一、deepFM原理
上次在【推荐算法实战】DeepFM模型(tensorflow版)已经过了一遍模型的大体原理和tensorflow实现,本文侧重FM公式的优化改机和deepFM代码的pytorch版本的实现。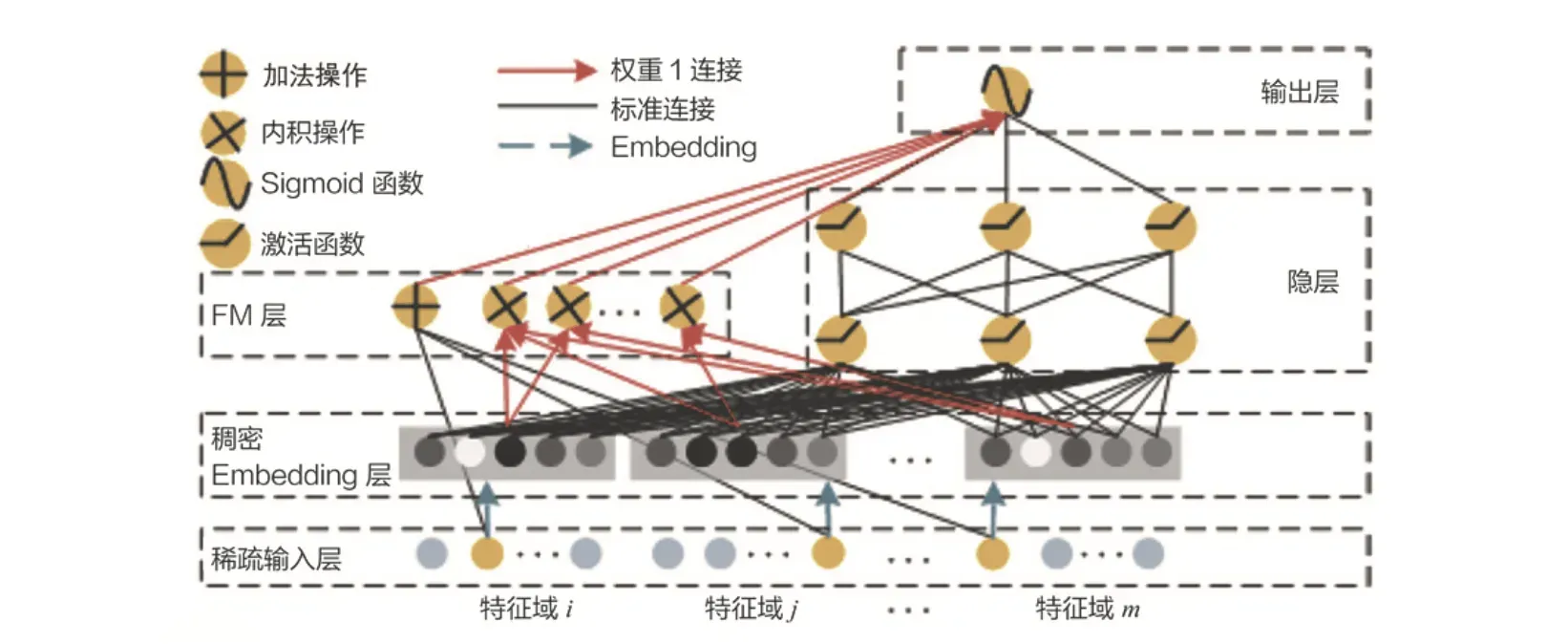
由上图的DeepFM架构图看出:
(1)用FM层替换了wide&deep左边你的wide部分;
——增强浅层网络的特征组合能力。
(2)右边保持和wide&deep一毛一样,利用多层神经元(如MLP)进行所有特征的深层处理
(3)最后输出层将FM的output和deep的output组合起来,产生预估结果
二、FM部分的数学优化
优化后的FM部分能够将原来的时间复杂度降低为
,其中n是特征数量,k是embedding size。具体的优化公式如下,其中第一步比较好理解(多算了一次所以要除二,减去多余的),第二步就是将都是k维的
和
向量的点积公式展开。第三步是难点(见下图),第四步前项因为两个不同的下标 i 和 j ,都是全和,所以可以合并为一个下标。
第三步(下)是关键,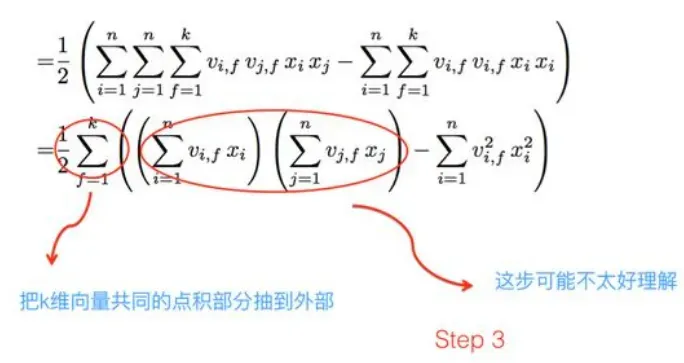
如果把k维特征向量内积求和公式抽到最外边后,公式就转成了上图这个公式了(不考虑最外边k维求和过程的情况下)。它有两层循环,内循环其实就是指定某个特征的第f位(这个f是由最外层那个k指定的)后,和其它任意特征对应向量的第f位值相乘求和;而外循环则是遍历每个的第f位做循环求和。这样就完成了指定某个特征位f后的特征组合计算过程。最外层的k维循环则依此轮循第f位,于是就算完了步骤三的特征组合。
三、改进FM后的模型代码
同样是将fm_1st_part、二阶特征交叉fm_2nd_part、dnn_output,拼接得到的向量送到最后的sigmoid函数中,进行预测。
其中构造一阶特征的embedding ModuleList:
import torch.nn as nn
categorial_feature_vocabsize = [20] * 8 + [30001] + [1001]
# 列表[20, 20, 20, 20, 20, 20, 20, 20, 30001, 1001]
fm_1st_order_sparse_emb = nn.ModuleList([nn.Embedding(vocab_size, 1)
for vocab_size
in categorial_feature_vocabsize])
print(fm_1st_order_sparse_emb)
"""
ModuleList(
(0): Embedding(20, 1)
(1): Embedding(20, 1)
(2): Embedding(20, 1)
(3): Embedding(20, 1)
(4): Embedding(20, 1)
(5): Embedding(20, 1)
(6): Embedding(20, 1)
(7): Embedding(20, 1)
(8): Embedding(30001, 1)
(9): Embedding(1001, 1)
)
"""
xi的大小是[128, 7],xv的大小是[128, 10],y的大小是[128]。
完整的模型部分:
import torch
import torch.nn as nn
import numpy as np
class DeepFM(nn.Module):
def __init__(self, categorial_feature_vocabsize, continous_feature_names, categorial_feature_names,
embed_dim=10, hidden_dim=[128, 128]):
super().__init__()
assert len(categorial_feature_vocabsize) == len(categorial_feature_names)
self.continous_feature_names = continous_feature_names
self.categorial_feature_names = categorial_feature_names
# FM part
# first-order part
if continous_feature_names:
self.fm_1st_order_dense = nn.Linear(len(continous_feature_names), 1)
self.fm_1st_order_sparse_emb = nn.ModuleList([nn.Embedding(vocab_size, 1) for vocab_size in categorial_feature_vocabsize])
# senond-order part
self.fm_2nd_order_sparse_emb = nn.ModuleList([nn.Embedding(vocab_size, embed_dim) for vocab_size in categorial_feature_vocabsize])
# deep part
self.dense_embed = nn.Sequential(nn.Linear(len(continous_feature_names), len(categorial_feature_names)*embed_dim),
nn.BatchNorm1d(len(categorial_feature_names)*embed_dim),
nn.ReLU(inplace=True))
