前言
本章重点介绍用于预测问题的三个数据(节点、边、图)级别的手工设计无向图(因为它们简单且易于处理)特征。
一、基于节点特征的传统方法:
1.1、节点的度 Node degree
节点v的度数是节点的边的数目,所有的邻接的节点都要平等对待。
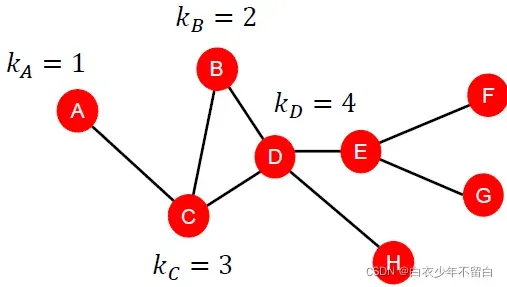
1.2、节点中心性 Node centrality
节点度计算相邻节点而不考虑它们的重要性。节点中心性考虑了图中节点的重要性。测量节点重要性也有不同的建模方法:
1.2.1、特征向量中心 Eigenvector centrality:
核心思想:如果节点邻居重要,那么节点本身也重要。因此节点v的centrality是邻居centrality的加总:(
是某个正的常数)。这是个递归式,解法是将其转换为矩阵形式:
,其中A是邻接矩阵,c是centralty向量。
1.2.2 中间性中心 Betweenness centrality:
核心思想:认为如果一个节点在许多节点对的最短路径上,那么这个节点很重要。计算如下:
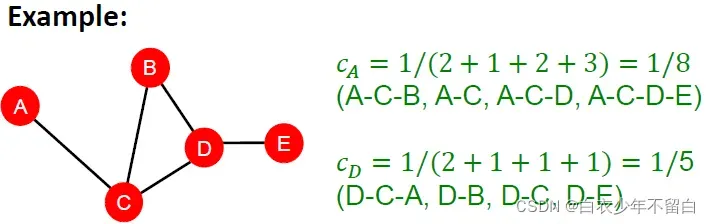
1.3、聚类系数 Clustering coefficient
如果一个节点与其他节点的距离最短,则认为该节点很重要。计算如下: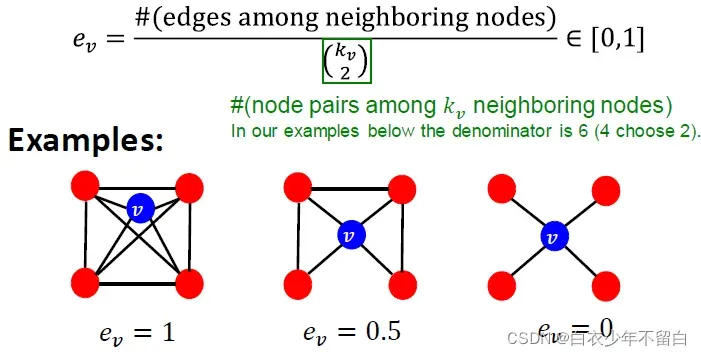
这种是组合数的写法,和国内常用的C写法上下是相反的。所以这个式子代表 v邻居所构成的节点对,即潜在的连接数。整个公式衡量节点邻居的连接有多紧密’
