



激活函数简介
在深度学习中,输入值和矩阵的运算是线性的,多个线性函数的组合仍然是一个线性函数。对于一个有多个隐藏层的神经网络,如果每一层都是一个线性函数,那么这些层在做的只是线性计算,最终效果相当于一个隐藏层!这种模型的表达能力非常有限。
事实上,输入数据和输出数据之间的关系在大多数情况下是非线性的。因此,我们通常用非线性函数激活每一层,这大大增加了模型可以表达的内容(模型的表达效率与层数有关)。
这时就需要在每一层的后面加上激活函数,为模型提供非线性,使得模型可以表达的形式更多,同时也可以更改模型的输出值,使模型可以实现回归或者分类的功能。常见的激活函数有sigmoid、tanh、relu和softmax。下面分别对其进行介绍。
常见的激活函数及其优缺点
sigmoid激活函数:
函数公式如下![]()
![]()
功能图如下: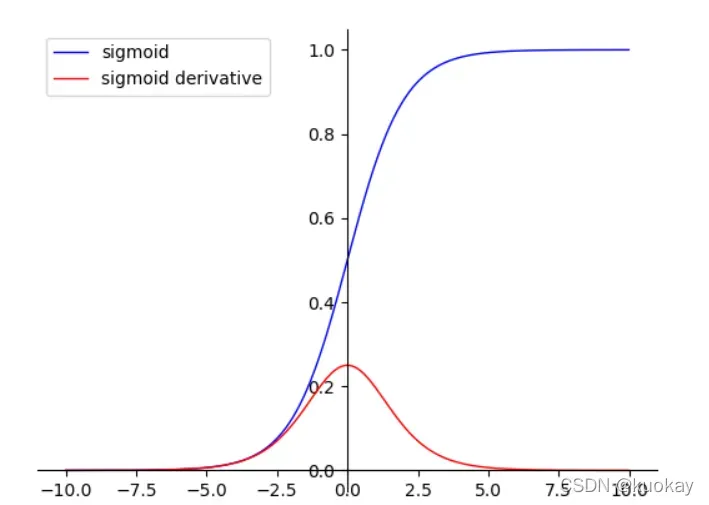
优势:


- Sigmoid的取值范围在(0, 1),而且是单调递增,比较容易优化
- Sigmoid求导比较容易,可以直接推导得出。
缺点:
- Sigmoid函数收敛比较缓慢
- 由于Sigmoid是软饱和,容易产生梯度消失,对于深度网络训练不太适合(从图上sigmoid的导数可以看出当x趋于无穷大的时候,也会使导数趋于0)
- Sigmoid函数并不是以(0,0)为中心点
softmax函数:
公式: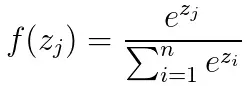
举个例子,通过若干层的计算,在输出层,最后得到的某个训练样本的向量的分数是[ 1, 5, 3 ], 那么概率分别就是:

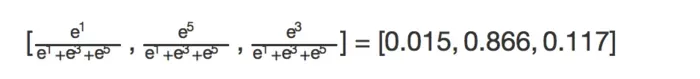
下图说明,softmax函数是怎么计算的

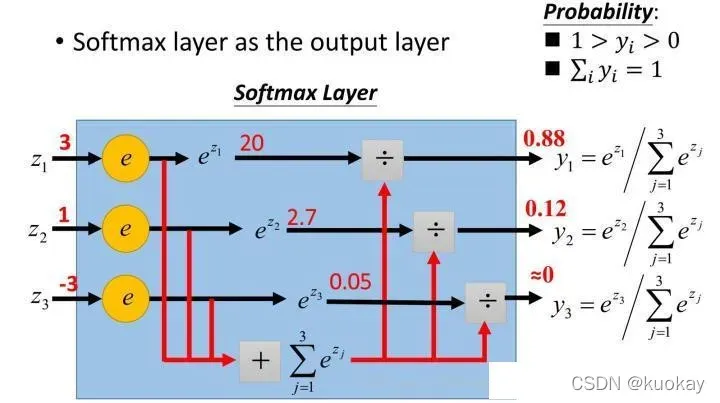

- 除了用于二分类还可以用于多分类,将各个神经元的输出映射到(0,1空间)
tanH函数:
公式:
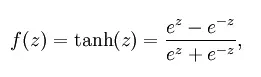
功能图:

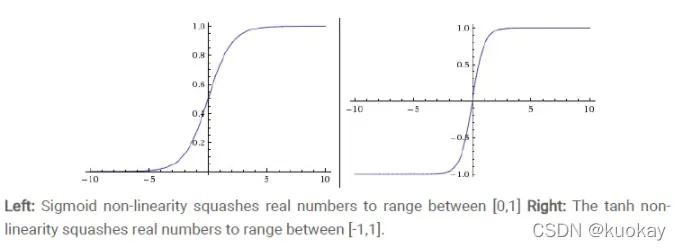
双切正切函数,取值范围为[-1,1],tanh在特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果。与 sigmoid 的区别是,tanh 是 0 均值的,因此实际应用中 tanh 会比 sigmoid 更好。