self.dnn_part = nn.Sequential(nn.Linear(len(categorial_feature_vocabsize)*embed_dim, hidden_dim[0]),
nn.BatchNorm1d(hidden_dim[0]),
nn.ReLU(inplace=True),
nn.Linear(hidden_dim[0], hidden_dim[1]),
nn.BatchNorm1d(hidden_dim[1]),
nn.ReLU(inplace=True),
nn.Linear(hidden_dim[1], 1))
# output act
self.act = nn.Sigmoid()
def forward(self, xi, xv):
# FM first-order part
fm_1st_sparse_res = []
for i, embed_layer in enumerate(self.fm_1st_order_sparse_emb):
fm_1st_sparse_res.append(embed_layer(xv[:, i].long()))
fm_1st_sparse_res = torch.cat(fm_1st_sparse_res, dim=1)
fm_1st_sparse_res = torch.sum(fm_1st_sparse_res, 1, keepdim=True)
if xi is not None:
fm_1st_dense_res = self.fm_1st_order_dense(xi)
fm_1st_part = fm_1st_dense_res + fm_1st_sparse_res
else:
fm_1st_part = fm_1st_sparse_res
# FM second-order part
fm_2nd_order_res = []
for i, embed_layer in enumerate(self.fm_2nd_order_sparse_emb):
fm_2nd_order_res.append(embed_layer(xv[:, i].long()))
fm_2nd_concat_1d = torch.stack(fm_2nd_order_res, dim=1) # [bs, n, emb_dim]
# sum -> square
square_sum_embed = torch.pow(torch.sum(fm_2nd_concat_1d, dim=1), 2)
# square -> sum
sum_square_embed = torch.sum(torch.pow(fm_2nd_concat_1d, 2), dim=1)
# minus and half,(和平方-平方和)
sub = 0.5 * (square_sum_embed - sum_square_embed)
fm_2nd_part = torch.sum(sub, 1, keepdim=True)
# Dnn part
dnn_input = torch.flatten(fm_2nd_concat_1d, 1)
if xi is not None:
dense_out = self.dense_embed(xi)
dnn_input = dnn_input + dense_out
dnn_output = self.dnn_part(dnn_input)
out = self.act(fm_1st_part + fm_2nd_part + dnn_output)
return out
4.训练和测试部分
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import pandas as pd
import argparse
from torch.utils.data import DataLoader
from torch.utils.data import sampler
from data.dataset import build_dataset
from model.DeepFM import DeepFM
def train(epoch):
model.train()
for batch_idx, (xi, xv, y) in enumerate(loader_train):
xi, xv, y = torch.squeeze(xi).to(torch.float32), \
torch.squeeze(xv), \
torch.squeeze(y).to(torch.float32)
#print("xi的大小:\n", xi.shape, "\n") # torch.Size([128, 7])
#print("xv的大小:\n", xv.shape, "\n") # torch.Size([128, 10])
#print("y的大小:\n", y.shape, "\n") # torch.Size([128])
if args.gpu:
# 迁移到GPU中,注意迁移的device要和模型的device相同
xi, xv, y = xi.to(device), xv.to(device), y.to(device)
# 梯度清零
optimizer.zero_grad()
# 向前传递,和计算loss值
out = model(xi, xv)
loss = nn.BCELoss()(torch.squeeze(out, dim=1), y)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
