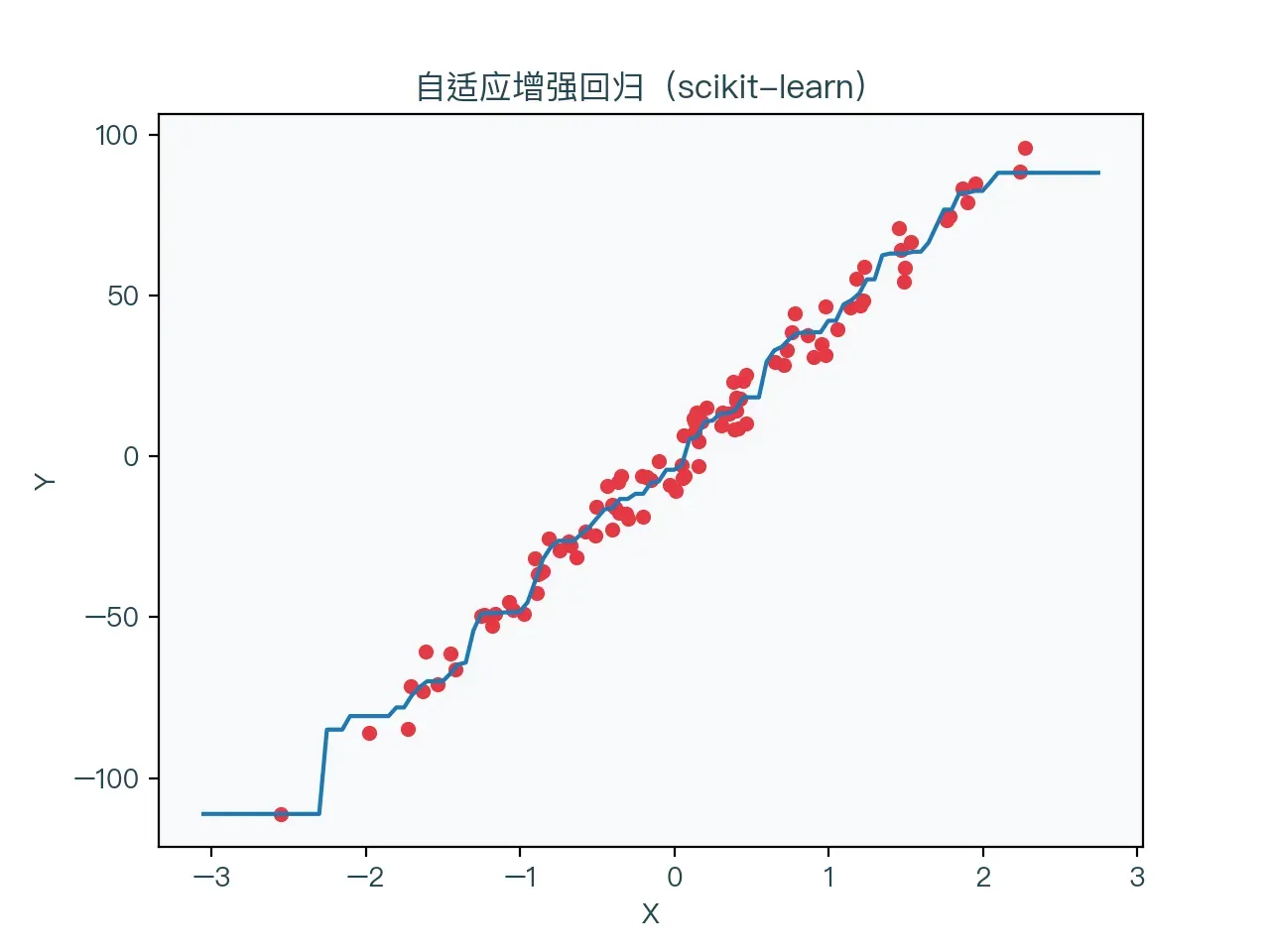
图 7-4 展示了使用自适应增强算法进行回归的结果
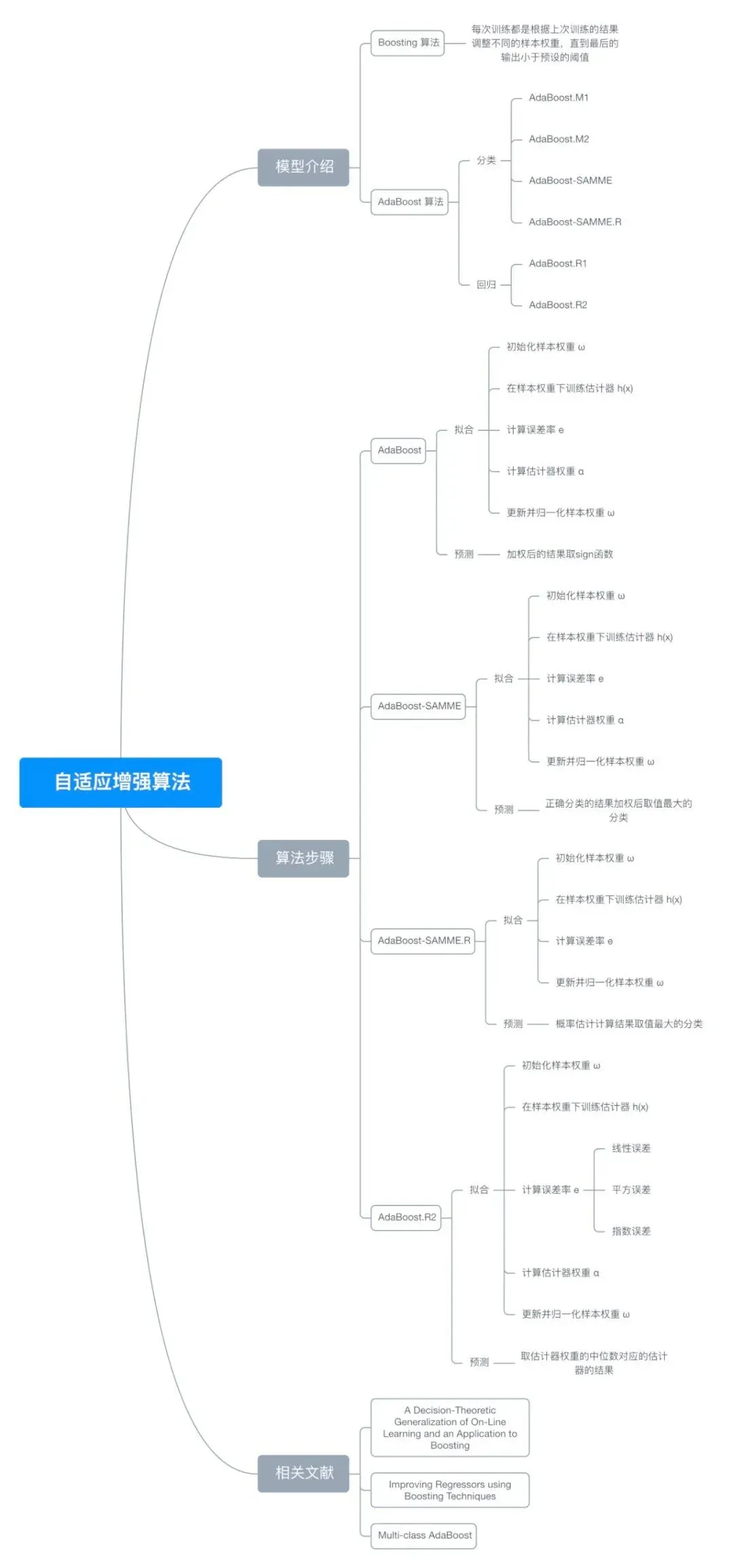
八、思维导图
9. 参考文献
- https://en.wikipedia.org/wiki/Boosting_(machine_learning)
- https://en.wikipedia.org/wiki/AdaBoost
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.AdaBoostClassifier.html
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.AdaBoostRegressor.html
- https://www.face-rec.org/algorithms/Boosting-Ensemble/decision-theoretic_generalization.pdf
- https://citeseer.ist.psu.edu/viewdoc/download?doi=10.1.1.21.5683&rep=rep1&type=pdf
- https://hastie.su.domains/Papers/samme.pdf
如需完整演示,请单击此处
注:本文力求准确、通俗易懂,但由于作者也是初学者,水平有限,文中如有错误或遗漏,恳请读者批评指正,留言指正
本文首发于——AI导图,欢迎关注
文章出处登录后可见!