1、sklearn中svm模型的保存与加载调用
(1)使用pickle
# 模型保存
import pickle
model.fit(train_X, train_y)
s=pickle.dumps(model)
f=open('svm.model', "wb+")
f.write(s)
f.close()
# 模型加载
f2=open('svm.model','rb')
s2=f2.read()
model=pickle.loads(s2)
predicted = model.predict(test_X)(2)使用joblib
# 模型读取
from sklearn.externals import joblib
model.fit(train_X, train_y)
joblib.dump(model, "train1_model.m")
# 模型调用
model1 = joblib.load("train1_model.m")
expected = test_y
predicted = model1.predict(test_X)2、panda中删除一列的方法
(1) del df[‘columns’] #改变原始数据
(2) df.drop(‘columns’,axis=1)#删除不改表原始数据,可以通过重新赋值的方式赋值该数据
(3) df.drop(‘columns’,axis=1,inplace=’True’) #改变原始数据
3、cannot import name joblib from sklearn.externals
解决方法一: 直接使用import joblib
解决方案2:回滚版本
删除当前版本的scikit-learnpip uninstall scikit-learn
安装旧版本的scikit-learnpip install scikit-learn==0.20.3
4、sklearn中KFold与StratifiedKFold
(1)StratifiedKFold函数采用分层划分的方法(分层随机抽样思想),验证集中不同类别占比与原始样本的比例保持一致,故StratifiedKFold在做划分的时候需要传入标签特征。
(2)两个函数的参数是一致的
n_splits:默认为3,表示将数据划分为多少份,即k折交叉验证中的k;
shuffle:默认为False,表示是否需要打乱顺序,这个参数在很多的函数中都会涉及,如果设置为True,则会先打乱顺序再做划分,如果为False,会直接按照顺序做划分;
random_state:默认为None,表示随机数的种子,只有当shuffle设置为True的时候才会生效。
5、pandas删除满足条件的行
df_clear = df.drop(df[df['x']<0.01].index)
# 也可以使用多个条件
#删除x小于0.01或大于10的行
df_clear = df.drop(df[(df['x']<0.01) | (df['x']>10)].index) 6、pandas drop函数参数
df.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False,