if batch_idx % 200 == 0:
print("epoch {}, batch_idx {}, loss {}".format(epoch, batch_idx, loss))
def test(epoch, best_acc=0):
model.eval()
test_loss = 0.0 # cost function error
correct = 0.0
for batch_idx, (xi, xv, y) in enumerate(loader_test):
xi, xv, y = torch.squeeze(xi).to(torch.float32), \
torch.squeeze(xv), \
torch.squeeze(y).to(torch.float32)
if args.gpu:
xi, xv, y = xi.to(device), \
xv.to(device), \
y.to(device)
out = model(xi, xv)
test_loss += nn.BCELoss()(torch.squeeze(out, dim=1), y).item()
correct += ((torch.squeeze(out, dim=1) > 0.5) == y).sum().item()
if correct/len(loader_test) > best_acc:
best_acc = correct/len(loader_test)
torch.save(model, args.save_path)
print("epoch {}, test loss {}, test acc {}".format(epoch,
test_loss/len(loader_test),
correct/len(loader_test)))
return best_acc
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('-gpu', action='store_true', default=True, help='use gpu or not ')
parser.add_argument('-bs', type=int, default=128, help='batch size for dataloader')
parser.add_argument('-epoches', type=int, default=15, help='batch size for dataloader')
parser.add_argument('-warm', type=int, default=1, help='warm up training phase')
parser.add_argument('-lr', type=float, default=1e-3, help='initial learning rate')
parser.add_argument('-resume', action='store_true', default=False, help='resume training')
parser.add_argument('-train_path', action='store_true', default='data/raw/trainingSamples.csv',
help='train data path')
parser.add_argument('-test_path', action='store_true', default='data/raw/testSamples.csv',
help='test data path')
parser.add_argument('-save_path', action='store_true', default='checkpoint/DeepFM/DeepFm_best.pth',
help='save model path')
args = parser.parse_args()
# 连续型特征(7个)
continous_feature_names = ['releaseYear', 'movieRatingCount', 'movieAvgRating', 'movieRatingStddev',
'userRatingCount', 'userAvgRating', 'userRatingStddev']
# 类别型特征,注意id类的特征也是属于类别型特征,有10个特征(8个genre,2个id)
categorial_feature_names = ['userGenre1', 'userGenre2', 'userGenre3', 'userGenre4', 'userGenre5',
'movieGenre1', 'movieGenre2', 'movieGenre3', 'userId', 'movieId']
categorial_feature_vocabsize = [20] * 8 + [30001] + [1001]
# [20, 20, 20, 20, 20, 20, 20, 20, 30001, 1001] ,最后两个分别是userId 和 movieId
# build dataset for train and test
batch_size = args.bs
train_data = build_dataset(args.train_path)
# 用dataloader读取数据
loader_train = DataLoader(train_data,
batch_size=batch_size,
