



作者‖ flow 毕业于中国科学院大学,人工智能领域优质创作者
编辑‖3D视觉开发者社区
✨如果觉得文章内容不错,别忘了支持三遍😘~
介绍:
Connecting theDots是由德国图宾根大学团队发表于2019CVPR的论文,作者在主动单目结构光深度估计问题上提出了一套基于深度学习的解决方案,是当时第一篇提出利用深度学习对该问题进行解决的文章,本文将对作者提出的方案进行详细解读。
Connecting the Dots:Learning Representations for Active Monocular Depth Estimation
论文地址:点击进入
附件链接:在这里获取
资料链接:看这里
0. 概述
这篇文章是2019年的CVPR,在单目结构光深度估计问题上提出了一套基于深度学习的解决方案,截至当时,是第一篇提出利用深度学习对该问题进行解决的文章,具体的贡献有:
- 粗卷积。作者没有把深度估计的问题看成是寻找同名点的问题,而是论证和实验了最简单的卷积结构就足以得到高质量的视差估计结果。
- 自监督。由于单目结构光的GT不容易获取,因此作者通过设计精巧的损失函数对网络进行自监督。
- 实时解耦。文章认为实时图像可以分为散斑图像和泛光图像,泛光图像可以用来改善深度图的边缘效果。具体的实现方法是将图像和深度边缘以弱监督的方式结合起来。分布是建模的。
- 合成模拟数据。一种模拟散斑图案的合成数据方法,允许在受控条件下验证主动深度估计算法。
在下文中,将对单目结构光的成像原理及其数学表达、网络结构及损失函数、实验结果进行介绍。为简便起见,以下将简称本文方法为CTD。
所谓的单目结构光深度估计,我们知道,双目的深度估计是易于理解的几何交会关系,而单目结构光的设定则可以简单地将其理解为更换掉双目中的一个相机,并将其替换为结构光相机,结构光相机发射设计过的散斑图案到物体上,然后被另一个IR相机(相当于原双目的另一目)接收。不同距离接收到的散斑图案是不一样的,具体来说,是会在水平方向上进行左右的平移,而这个特性,就使得我们可以通过计算某散斑图与一固定距离的散斑图之间的视差,进而基于简单的空间几何关系来得到深度,类似于双目中的

1. 空间结构光成像原理及数学表达
CTD将单目结构光的工作原理表述为下图的形式: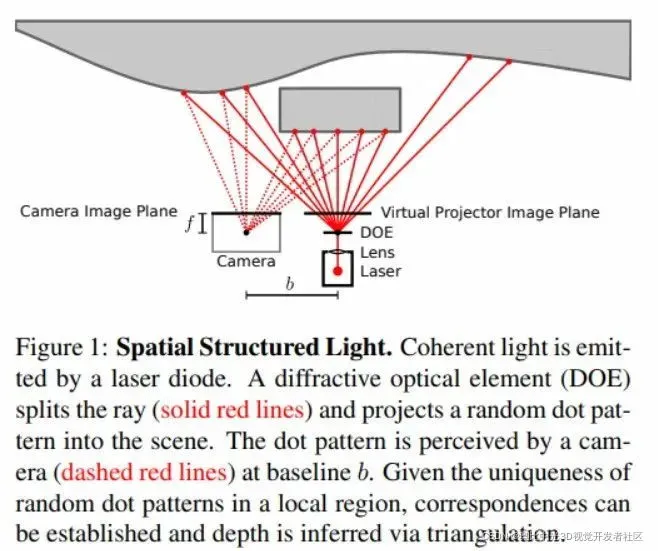
简单来说,就是Laser通过DOE将局部结构唯一的散斑投影到物体上,然后相机对信息进行接收成像。类比双目,我们可以将投影视作第二个相机,其虚拟的影像平面给出了由DOE确定的参考散斑,这些散斑在局部来说,是唯一的,因此,我们可以通过经典的基于窗口的匹配方法建立其由相机感知到的影像与投影打出的虚拟影像之间的对应关系 。得到视差


