
概括
使用多个标签精确注释对象既昂贵又困难。相反,在许多实际任务中,注释者可能会粗略地为每个对象分配一组候选标签。候选集包含至少一个但未知数量的真实标签,并且通常掺杂一些不相关的标签。在本文中,我们将此类问题形式化为一种称为部分多标签学习(PML)的新学习框架。为了解决 PML 问题,为每个候选标签维护一个置信度值,以估计它是实例的真实标签的可能性有多大。一方面,通过最小化由置信度加权的等级损失来优化每个实例上标签的相关性排序;另一方面,通过进一步利用特征和标签空间中的结构信息来优化置信度值。在各种数据集上的实验结果表明,所提出的方法对于解决 PML 问题是有效的。
介绍
多标签学习 (MLL) 处理同时为每个对象分配多个类标签的问题 (Zhang and Zhou 2014)。例如,可以使用标签 sea、sunset 和 beach 对图像进行注释。多标签学习的任务是训练一个分类模型,该模型可以预测所有未见实例的相关标签。
在传统的多标签研究中,一个常见的假设是每个训练实例都已使用其所有相关标签进行了精确注释。然而,在许多应用中,这种假设几乎不成立,因为精确的注释通常很困难且成本高昂。相反,注释者可以粗略地为每个实例分配一组候选标签。除了相关标签外,候选集还包含一些不相关的标签。例如,在图 1 中,图像使用一组候选标签进行注释,这可能是众包设置下来自多个嘈杂注释器的注释的联合集。虽然通过部分标记显着降低了注释成本,但学习任务变得更具挑战性,因为真实标签与一些不相关的标签混合在一起,而且真实标签的数量甚至是未知的。
我们将这个学习问题形式化为一个称为部分多标签学习(PML)的新框架。更具体地说,PML 试图从部分标记的训练示例中学习多标签模型,其中每个实例都用一组候选标签进行注释,指示以下监督信息: a) 候选集可能包含相关和不相关的标签; b) 候选集中相关标签的数量至少为一个但未知; c) 不在候选集中的标签与实例无关。

图 1:部分多标签学习的示例。在众包中,图像部分由嘈杂的注释器标记。在候选标签中,建筑物、窗户、天空和街道是真实标签,而人、汽车和树是不相关的标签。
PML 是一种新颖的学习框架,与现有设置有显着差异。有一些研究试图利用弱监督来进行多标签学习。例如,半监督 MLL(Wang 和 Tsotsos 2016;Wu 等人 2015;Belkin、Niyogi 和 Sindhwani 2006)基于未标记和精确标记的示例训练模型;带有弱标签的 MLL 允许缺少标签(Sun、Zhang 和 Zhou 2010;Bucak、Jin 和 Jain 2011;Zhao 和 Guo 2015)。然而,这些方法没有考虑使用候选标签集进行部分标记,并且不能应用于 PML 问题。部分标签学习(Cour、Sapp 和 Taskar 2011;Szummer 和 Jaakkola 2001)类似于 PML,但专为单标签情况而设计,其中候选集中始终存在一个真实标签。我们将讨论 PML 与相关研究之间的差异更多细节在下一节。
如果可以从候选集中识别出真正的标签,则部分多标签学习会退化为标准多标签学习。不幸的是,这项任务非常具有挑战性,如果不是不可能的话。相反,我们假设每个候选标签都具有作为真实标签的置信度,并交替优化分类模型和置信度值。具体来说,为了实现多标签分类,我们优化标签对的相关性排名,根据其真实置信度将相关标签排在不相关标签之前。为了优化候选标签的真实置信度,除了最小化等级损失外,我们还提供了两个选项来进一步利用特征空间的局部结构或标签相关性。这些任务被制定为一个统一的目标函数,并且可以通过二次规划和线性规划的交替优化来有效地解决。我们对来自不同领域的数据集的实证研究证明了所提出方法的有效性。
革新:
| 1、提出了一种新的学习框架 PML,用于从部分标记的数据中学习多标签模型。 PML 定义了一个实际的学习任务,与现有的多标签学习设置有很大不同。 |
| 2、提出了两种有效的算法PML-lc和PML-fp来解决PML问题。它们提供了通过利用来自特征空间或标签空间的结构信息来优化候选标签的真实置信度的选项。 |
| 3、对各种数据集的实验验证了所提出方法的有效性。 |
相关工作
有大量关于多标签学习的文献。多标签学习最直接的方法是将任务分解为一组二元分类问题(Joachims 1998;Boutell 等人 2004)。这种方法独立处理每个标签,忽略标签之间的相关性,这对多标签学习至关重要(Zhang and Zhou 2014)。后来,许多研究试图利用标签相关性。其中一些专注于成对相关(Fürnkranz 等人 2008;Elisseeff 和 Weston 2001),而另一些则考虑所有标签之间的高阶相关性(Tsoumakas、Katakis 和 Vlahavas 2011;Read 等人 2011)。多标签学习已成功应用于各种任务,例如图像分类 (Cabral et al. 2011; Wang et al. 2016; Wu et al. 2015)、文本分类 (Rubin et al. 2012) 和基因功能预测 (Cabral et al. 2012)埃利塞夫和韦斯顿 2001)。