num_workers=8,
shuffle=True,
pin_memory=True)
test_data = build_dataset(args.test_path)
loader_test = DataLoader(test_data,
batch_size=batch_size,
num_workers=8)
# 正向传播时:开启自动求导的异常侦测
torch.autograd.set_detect_anomaly(True)
device = torch.device("cuda" if args.gpu else "cpu")
# train model
model = DeepFM(categorial_feature_vocabsize,
continous_feature_names,
categorial_feature_names,
embed_dim=64)
model = model.to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-3)
best_acc = 0
for ep in range(args.epoches):
# ep为训练的轮次epoch
train(ep)
best_acc = test(ep, best_acc)
5. 训练结果
最后训练得到的模型在测试集上的准确度为86.67%,效果还是阔以的!
epoch 0, batch_idx 0, loss 57.8125
epoch 0, batch_idx 200, loss 35.660301208496094
epoch 0, batch_idx 400, loss 39.15966033935547
epoch 0, batch_idx 600, loss 33.86609649658203
epoch 0, test loss 23.580318277532403, test acc 74.97727272727273
epoch 1, batch_idx 0, loss 32.055198669433594
epoch 1, batch_idx 200, loss 28.279659271240234
epoch 1, batch_idx 400, loss 21.818199157714844
epoch 1, batch_idx 600, loss 8.688355445861816
epoch 1, test loss 18.055269842798058, test acc 78.07954545454545
epoch 2, batch_idx 0, loss 19.79637908935547
epoch 2, batch_idx 200, loss 13.639955520629883
epoch 2, batch_idx 400, loss 10.169021606445312
epoch 2, batch_idx 600, loss 9.186278343200684
epoch 2, test loss 6.011827245354652, test acc 78.7215909090909
epoch 3, batch_idx 0, loss 8.763715744018555
epoch 3, batch_idx 200, loss 10.750226974487305
epoch 3, batch_idx 400, loss 2.757845163345337
epoch 3, batch_idx 600, loss 4.930475234985352
epoch 3, test loss 3.333007538183169, test acc 76.5909090909091
epoch 4, batch_idx 0, loss 2.1602728366851807
epoch 4, batch_idx 200, loss 2.197911262512207
epoch 4, batch_idx 400, loss 2.252277135848999
epoch 4, batch_idx 600, loss 1.0814595222473145
epoch 4, test loss 1.9333787821233273, test acc 81.45454545454545
epoch 5, batch_idx 0, loss 1.5760024785995483
epoch 5, batch_idx 200, loss 1.5287736654281616
epoch 5, batch_idx 400, loss 1.3700907230377197
epoch 5, batch_idx 600, loss 0.9534137845039368
epoch 5, test loss 1.315996164964004, test acc 81.10795454545455
epoch 6, batch_idx 0, loss 0.9218883514404297
epoch 6, batch_idx 200, loss 0.6848210096359253
epoch 6, batch_idx 400, loss 1.218489646911621
epoch 6, batch_idx 600, loss 0.882542073726654
epoch 6, test loss 1.1296405287628823, test acc 82.9034090909091
epoch 7, batch_idx 0, loss 0.7222120761871338