- 优点:输出以0为中心,收敛速度比sigmoid函数要快
- 缺点:存在梯度消失的问题
relu函数:
ReLu是神经网络中的一个激活函数,其优于tanh和sigmoid函数。
引入relu函数的原因:
- 采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
- 对于深层网络,sigmoid函数反向传播时,很容易就会出现 梯度消失 的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练。
- ReLu会使一部分神经元的输出为0,这样就造成了 网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
功能:
f(x)=max(0,x)
功能图: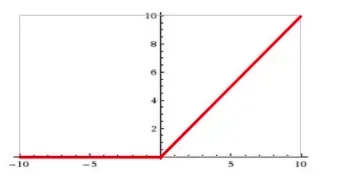

- 优点:目前最受欢迎的激活函数,在x<0时,硬饱和,在x>0时,导数为1,所以在x>0时保持梯度不衰减,从而可以缓解梯度消失的问题,能更快收敛,并提供神经网络的稀疏表达能力
- 缺点:随着训练的进行,一些输入可能会落入硬饱和区域,导致无法更新权重,称为“神经元死亡”
损失函数
损失函数用于评估模型的预测值与实际值的差异程度。损失函数越好,模型的性能就越好。不同模型使用的损失函数一般是不同的。
损失函数分为经验风险损失函数和结构风险损失函数。经验风险损失函数是指预测结果与实际结果之间的差异,结构风险损失函数是指经验风险损失函数加上正则项。
损失函数一般分为二类损失函数、多类损失函数、回归问题损失函数。
二分类损失函数有:0-1损失、hinge损失、LogisticCrossEntropyLoss
多分类损失有:SoftmaxCrossEntropyLoss
回归问题损失函数有:均方差误差或根均方差误差、平均绝对值误差和huber损失函数
0-1损失函数(zero-one loss)
对于二分类问题,Y= {-1,1},我们希望signf(xi,θ)=yi,最自然的损失是0-1损失,即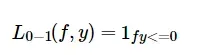
该损失函数能够直观地刻画分类的错误率,但是由于其非凸,非光滑使得算法很难对该函数进行优化,下面将总结0-1损失的二个代理函数:HingeLoss,LogsiticCrossEntropyLoss

HingeLoss
定义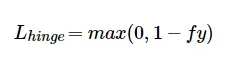

LogisticCrossEntropyLoss
对数似然函数: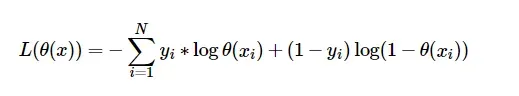

SoftmaxCrossEntropyLoss
损失函数:

均方误差
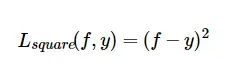
当预测值离真实值越远时,平方损失函数的惩罚越大,因此对异常值越敏感。为了解决这个问题,可以使用平均绝对损失函数

平均绝对误差
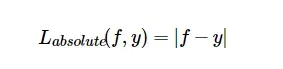
绝对损失函数相当于在做中值回归,相比于做均值回归的平方损失函数对异常点的鲁棒性更好一些,当时有个问题是在f=y时无法求导,综合考虑可导性和对异常点的鲁棒性,采用Huber损失函数

HuberLoss
Huber Loss 是一个用于回归问题的带参损失函数, 优点是能增强平方误差损失函数(MSE, mean square error)对离群点的鲁棒性
当预测偏差小于δ时,取平方误差
当预测偏差大于 δ 时,使用的线性误差


正则化
正则化(regularization)的技术,它可以改善或者减少过度拟合问题。
欠拟合和过拟合
下图是一个回归问题的例子: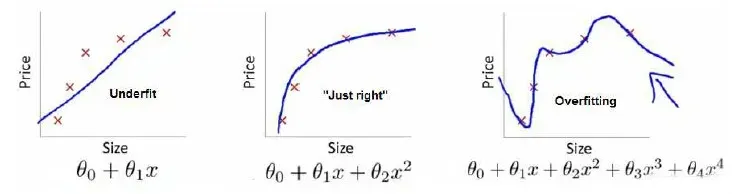
第一个模型是线性模型,欠拟合,与我们的训练集不太吻合;第三种模型是二次模型,过于强调拟合原始数据而失去了算法的精髓:预测新数据。我们可以看到,如果给定一个新值来进行预测,它的表现会很差,它是过拟合的,虽然它非常适合我们的训练集,但在对新输入变量进行预测时可能效果不佳。好的;中间的模型似乎是最合适的。