有一些研究试图从弱监督信息中学习多标签模型。一些方法尝试基于未标记和精确标记的示例来训练分类模型。例如,在 (Wang and Tsotsos 2016; Kong, Ng, and Zhou 2013) 中开发了基于标签传播的半监督多标签学习方法;在 (Guo and Schuurmans 2012) 中提出了一种同步大边距和子空间学习方法;并且在 (Jing et al. 2015) 中介绍了一种基于低秩映射的方法。其他一些方法侧重于缺少一些相关标签的情况。例如,孙等。人。 (2010) 提出基于低密度假设研究弱标签的多标签学习;布卡克等。人。 (2011) 提出了一种基于排序的方法,用于具有不完整类分配的多标签学习;和于等。人。 (2015)开发了一种用于缺少标签的多标签学习的大规模方法。还有一些方法试图从干净和嘈杂的数据中学习(Veit et al. 2017)。然而,这些方法没有考虑使用候选标签集进行部分标注,无法解决 PML 问题。
部分标签学习类似于我们的 PML 问题,但专门针对单标签任务。它假设候选集中总是有一个准确的事实。大多数部分标签学习方法采用消歧策略,即尝试从候选标签集中恢复真实标签。一种消歧策略是假设某个参数模型 F (x, y; θ) 并将groundtruth标签视为潜在变量。在这里,潜变量通过优化某些目标来迭代细化,例如最大似然准则(Grandvalet 和 Bengio 2004;Jin 和 Ghahramani 2002;Liu 和 Dietterich 2012),或最大边际准则(Yu 和 Zhang 2017)。另一种消除歧义的方法是假设每个候选标签的重要性相同,然后通过平均它们的建模输出来进行预测。对于参数模型,所有候选标签的平均输出不同于候选标签的输出(Cour、Sapp 和 Taskar 2011)。对于非参数模型,未见实例的预测标签是通过对 PL 训练集中相邻实例的候选标签信息进行平均来确定的(Hüllermeier 和 Beringer 2006;Zhang 和 Yu 2015)。部分标签学习的可学习性已在(Liu and Dietterich 2014)中进行了研究。与部分标签学习相比,PML 更具挑战性,因为候选集中的真实标签数量是未知的,这使得消歧不适用。
可以通过最小化由置信度加权的排名损失(Elisseeff 和 Weston 2001)来优化整个训练集的排名:
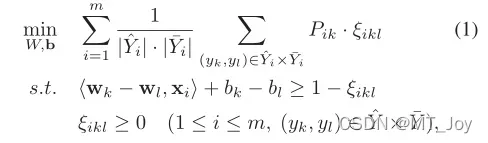
类似地,我们可以有以下优化问题来最小化整个训练集上标签内对的排名损失:
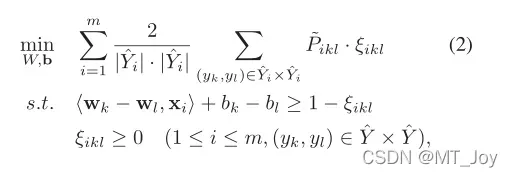
可以合并方程式。 1和等式。 2 在统一的目标函数中考虑组间和组内标签对的排名损失
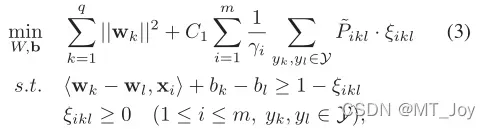
通过进一步结合模型预测,我们有以下用于学习 置信矩阵 P 的优化问题:
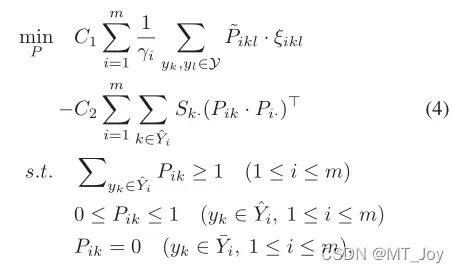
通过梳理方程式4 与等式3、我们得到了带有标签相关性的部分多标签学习的最终目标函数(简称PML-lc):
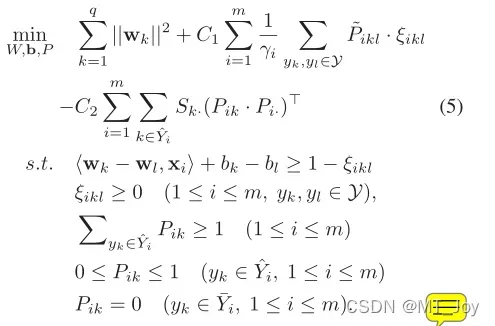
类似于方程式 4、我们有
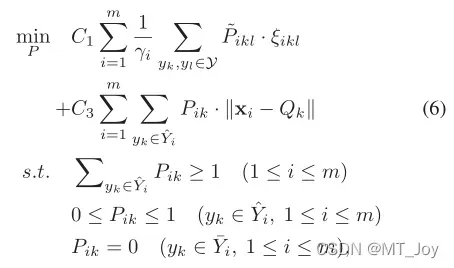
然后通过梳理方程式。 6 与等式。 3,我们有最终的目标函数用于部分多标签学习与特征原型(简称 PML-fp):
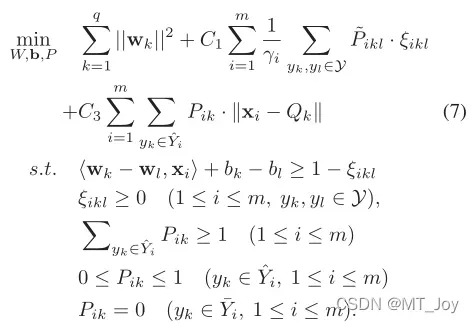


综上所述
在本文中,我们提出了一种新的学习框架,称为部分多标签学习(PML),其中每个实例都与一组候选标签相关联。为每个候选标签定义了一个置信度值,以估计它是真实标签的可能性有多大。通过最小化置信度加权排序损失和利用数据结构信息,分类模型和真实置信度在一个统一的框架中得到优化。在各种数据集上进行了实验,结果验证了所提出的方法优于最先进的多标签方法。未来,我们计划通过结合领域知识和设计更高级的分类模型来改进 PML 算法。
文章出处登录后可见!