相关链接:
【Matting】MODNet:实时人像抠图模型-onnx python部署
【Matting】MODNet:实时人像抠图模型-笔记
上面的2篇博客,分别分析了MODNet的原理以及python部署方法,本文将使用C++部署MODNet模型,实现图片Matting和摄像头Matting功能。先上效果图:

内容
1. 环境
2. 型号
3.代码
四、效果
附录
1. 环境
windows 10×64 cpu
onnxruntime-win-x64-1.10.0
opencv 4.5.5
visual studio 2019
2. 型号
下载官方提供的onnx模型,官方的repo地址:https://github.com/ZHKKKe/MODNet.git,在onnx文件夹下有下载链接,这里就不给出来了。
使用netron查看onnx模型:
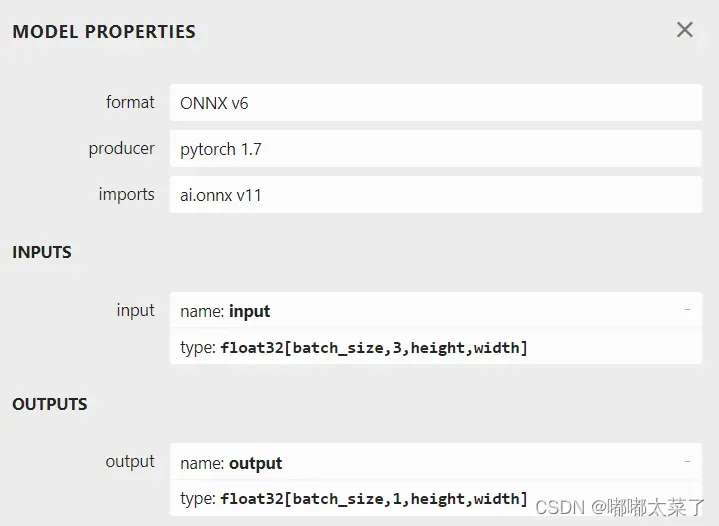
网络结构:

3.代码
实现了2个功能:图片Matting、摄像头Matting(速度与电脑性能有关,cpu会很慢)
代码目录:
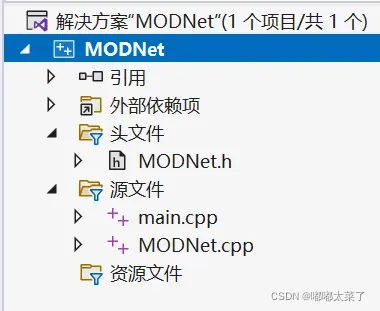
MODNet.h内容:
#pragma once
#include <string>
#include <onnxruntime_cxx_api.h>
#include <iostream>
#include <vector>
#include <opencv2/opencv.hpp>
#include <time.h>
class MODNet
{
protected:
Ort::Env env_;
Ort::SessionOptions session_options_;
Ort::Session session_{ nullptr };
Ort::RunOptions run_options_{ nullptr };
std::vector<Ort::Value> input_tensors_;
std::vector<const char*> input_node_names_;
std::vector<int64_t> input_node_dims_;
size_t input_tensor_size_{ 1 };
std::vector<const char*> out_node_names_;
size_t out_tensor_size_{ 1 };
int image_h;
int image_w;
cv::Mat normalize(cv::Mat& image);
cv::Mat preprocess(cv::Mat image);
public:
MODNet() = delete;
MODNet(std::wstring model_path, int num_threads, std::vector<int64_t> input_node_dims);
cv::Mat predict_image(cv::Mat& src);
void predict_image(const std::string& src_path, const std::string& dst_path);
void predict_camera();
};
MODNet.cpp内容:
#include "MODNet.h"
MODNet::MODNet(std::wstring model_path, int num_threads = 1, std::vector<int64_t> input_node_dims = { 1, 3, 192, 192 }) {
input_node_dims_ = input_node_dims;
for (int64_t i : input_node_dims_) {
input_tensor_size_ *= i;
out_tensor_size_ *= i;
}
//std::cout << input_tensor_size_ << std::endl;
session_options_.SetIntraOpNumThreads(num_threads);
session_options_.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_EXTENDED);
try {
session_ = Ort::Session(env_, model_path.c_str(), session_options_);
}
catch (...) {
}
Ort::AllocatorWithDefaultOptions allocator;
//获取输入name
const char* input_name = session_.GetInputName(0, allocator);
input_node_names_ = { input_name };
//std::cout << "input name:" << input_name << std::endl;
const char* output_name = session_.GetOutputName(0, allocator);
out_node_names_ = { output_name };
//std::cout << "output name:" << output_name << std::endl;
}
cv::Mat MODNet::normalize(cv::Mat& image) {
std::vector<cv::Mat> channels, normalized_image;
cv::split(image, channels);
cv::Mat r, g, b;
b = channels.at(0);
g = channels.at(1);
r = channels.at(2);
b = (b / 255. - 0.5) / 0.5;
g = (g / 255. - 0.5) / 0.5;
r = (r / 255. - 0.5) / 0.5;
normalized_image.push_back(r);
normalized_image.push_back(g);
normalized_image.push_back(b);
cv::Mat out = cv::Mat(image.rows, image.cols, CV_32F);
cv::merge(normalized_image, out);
return out;
}
/*
* preprocess: resize -> normalize
*/
cv::Mat MODNet::preprocess(cv::Mat image) {
image_h = image.rows;
image_w = image.cols;
cv::Mat dst, dst_float, normalized_image;
cv::resize(image, dst, cv::Size(int(input_node_dims_[3]), int(input_node_dims_[2])), 0, 0);
dst.convertTo(dst_float, CV_32F);
normalized_image = normalize(dst_float);
return normalized_image;
}
/*
* postprocess: preprocessed image -> infer -> postprocess
*/
cv::Mat MODNet::predict_image(cv::Mat& src) {
cv::Mat preprocessed_image = preprocess(src);
cv::Mat blob = cv::dnn::blobFromImage(preprocessed_image, 1, cv::Size(int(input_node_dims_[3]), int(input_node_dims_[2])), cv::Scalar(0, 0, 0), false, true);
//std::cout << "load image success." << std::endl;
// create input tensor
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
input_tensors_.emplace_back(Ort::Value::CreateTensor<float>(memory_info, blob.ptr<float>(), blob.total(), input_node_dims_.data(), input_node_dims_.size()));
std::vector<Ort::Value> output_tensors_ = session_.Run(
Ort::RunOptions{ nullptr },
input_node_names_.data(),
input_tensors_.data(),
input_node_names_.size(),
out_node_names_.data(),
out_node_names_.size()
);
float* floatarr = output_tensors_[0].GetTensorMutableData<float>();
// decoder
cv::Mat mask = cv::Mat::zeros(static_cast<int>(input_node_dims_[2]), static_cast<int>(input_node_dims_[3]), CV_8UC1);
for (int i{ 0 }; i < static_cast<int>(input_node_dims_[2]); i++) {
for (int j{ 0 }; j < static_cast<int>(input_node_dims_[3]); ++j) {
mask.at<uchar>(i, j) = static_cast<uchar>(floatarr[i * static_cast<int>(input_node_dims_[3]) + j] > 0.5);
}
}
cv::resize(mask, mask, cv::Size(image_w, image_h), 0, 0);
input_tensors_.clear();
return mask;
}
void MODNet::predict_image(const std::string& src_path, const std::string& dst_path) {
cv::Mat image = cv::imread(src_path);
cv::Mat mask = predict_image(image);
cv::Mat predict_image;
cv::bitwise_and(image, image, predict_image, mask = mask);
cv::imwrite(dst_path, predict_image);
//std::cout << "predict image over" << std::endl;
}
void MODNet::predict_camera() {
cv::Mat frame;
cv::VideoCapture cap;
int deviceID{ 0 };
int apiID{ cv::CAP_ANY };
cap.open(deviceID, apiID);
if (!cap.isOpened()) {
std::cout << "Error, cannot open camera!" << std::endl;
return;
}
//--- GRAB AND WRITE LOOP
std::cout << "Start grabbing" << std::endl << "Press any key to terminate" << std::endl;
int count{ 0 };
clock_t start{ clock() }, end;
double fps{ 0 };
for (;;)
{
// wait for a new frame from camera and store it into 'frame'
cap.read(frame);
// check if we succeeded
if (frame.empty()) {
std::cout << "ERROR! blank frame grabbed" << std::endl;
break;
}
cv::Mat mask = predict_image(frame);
cv::Mat segFrame;
cv::bitwise_and(frame, frame, segFrame, mask = mask);
// fps
end = clock();
++count;
fps = count / (float(end - start) / CLOCKS_PER_SEC);
if (count >= 100) {
count = 0;
start = clock();
}
std::cout << fps << " " << count << " " << end - start << std::endl;
//设置绘制文本的相关参数
std::string text{ std::to_string(fps) };
int font_face = cv::FONT_HERSHEY_COMPLEX;
double font_scale = 1;
int thickness = 2;
int baseline;
cv::Size text_size = cv::getTextSize(text, font_face, font_scale, thickness, &baseline);
//将文本框居中绘制
cv::Point origin;
origin.x = 20;
origin.y = 20;
cv::putText(segFrame, text, origin, font_face, font_scale, cv::Scalar(0, 255, 255), thickness, 8, 0);
// show live and wait for a key with timeout long enough to show images
cv::imshow("Live", segFrame);
if (cv::waitKey(5) >= 0)
break;
}
cap.release();
cv::destroyWindow("Live");
return;
}
main.cpp内容:
#include <vector>
#include <iostream>
#include <opencv2/opencv.hpp>
#include "MODNet.h"
#include <string>
int main()
{
std::wstring model_path(L"modnet.onnx");
std::cout << "infer...." << std::endl;
MODNet modnet(model_path, 1, { 1, 3, 512, 512 });
modnet.predict_image("C:\\Users\\xxx\\Pictures\\test1.jpeg", "C:\\Users\\xxx\\Pictures\\matting.png");
modnet.predict_camera(); //使用摄像头
return 0;
}
四、效果

附录
本文代码及权重链接:modnet onnx C++部署,实现了图像matting,摄像头matting功能
文章出处登录后可见!
已经登录?立即刷新