- 第1个例子:对于节点v来说,邻居节点一共有4个,这4个邻居节点构成了6条边,他们所有可能构成的边为
,因此其聚类系数为
- 第2个例子:对于节点v来说,邻居节点一共有4个,这4个邻居节点构成了3条边,他们所有可能构成的边为
- 第3个例子:对于节点v来说,邻居节点一共有4个,这4个邻居节点构成了0条边,他们所有可能构成的边为
1.4、有根连通异构子图 Graphlets
经过观察,在社交网络之中会有很多三角形,因为可以想象你的朋友可能会经由你的介绍而认识,从而构建出一个这样的三角形/三元组。在计算这样网络的聚类系数时候,我们可以通过计数#(预先指定的子图,也就是graphlet)来推广上面的方法。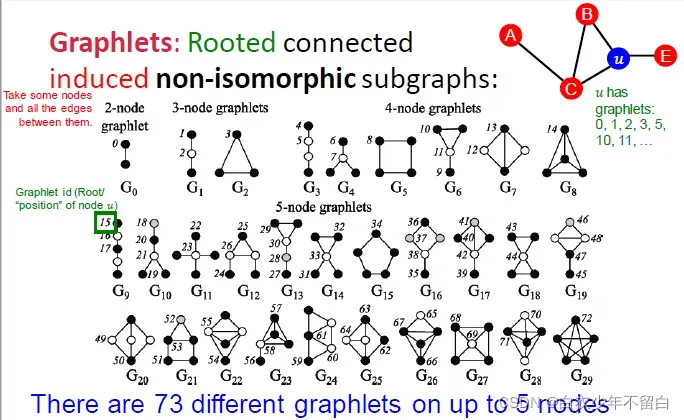
从上图可以看到,对于某一给定节点数,会有
个连通的异构子图。首先来说,这些图是联通的,其次都有k个节点,最后它们异构。(有种重回高中化学学习同分异构体的感觉)节点数为2-5情况下一共能产生如图所示73种graphlet。这73个graphlet的核心概念就是不同的形状,不同的位置。
下面说一下衡量graphlet的几个指标:
Degree 度:一个顶点能接触到边的数目
Clustering coefficient 聚类系数:计数节点所触及的#(三角形)。
Graphlet度向量(GDV) Graphlet Degree Vector (GDV) :用于节点的Graphlet基本特性 GDV计数节点所触及的#(graphlets)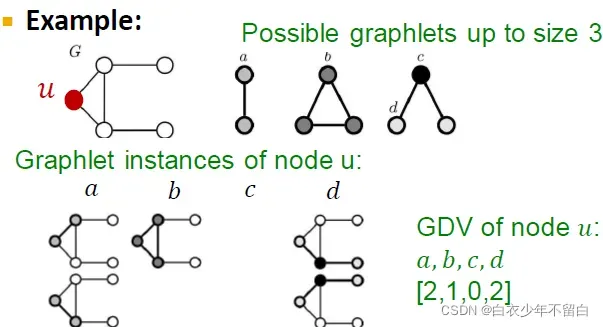
如图所示,对四种graphlet,v的每一种graphlet的数量作为向量的一个元素。