分类问题中也存在这样的问题: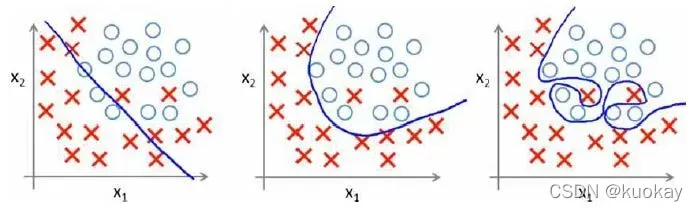
就以多项式理解,x$的次数越高,拟合的越好,但相应的预测的能力就可能变差。

问题是,如果发现过拟合问题,我们该怎么办?
- 丢弃一些不能帮助我们正确预测的特征。可以是手工选择保留哪些特征,或者使用一些模型选择的算法来帮忙(例如PCA)
- 正则化。 保留所有的特征,但是减少参数的大小(magnitude)。
正则化线性回归
对于线性回归的求解,我们之前推导出了两种学习算法:一种基于梯度下降,一种基于正规方程。
正则化线性回归的成本函数为: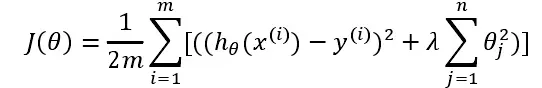
如果我们要使用梯度下降来使这个成本函数最小化,因为我们没有正则化梯度下降算法将有两种情况: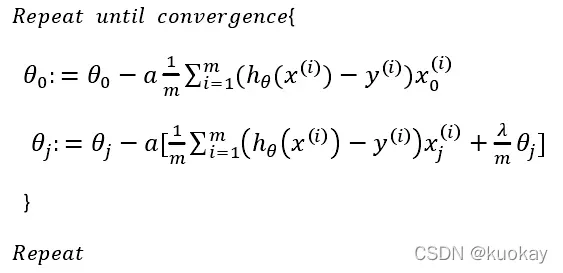
对上面的算法中𝑗 = 1,2, . . . , 𝑛 时的更新式子进行调整可得:


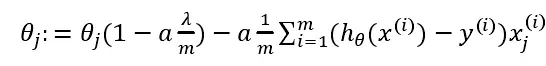
可以看出,正则化线性回归的梯度下降算法的变化是,在原算法的更新规则的基础上,每次𝜃的值减少一个额外的值。

我们也可以使用正规方程来求解正则化线性回归模型,如下所示: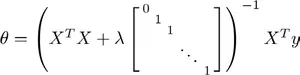
图中的矩阵尺寸为 (n+1)*(n+1)。

正则化逻辑回归模型
对于逻辑回归问题,我们在之前的课程中学习了两种优化算法:我们首先学会了使用梯度下降来优化成本函数𝐽(𝜃),然后学习了更高级的优化算法,需要你设计成本函数𝐽(𝜃)你自己。
自己计算导数 同样对于逻辑回归,我们也在代价函数中加入正则化表达式,得到代价函数:

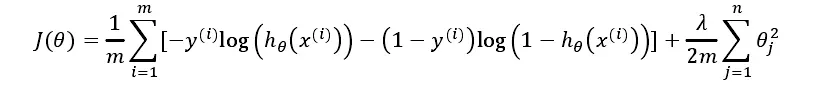
python代码:

import numpy as np
def costReg(theta, X, y, learningRate):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
first = np.multiply(-y, np.log(sigmoid(X*theta.T)))
second = np.multiply((1 - y), np.log(1 - sigmoid(X*theta.T)))
reg = (learningRate / (2 * len(X))* np.sum(np.power(theta[:,1:the
ta.shape[1]],2))
return np.sum(first - second) / (len(X)) + reg
为了最小化这个成本函数,通过推导,梯度下降算法得到:
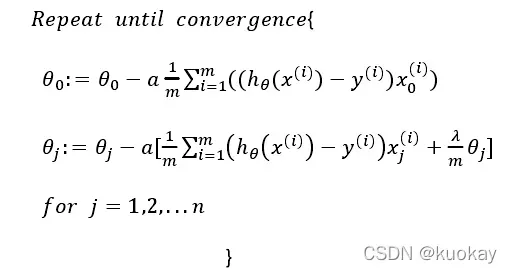
注:看上去同线性回归一样,但是知道 hθ(x)=g(θTX),所以与线性回归不同。

Octave 中,我们依旧可以用 fminuc 函数来求解代价函数最小化的参数,值得注意的是参数θ0的更新规则与其他情况不同。 注意:
- 虽然正则化的逻辑回归中的梯度下降和正则化的线性回归中的表达式看起来一样,但由于两者的hθ(x)不同所以还是有很大差别。
- θ0不参与其中的任何一个正则化。
文章出处登录后可见!