至于能够为实时解耦提供数学支持的数学表达式:
现在假设
而无噪声的二维影像


我们现在继续假设反射情况是朗伯反射,那么

在这个公式中,有一个隐含的假设,即从物体到光源的距离存在二次衰减。事实上,严格来说,二次衰减只适用于点光源,但考虑到激光束的发散,论文认为二次衰减应该与二次衰减相似。
以上的3个公式将用于对实时图进行解耦,具体指将其解耦为泛光图以及散斑图。这里再强调一下,为什么会想要费工夫做这样的解耦呢?因为对于泛光图来说,其包含的关于深度的密集信息往往与边缘是对齐的,而散斑图则互补地携带了深度信息。因此,该模型能够相比起那些仅仅考虑了稀疏散斑的传统方法而言,在边界上更有优势。
2. 网络结构
CTD将单目结构光深度估计看做一个视差回归问题,具体的网络结构如下: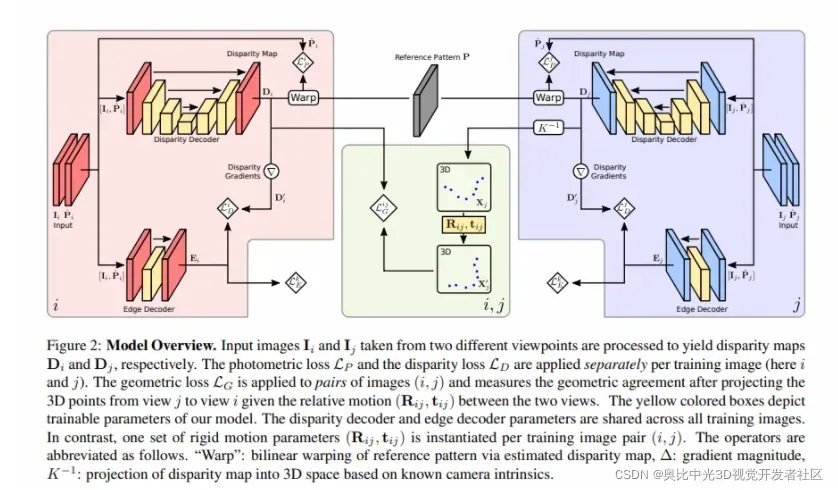
网络结构图中的绿色框内表示了几何损失(见“3. 损失函数”中的描述)的计算示意,既然是用于约束跨视点的几何关系,自然需要输入不同视点的信息,即红框内的视点i以及蓝框内的视点j。整个模型中需要训练的参数用黄色表示,视差和边缘的解码器对于所有的视点来说是参数共享的。对于任何的两视图

对于这整个网络结构而言,我们输入两个视点的影像,这两个视点分别标注为




2.1. 影像预处理:LCN
相机接收到的实时图表现与各种各样的因素有关,比如环境照明,比如物体材质,比如深度,比如投影模式等等。为了尽可能地减少这些因素的影响,尤其是减弱材质M以及深度Z的影响,采用了local contrast normalization(以下将简称LCN)的预处理方式:
经过这样的预处理后,环境光照明将比散斑显著降低,进而,在


2.2. 视差解码器
将原始的影像和经过LCN的影像进行concat后,再将其喂给视差解码器,而这个所谓的视差解码器将会直接预测出视差,对视差进行回归而不是对深度进行回归的原因是视差才是跟影像直接相关的东西。此外,在自监督的设定下,对视差这种相对的目标进行回归比对绝对位置进行回归实验效果要好多了。解码器的设置和UNet的架构非常相似。
2.3. 边缘解码器
CTD认为由于散斑的稀疏性,不足以预测出足够正确和锐利的物体边界。而物体边界的信息,却可以很方便地从泛光图中取得,此外,作者认为视差梯度和泛光图的梯度一致是比较合理的假设。
考虑到泛光图的边界可以通过借助局部信息,很好的从散斑以及其他干扰项中分离出来,文章使用了一个浅U-Net架构来从影像中来预测边缘
如下图所示,边缘解码器可以更好地识别边缘。
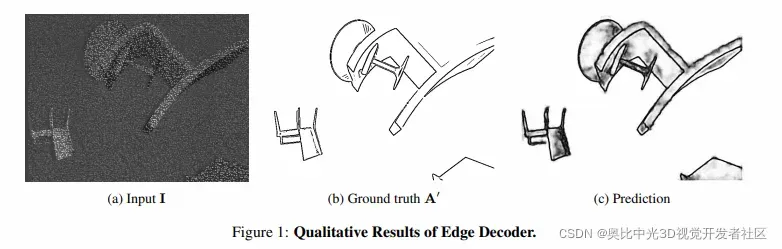

3. 损失函数
与双目相比,单目结构光的深度估计损失函数要复杂得多,主要是因为需要自监督。
3.1. 光度损失
photometric metric

在单张影像上计算。类似于双目的自监督模式,这不过是用投射的散斑替代了双目中的参考影像,小写的

对于CTD来说,光度损失是一个很基础很重要的损失,由于自监督的形式,网络接触不到GT,因此,CTD直接将光度损失作为指标去选择最优模型。
3.2. 视差损失
disparity loss"Our disparity loss models first-order(e.g., gradient) statistics of the disparity map conditioned on the edges of the latent ambient image."。

假设使用二进制


其中参数

更有,我们假设




也就是说,当边缘分布确定后,我的视差图的梯度应该满足上面的分布。
联合概率分布为:

最后,这个联合概率分布再套上负

CTD认为,这样的概率分布假设足以表达边缘与视差图梯度的一致性了,但是如果想要扩展成其他的分布情况也是ok的。
3.3. 几何损失
geometric loss
为了能够构造几何损失,我们需要对视差图做一些变换,将第二视角的视差图


具体来说,视差图与3D点云之间的变换可以由该公式来实现:

然后,我们可以通过




注意,应用时损失是双向的,即
3.4. 边缘损失
edge loss



在进行
3.5. 整体损失
现在,我们假设

所以现在对于整体

4. 实验
4.1合成数据仿真
为了能够有效地评估不同算法的效果,我们需要具有绝对精度的GT,尽管这样的GT可以通过高精度的3D扫描仪获得,但显然,成本是昂贵的。因此,CTD直接进行仿真,得到可用于评估的合成数据。仿真过程遵守了空间结构光成像原理及数学表达的指导,具体的仿真过程推荐阅读原论文中的描述,在此不做赘述,下图为仿真的实例结果:

4.2. 论文实验结果
4.2.1 合成数据结果
共获取8448个序列,其中8192个序列用于训练,256个用于测试,每个序列包含4对图片。投影使用的散斑为kinect V1,基线设置为7.5cm,影像大小为640 * 480。三维模型源于shapenet,物体摆放距离在2m至3m之间,背景为一倾斜平面,距离在2m至7m之间。评价指标类似与双目的设定,使用



CTD与其他方法的比较结果如下表所示: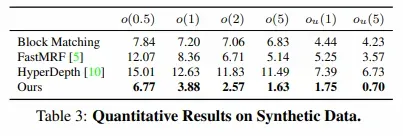
就表中的数值指标来看,CTD相对于其他方法在所有的指标上都具备一定优势。总体上看来,是有价值的。

4.2.2 真实数据结果
在真实数据上,文章采用了Chen等人(2014,CVPR)提供的数据集,这个数据中有五个扫描的模型,以及使用PrimeSense采集的序列数据(物体距离相机大约1米左右)。
具体来说,五个扫描模型如下所示:
将网络输出的视差转点云,而后与GT点云进行对齐。定量评估通过网络转的点云与GT点云之间的平均距离以及点云的完整性来衡量,同时,给出这两个指标的调和平均数作为综合指标。由于整个数据集只有60张影像,因此,HyperDepth(2016,CVPR)直接在所有的数据上进行训练。定量的指标结果见下表: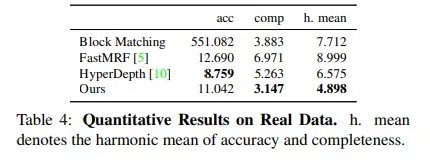
定性结果如下图所示: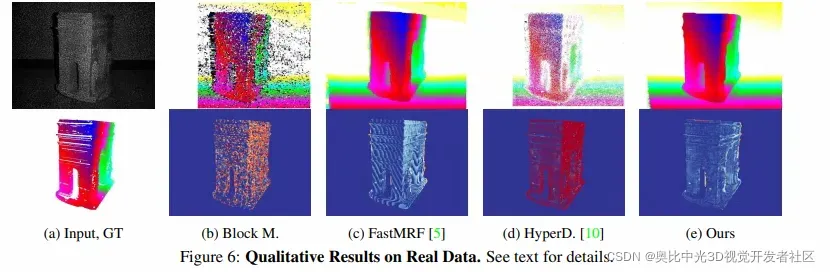
对于更为复杂的真实场景,文章使用了Kinect v1采集了3191张数据用于训练,623张数据用于测试。下图为在测试集上定性的3D点云结果:
并无定量的结果。但就目视效果上来看,泛化暂时看起来也是ok的。




参考
[1] Q. Chen and V. Koltun. Fast MRF optimization with application to depth reconstruction. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2014.
[2] S. R. Fanello, C. Rhemann, V. Tankovich, A. Kowdle, S. Orts-Escolano, D. Kim, and S. Izadi. Hyperdepth: Learning depth from structured light without matching. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2016
版权声明:本文为奥比中光3D视觉开发者社区特约作者授权原创发布,未经授权不得转载,本文仅做学术分享,版权归原作者所有,若涉及侵权内容请联系删文。
3D视觉开发者社区是由奥比中光给所有开发者打造的分享与交流平台,旨在将3D视觉技术开放给开发者。平台为开发者提供3D视觉领域免费课程、奥比中光独家资源与专业技术支持。点击加入3D视觉开发者社区,和开发者们一起讨论分享吧~
或可微信关注官方公众号3D视觉开发者社区,获取更多干货知识哦。如果您喜欢我们的文章,请多多支持我们,欢迎点赞、评论、收藏。感谢观看!
文章出处登录后可见!