注意:graphlet c的情况不存在,是因为像graphlet b那样中间那条线连上了。这是因为graphlet是induced subgraph,所以那个边也存在,所以c情况不存在。
考虑2-5个节点的graphlets,我们得到一个长度为73个坐标coordinate(就前图所示一共73种graphlet)的向量GDV,描述该点的局部拓扑结构topology of node’s neighborhood,可以捕获距离为4 hops的互联性interconnectivities。
相比节点度数或clustering coefficient,GDV能够描述两个节点之间更详细的节点局部拓扑结构相似性local topological similarity。
1.5、Node Level Feature: Summary
这些功能可以分为两类,即:
1.5.1 基于重要性的特征 Importance based features:
- 能够捕捉图中节点的重要性
**节点的度数:**只需要统计节点的相邻节点数。
**节点的中心程度:**在图中模拟相邻节点的重要性;有不同的建模方案,比如:eigenvector centrality,betweenness centrality, closeness centrality - 用于预测图中有影响力的节点,例如预测社交网络中的有影响力的人。
1.5.2 基于结构的特征:
- 捕获节点周围局部邻域的拓扑属性,主要分为三类:
Node degree:
计算相邻节点的数量
Clustering coefficient:
测量邻居节点的连通性
Graphlet degree vector:
计数不同的graphlet的出现次数
用于预测节点在图中的具体作用: ▪ 示例:预测蛋白质-蛋白质相互作用网络中的蛋白质功能。
讨论
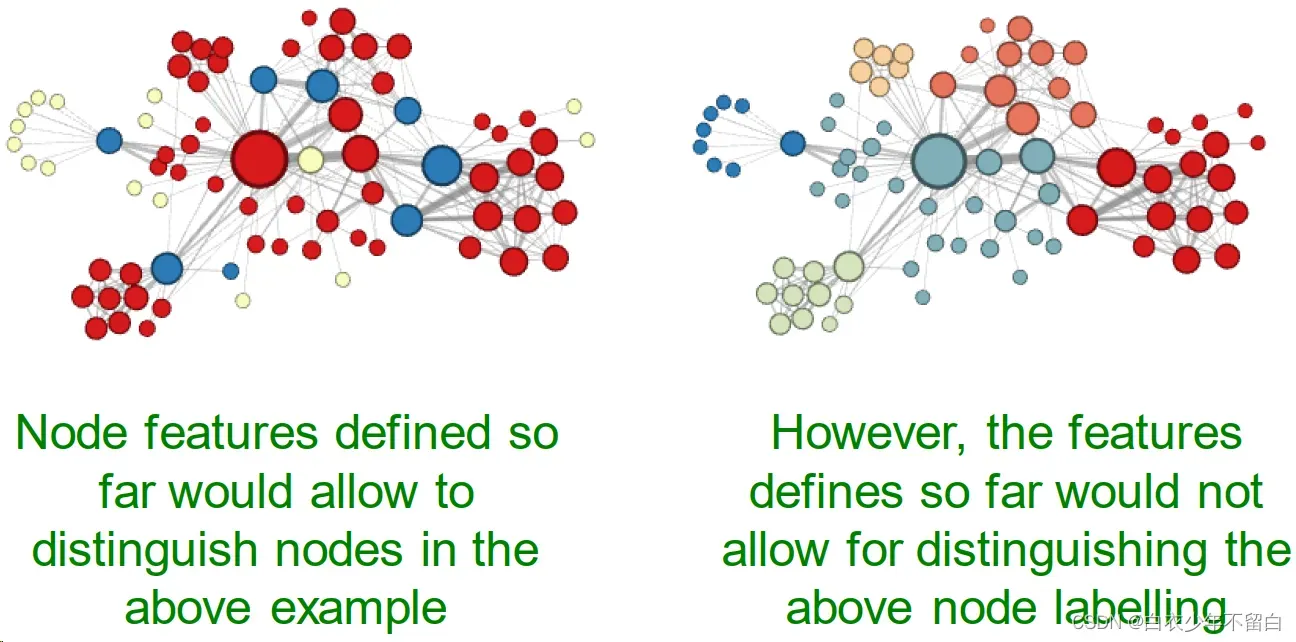
我对这段理解是现阶段定义的节点特征可以在上述例子里分辨节点,但在node标签上无法分辨是不是之前的node种类。也就是说,它目前能识别空间结构,但是无法在相同的空间结构分辨节点种类。
二、传统的基于边缘的特征方法:
2.1 链路级预测任务:Recap
任务是根据现有的链接预测新的链接。测试时,对无链路的节点对进行排序,预测top k节点对。关键是为一对节点设计特征。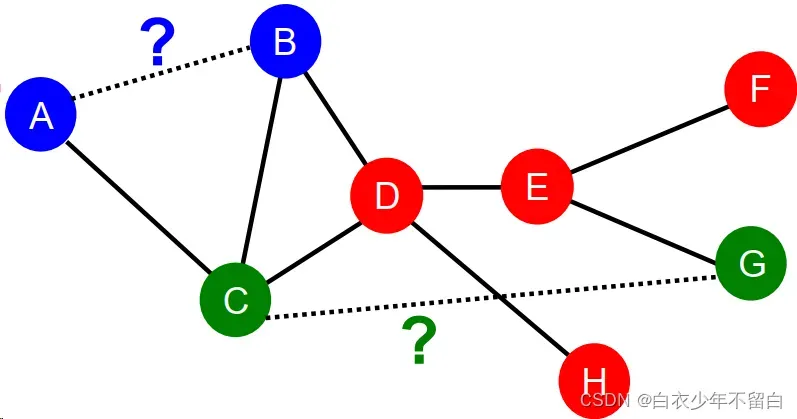
链接预测任务的两个公式:
- 随机缺失边
一组随机链接被删除,目标是预测它们是如何连接的。与化学键研究类似,不同的化学键具有不同的功能。 - 随着时间的推移
现在根据时间的边定义了一个图
,并输出一个排序的边列表。这里的边不是上一次
预测的。这类似于人们如何随着时间的推移扩大他们的朋友圈。
采用的评价方式是在时间段内产生的新边期望和取L的最上面n个元素,并计算正确的边数。
2.1.1 基于相似性进行链接预测:
计算两点间的相似性得分(如用共同邻居衡量相似性),然后将点对进行排序,得分最高的n组点对就是预测结果,与真实值作比。方法如下:
对每对节点(x,y)计算得分c(x,y)
- 例如,c(x,y)可以是x和y的共同邻居
- 对(x,y)按分数递减的c(x,y)排序