epoch 7, batch_idx 200, loss 0.5594819188117981
epoch 7, batch_idx 400, loss 1.3399994373321533
epoch 7, batch_idx 600, loss 0.8152369260787964
epoch 7, test loss 1.0356671606952494, test acc 79.01704545454545
epoch 8, batch_idx 0, loss 0.5979047417640686
epoch 8, batch_idx 200, loss 0.5507006645202637
epoch 8, batch_idx 400, loss 0.6000616550445557
epoch 8, batch_idx 600, loss 0.48930785059928894
epoch 8, test loss 0.8429303023625504, test acc 82.9659090909091
epoch 9, batch_idx 0, loss 0.3913853168487549
epoch 9, batch_idx 200, loss 0.9501373767852783
epoch 9, batch_idx 400, loss 0.670101523399353
epoch 9, batch_idx 600, loss 0.793392539024353
epoch 9, test loss 0.8035464127632704, test acc 86.01704545454545
epoch 10, batch_idx 0, loss 0.33485880494117737
epoch 10, batch_idx 200, loss 0.4916546940803528
epoch 10, batch_idx 400, loss 0.6082847118377686
epoch 10, batch_idx 600, loss 0.8132975101470947
epoch 10, test loss 0.7464344034140761, test acc 86.0965909090909
epoch 11, batch_idx 0, loss 0.4020095765590668
epoch 11, batch_idx 200, loss 0.549713671207428
epoch 11, batch_idx 400, loss 0.5974748134613037
epoch 11, batch_idx 600, loss 0.5721868872642517
epoch 11, test loss 0.7183683966709808, test acc 86.48863636363636
epoch 12, batch_idx 0, loss 0.3971376419067383
epoch 12, batch_idx 200, loss 0.3680552840232849
epoch 12, batch_idx 400, loss 0.6100645661354065
epoch 12, batch_idx 600, loss 0.5566384196281433
epoch 12, test loss 0.6802440441467545, test acc 85.4659090909091
epoch 13, batch_idx 0, loss 0.4752316176891327
epoch 13, batch_idx 200, loss 0.42497631907463074
epoch 13, batch_idx 400, loss 0.5759319067001343
epoch 13, batch_idx 600, loss 0.6097909212112427
epoch 13, test loss 0.6569343952631409, test acc 86.55681818181819
epoch 14, batch_idx 0, loss 0.36898481845855713
epoch 14, batch_idx 200, loss 0.42660871148109436
epoch 14, batch_idx 400, loss 0.5741548538208008
epoch 14, batch_idx 600, loss 0.5197790861129761
epoch 14, test loss 0.7259972247887742, test acc 86.67613636363636
Reference
[1] https://zhuanlan.zhihu.com/p/58160982
[2] deepFM论文地址:https://www.ijcai.org/proceedings/2017/0239.pdf
[3]PyTorch手把手自定义Dataset读取数据
[4] https://pytorch.org/docs/stable/data.html?highlight=dataloader#torch.utils.data.DataLoader
[5]Migrating feature_columns to TF2’s Keras Preprocessing Layers
[6]对于DeepFM参数共享的理解
[7]torch.autograd.detect_anomaly()
[8] deepFM算法代码:http://blog.sina.com.cn/s/blog_628cc2b70102yooc.html
文章出处登录后可见!