贝叶斯的概念
贝叶斯方法是以贝叶斯原理为基础,使用概率统计的知识对样本数据集进行分类。由于其有着坚实的数学基础,贝叶斯分类算法的误判率是很低的。贝叶斯方法的特点是结合先验概率和后验概率,即避免了只使用先验概率的主观偏见,也避免了单独使用样本信息的过拟合现象。贝叶斯分类算法在数据集较大的情况下表现出较高的准确率,同时算法本身也比较简单。([1]朱军,胡文波.贝叶斯机器学习前沿进展综述[J].计算机研究与发展,2015,52(01):16-26.)
2.朴素贝叶斯
朴素贝叶斯方法是在贝叶斯算法的基础上进行了相应的简化,即假定给定目标值时属性之间相互条件独立。也就是说没有哪个属性变量对于决策结果来说占有着较大的比重,也没有哪个属性变量对于决策结果占有着较小的比重。虽然这个简化方式在一定程度上降低了贝叶斯分类算法的分类效果,但是在实际的应用场景中,极大地简化了贝叶斯方法的复杂性。([2]马刚. 朴素贝叶斯算法的改进与应用[D].安徽大学,2018.)
三、分类原则
朴素贝叶斯分类(NBC)是以贝叶斯定理为基础并且假设特征条件之间相互独立的方法,先通过已给定的训练集,以特征词之间独立作为前提假设,学习从输入到输出的联合概率分布,再基于学习到的模型,输入 求出使得后验概率最大的输出 。
设有样本数据集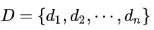 ,对应样本数据的特征属性集为
,对应样本数据的特征属性集为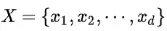 ,类变量为
,类变量为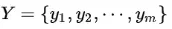 ,即D可以分为ym类别。其中
,即D可以分为ym类别。其中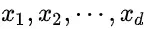 相互独立且随机,则Y的先验概率
相互独立且随机,则Y的先验概率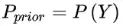 ,Y的后验概率
,Y的后验概率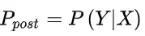 ,由朴素贝叶斯算法可得,后验概率可以由先验概率
,由朴素贝叶斯算法可得,后验概率可以由先验概率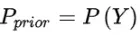 、证据
、证据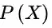 、类条件概率
、类条件概率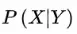 计算出:
计算出:
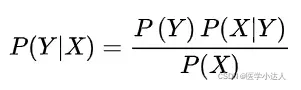
朴素贝叶斯基于各特征之间相互独立,在给定类别为y的情况下,上式可以进一步表示为下式:
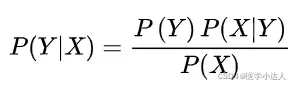
由以上两个方程,后验概率可以计算为:
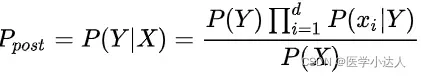
由于P(X)的大小是固定不变的,因此在比较后验概率时,只比较上式的分子部分即可。因此可以得到一个样本数据属于类别的朴素贝叶斯计算:
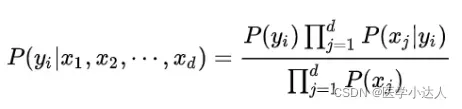
4.通过临床症状和体征预测疾病的发生
疾病+症状/体征的数据样式如图:
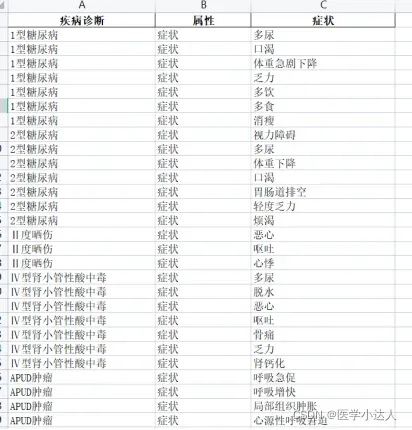
数据维度:疾病数量3481个,即拥有3481个分类标签;临床表现+症状+体征总共14156个特征标签,即疾病的特征维度的长度为14156。
疾病症状和体征预测疾病的缺陷:疾病症状的条件不是相互独立的,例如恶心和呕吐,它们是高度相关的。其次,由于缺乏相应的数据集,疾病症状和体征发展为相应疾病的概率难以衡量。因此,您必须仔细考虑自己的需求和设置。
五、数据处理流程及参考代码
(1)清洗数据:
将疾病症状和体征转换为可训练的数据集:
将疾病标签转换为相应的可训练数据集;
import pandas as pd
df_01 = pd.read_excel('临床体征.xlsx')
df_01.head(2)
def cord2id(list):
dic = {}
list = set(list)
for id,word in enumerate(list):
dic[word] = id
return dic
#把疾病和症状转为id字典
dis2id = cord2id(df_01.entity.to_list())
zhengzhuang2id = cord2id(df_01.value.to_list())
dic_tezheng = {}
for i in df_01.values:
try:
dic_tezheng[dis2id[i[0]]] += [zhengzhuang2id[i[2]]]
except:
dic_tezheng[dis2id[i[0]]] = [zhengzhuang2id[i[2]]]
def xandy(dic):
x = []
y = []
for i in dic.keys():
y.append(i)
x.append(dic[i])
return x,y
#训练集
x_tezheng,y_jibing = xandy(dic_tezheng)(2)转为array格式:
特征向量维度(3481,14156):
import numpy as np
x_arry = np.zeros((3481,14156))
for index_i,i in enumerate(x_tezheng):
for j in i:
x_arry[index_i,j] = 1
#验证
print(y_arry[0,1831])
>>> 1.0
(3)训练数据(我偷懒了,直接调包):
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB().fit(x_arry,y_jibing)(4)验证数据:
text=’细菌感染,活动受限,心肌病,心肌炎,咀嚼困难’
#数据预处理
ceshi = text.split(',')
ceshi2id = [zhengzhuang2id[i] for i in ceshi]
#数据转化array
x_ceshi = np.zeros((14156,))
for i in ceshi2id:
x_ceshi[i] = 1
#数据预测结果
y_yuce = clf.predict([x_ceshi])
for i in dis2id.keys():
if dis2id[i] == y_yuce_id:
print(i)
输出:“多发性肌炎-皮肌炎”
总结!总结!总结! :
怎么说呢,朴素贝叶斯模型根据疾病和症状去预测疾病,数据集是一个大问题!!!,我整理的数据集还是远远不够,所以效果一般,而且数据集的构造和特征制定是需要扩充的,比如我整理的数据是x1+x2+x3+…+xn = yi ,但实际情况是x1→yi,或者x2→yi,或者x1+x3→yi,这也是是数据集扩充的一种方法。
每个人都可以自由发挥!
文章出处登录后可见!