- 预测前n对为新链接
- 看看这些链接实际上出现在
2.1.2 两点间最短路径的长度 distance-based feature:
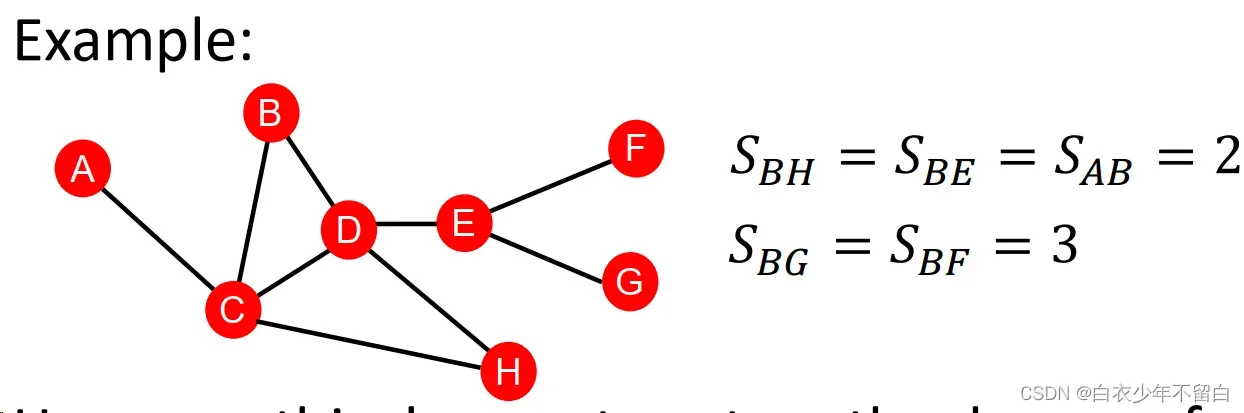
这种方式的问题在于没有考虑两个点邻居的重合度(the degree of neighborhood overlap),如B-H有2个共同邻居,B-E和A-B都只有1个共同邻居。
2.1.2 捕获节点的共同邻居数 local neighborhood overlap:
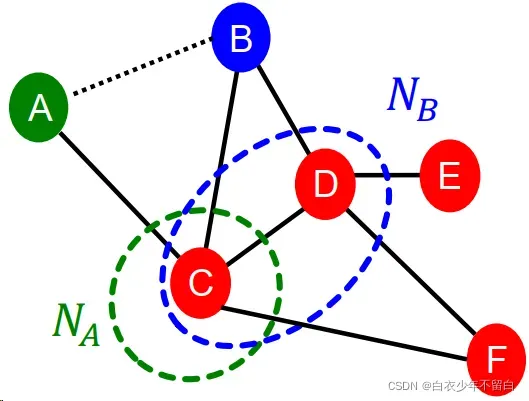
捕获两个节点𝒗𝟏和𝒗𝟐之间共享的相邻节点:
- 共同邻居:
例如: - Jaccard的系数:
- Adamic-Adar指数:
例如:
共同的邻居的问题在于度数高的点对就会有更高的结果,Jaccard的系数是其归一化后的结果。
Adamic-Adar指数在实践中表现得好。在社交网络上表现好的原因:有一堆度数低的共同好友比有一堆名人共同好友的得分更高。
2.1.3 全域邻居节点重叠 global neighborhood overlap:
local neighborhood overlap的限制在于,如果两个点没有共同邻居,值就为0。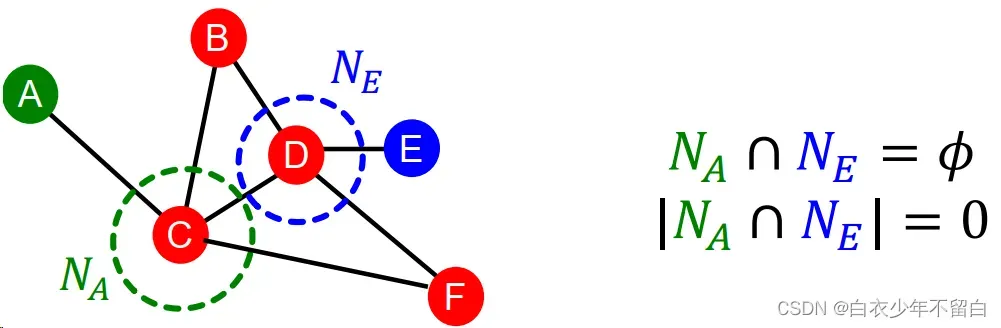
但是这两个点未来仍有可能被连接起来。所以我们使用考虑全图的global neighborhood overlap来解决这一问题,主要计算Katz index。
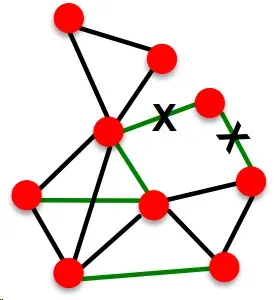