errors=’raise’)
labels:要删除的列或者行,多个传入列表
axis:轴的方向,0为行,1为列,默认为0
index:指定的一个行或者多个行,
column:指定的一个列或者多个列
level:索引层级,将删除此层级
inplace:布尔值,是否生效
errors:ignore或者raise,默认raise,如果为ignore,则抑制错误并仅删除现有标签
7、使用Sklearn创建测试数据集
Python 的 Sklearn 库提供了一个很棒的示例数据集生成器,它将帮助您创建自己的自定义数据集。它快速且非常易于使用。
(1)make_blob
from sklearn.datasets import make_blobs
from matplotlib import pyplot as plt
from matplotlib import style
style.use("fivethirtyeight")
X, y = make_blobs(n_samples = 100, centers = 3,
cluster_std = 1, n_features = 2)
plt.scatter(X[:, 0], X[:, 1], s = 40, color = 'g')
plt.xlabel("X")
plt.ylabel("Y")
plt.show()
plt.clf()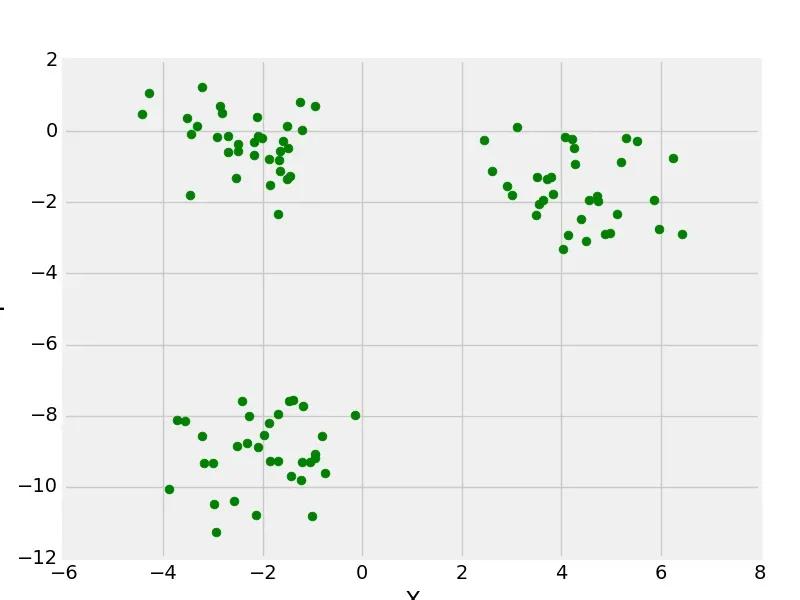
(2)make_moon
from sklearn.datasets import make_moons
from matplotlib import pyplot as plt
from matplotlib import style
X, y = make_moons(n_samples = 1000, noise = 0.1)
plt.scatter(X[:, 0], X[:, 1], s = 40, color ='g')
plt.xlabel("X")
plt.ylabel("Y")
plt.show()
plt.clf()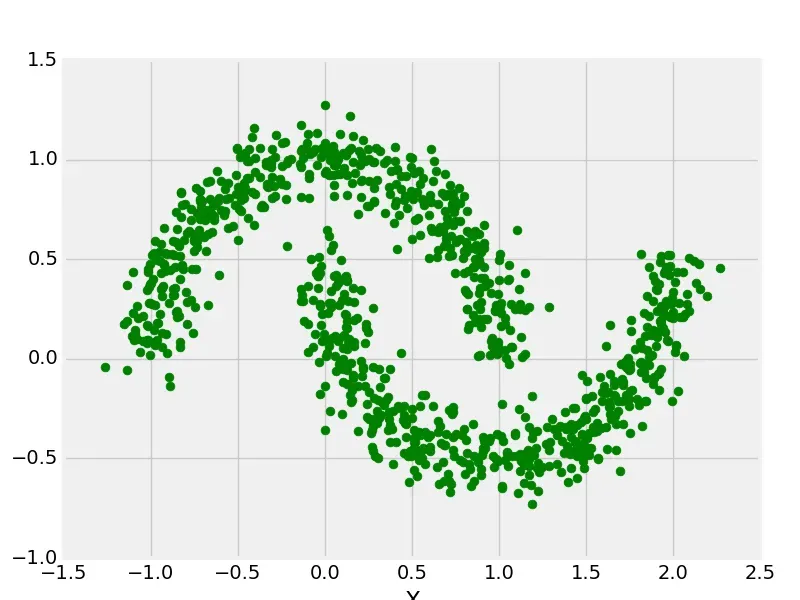
(3)make_circle
from sklearn.datasets import make_circles
from matplotlib import pyplot as plt
from matplotlib import style
style.use("fivethirtyeight")
X, y = make_circles(n_samples = 100, noise = 0.02)
plt.scatter(X[:, 0], X[:, 1], s = 40, color ='g')
plt.xlabel("X")
plt.ylabel("Y")
plt.show()
plt.clf()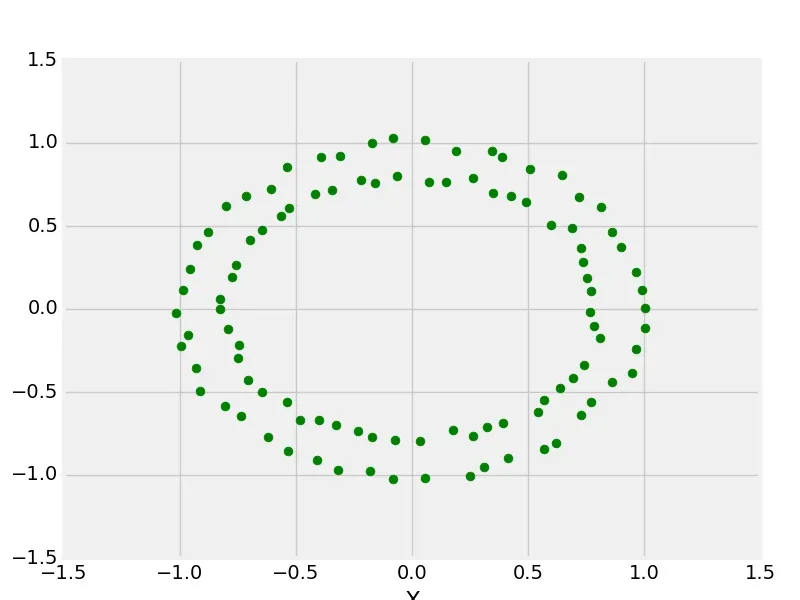
文章出处登录后可见!