Katz index:计算点对之间所有长度路径的条数
计算方法:邻接矩阵求幂
4. 邻接矩阵的k次幂结果,每个元素就是对应点对之间长度为k的路径的条数
5. 证明如下: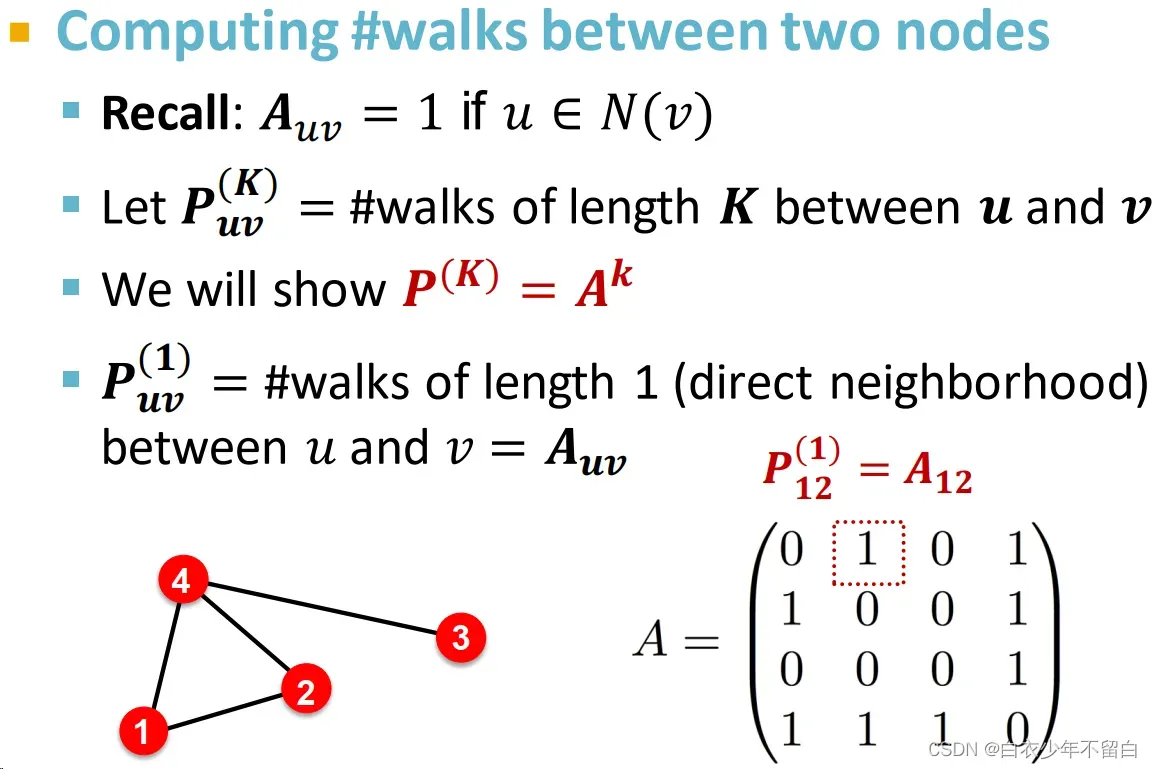
显然代表u和v之间长度为1的路径的数量。上图计算了
,接下来要计算
,具体方法如下:

如图所示,计算和
之间长度为2的路径数量,就是计算每个
的邻居
(与
有长度为1的路径)与
之间长度为1的路径数量
即
的总和
同理,更高的幂(更远的距离)就重复过程,继续乘起来。
从而得到Katz index的计算方式:
总结:
6.两点间最短路径的长度 distance-based feature:
使用两个节点之间的最短路径长度,但不捕获邻域如何重叠。
7.捕获节点的共同邻居数 local neighborhood overlap:
捕获两个节点共享的相邻节点的数量。当没有邻居节点被共享时,值为0。
8.全域邻居节点重叠 global neighborhood overlap:
采用全局图结构对两个节点进行评分。Katz索引计数两个节点之间的所有长度的散步数。
三、基于图特征的传统方法:
图级特征构建目标:找到能够描述整个图结构的特征。
3.1 背景知识:Kernel Methods

类似于SVM的核函数,定义好以后,通过核函数矩阵的映射,就可以按照之前的方式来处理了。
3.2 概述
图内核:测量两个图之间的相似性:
- Graphlet Kernel
- Weisfeiler-Lehman Kernel
也有一些其他核函数,但是超出了我们本节课的范围,比如:Random-walk kernel、Shortest-path graph kernel…
那么接下来,将之前的“寻找可以描述整个图结构的特征”转换为只找到“图特征向量”。
3.3 Graph kernel:Key Idea
回想之前NLP领域应用最多的词袋模型(Bag-of-Words (BoW)),它是将单词计数作为文档的特性(不考虑排序)。
在这里,我们将图视为向量,将图中的节点视为单词。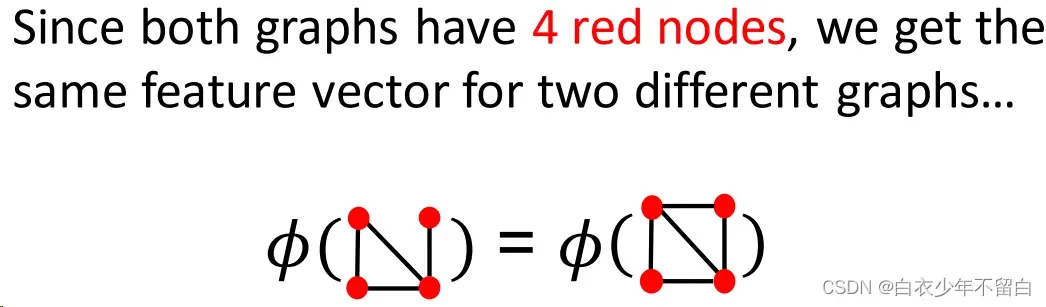
如上图所示,光用node不够的话,可以设置一个degree kernel,用bag-of-degrees来描述图特征。
3.4 Graphlet Feature
Key idea: 计算图表中不同的graphlets的数量
这里graphlet的定义与节点级特性略有不同,俩处不同在于:
- 这里的graphlet中的节点不需要连接(允许独立的节点)
- 这里的graphlet没有根
3.4.1 对每一种节点数,可选的graphlet:
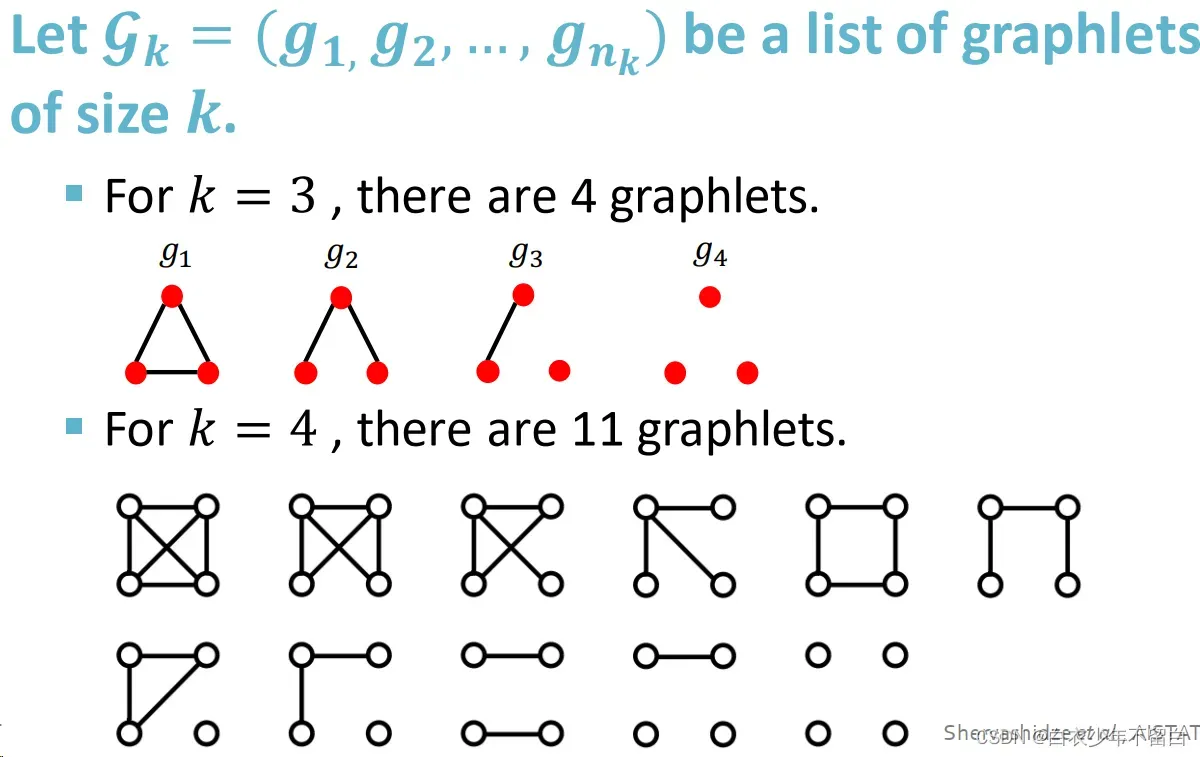
3.4.2 graphlet count vector:每个元素是图中对应graphlet的数量:

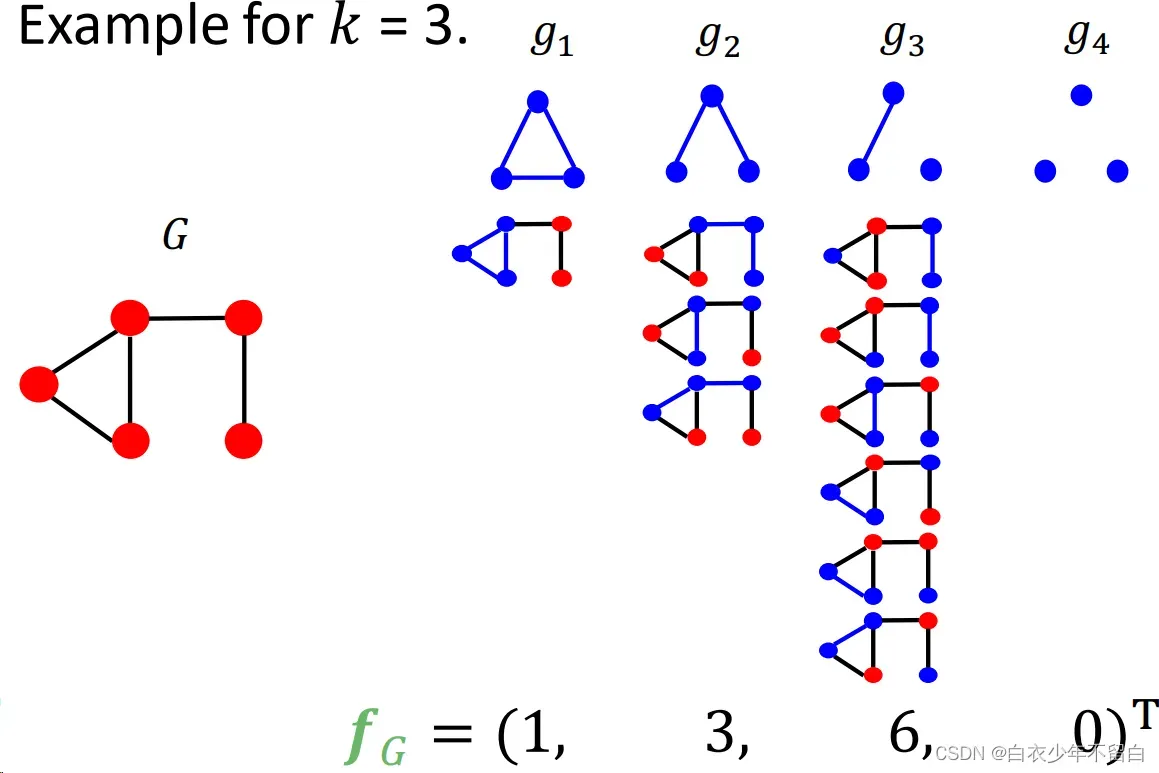
3.4.3 graphlet kernel:
graphlet kernel就是直接点积两个图的graphlet count vector得到相似性。对于图尺寸相差较大的情况需进行归一化
graphlet kernel的限制:计算昂贵,原因如下:
接下来,就是对刚才graphlet核方法的改进。
3.4.4 Weisfeiler-Lehman kernel:
相比graphlet kernel代价较小,效率更高。用节点邻居结构迭代地来扩充节点信息。
节点度的广义包,因为节点度是单跳邻域信息。
算法:
color refinement示例
收集邻居颜色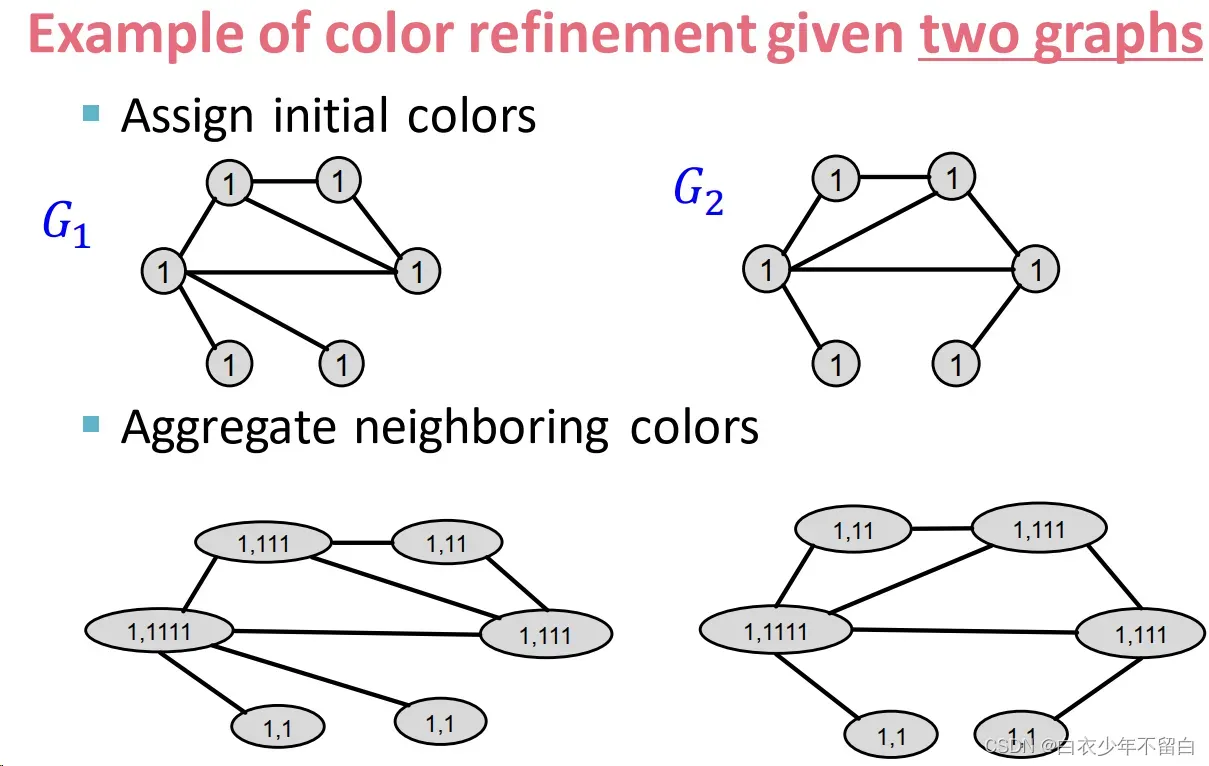
聚合颜色的哈希值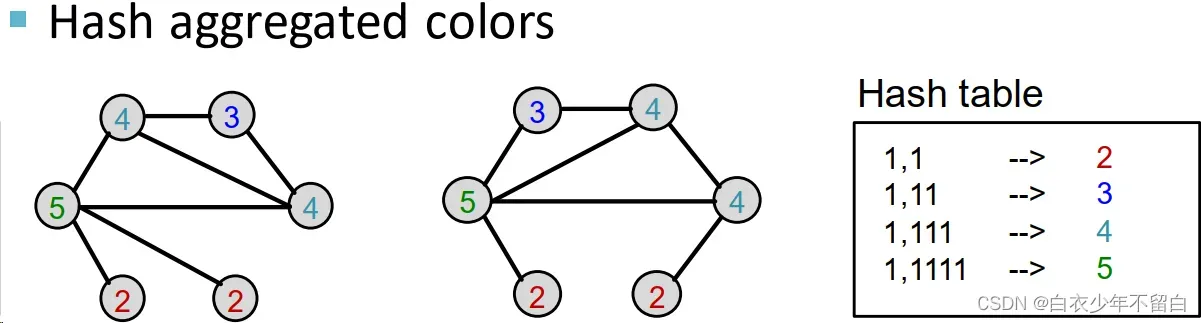
把hash后的颜色聚集起来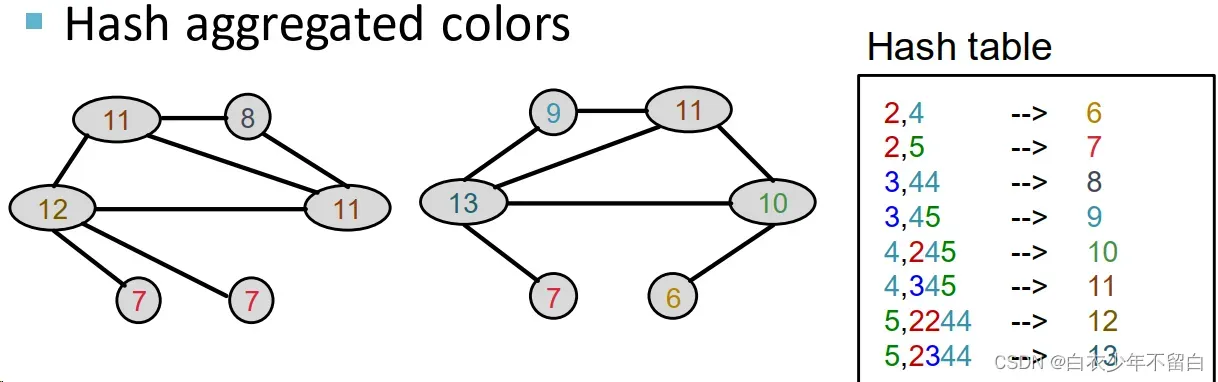
进行K次迭代12后,用整个迭代过程中颜色出现的次数作为Weisfeiler-Lehman graph feature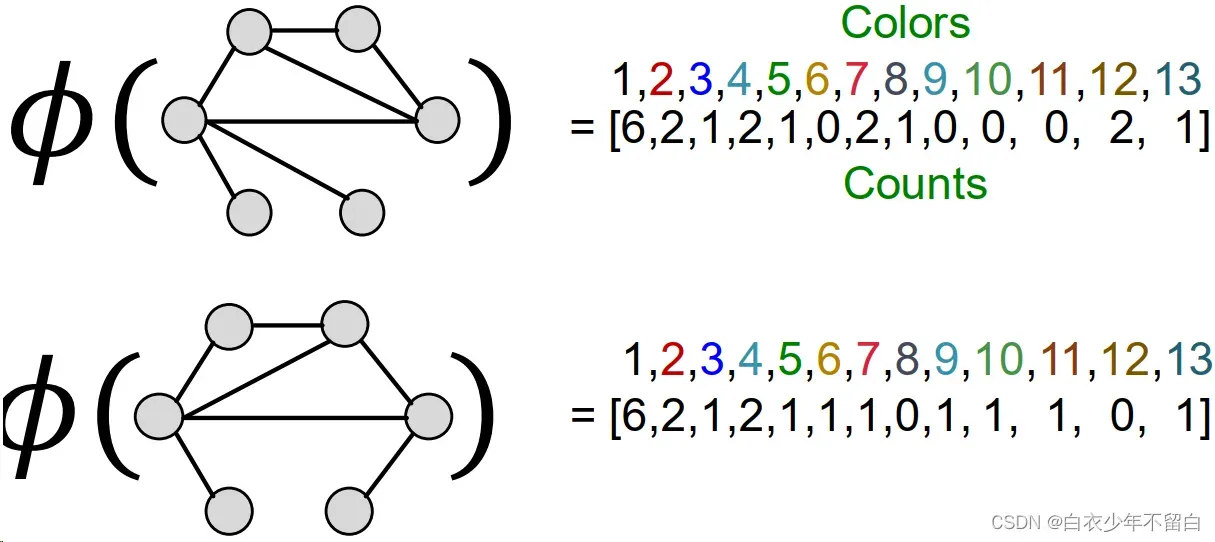
这里第一个图的特征应该是算错了,最后3个元素应该是2 1 0
通过颜色计数向量的内积计算WL核值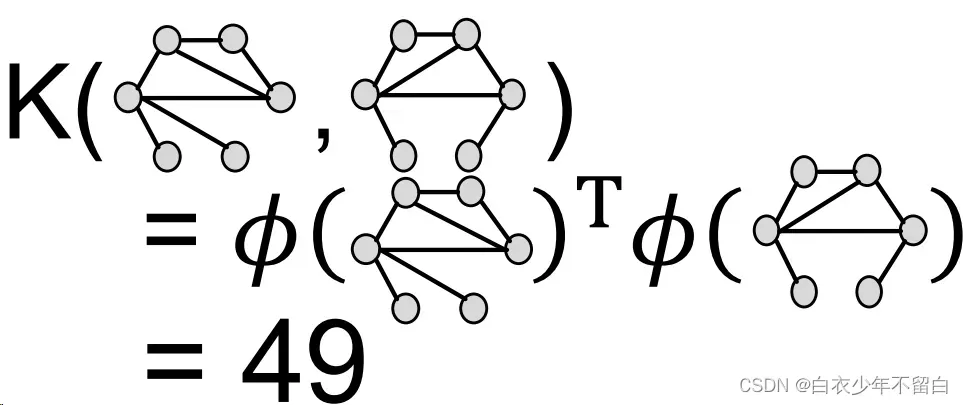
WL kernel的优势在于计算成本低
3.5 总结
3.5.1 Graphlet Kernel
- Graph表示为Bag-of-graphlets
- 计算量大
3.5.2 Weisfeiler-Lehman Kernel
- 应用𝐾-step颜色细化算法来丰富节点颜色
不同的颜色捕捉不同的𝐾-hop社区结构 - 人物用彩袋表示
- 计算效率
- 与图神经网络密切相关(我们将看到!)
4.总结

文章出处登录后可见!