



前言
hrnet_ocr是Semantic Segmentation on Cityscapes test中目前排名第一的语义分割模型,结合了高分辨率网络hrnet和OCRNet方法。本文主要介绍OCRNet法。
OCRNet提出背景:使用一般性的ASPP方法如图(a),其中红点是关注的点,蓝点和黄点是采样出来的周围点,若将其作为红点的上下文,背景和物体没有区分开来,这样的上下文信息对红点像素分类帮助有限。为改善此情况,提出OCRNet方法如图(b),其可让上下文信息关注在物体上,从而为红点提供更有用的信息。
论文:https://arxiv.org/pdf/1909.11065.pdf
源码:https://git.io/openseg and https://git.io/HRNet.OCR
OCRNet 网络
OCRNet方法的总体思路:在coarse-to-fine的语义分割过程中,使用通用的语义分割模型得到粗略的分割结果,也可以从backbone得到每个像素的特征。根据每个像素的语义信息和特征,可以得到每个像素。每个类别的特征;然后可以计算像素特征与每个类别的特征的相似度,根据相似度可以得到每个像素属于每个类别的可能性,并对每个区域的表示进一步加权,得到当前的像素增强. (object-contextual representation)的特征表示,整体流程如下: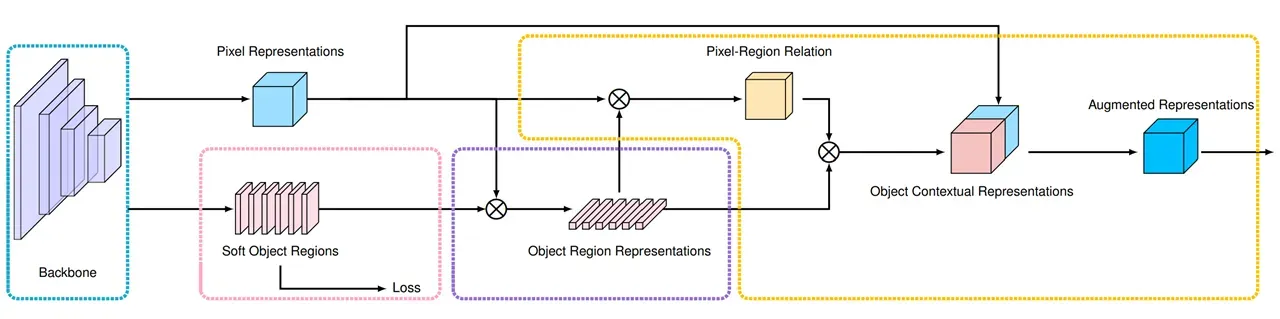

Step1:提取类别区域特征
目标:根据像素语义信息和像素特征,获取每个类别的区域特征。像素语义信息是常规语义分割的结果,像素特征是backbone提取的特征图。具体方法如下:
(1)像素语义(20×100×100)展开成二维(20×10000),其每一行表示每个像素点(10000个像素点)属于某类物体(总共20个类)的概率。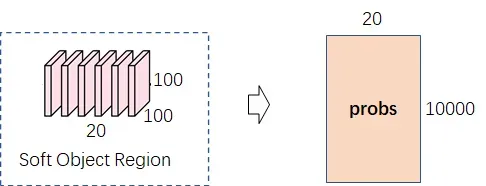

(2)像素特征(512×100×100)展开成二维(512×10000),其每一列表示每个像素点(10000个像素点)在某一维特征(512维)。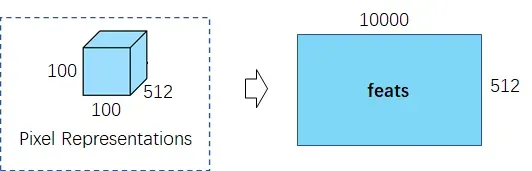

(3)像素语义的每行乘以像素特征的每列再相加,得到类别区域特征,其每一行表示某个类(20类)的512维特征。
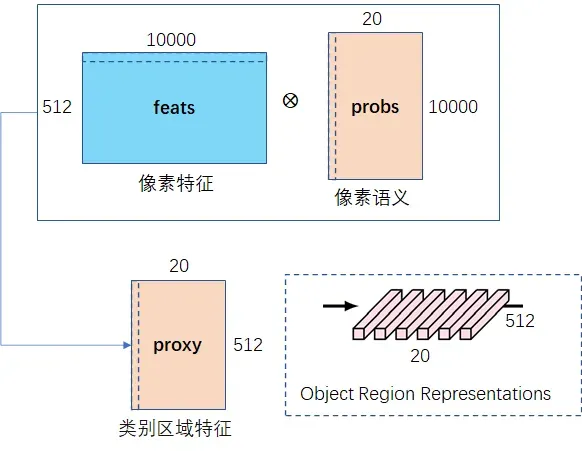

计算代码如下:
def get_proxy(feats,probs):
batch_size, c, h, w = probs.size(0), probs.size(1), probs.size(2), probs.size(3)
# 1, 20, 100, 100
probs = probs.view(batch_size, c, -1)
# (1, 20, 10000)
feats = feats.view(batch_size, feats.size(1), -1)
# (1, 512, 10000)
feats = feats.permute(0, 2, 1) # batch x hw x c
# (1, 10000, 512)
probs = F.softmax(self.scale * probs, dim=2)# batch x k x hw
# (1, 20, 10000)
proxy = torch.matmul(probs, feats).permute(0, 2, 1).unsqueeze(3)# batch x k x c
# (1, 512, 20, 1)
return proxy
if __name__ == "__main__":
feats = torch.randn((1, 512, 100, 100))
probs = torch.randn((1, 20, 100, 100))
proxy=get_proxy(feats,probs)
Step2:像素区域相似度
对于像素特征feats和step1,得到类别区域特征proxy,self-attention用于获得像素与区域的相似度,即依赖关系。
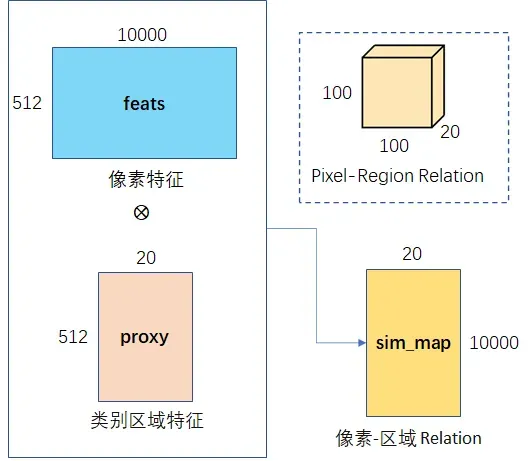

在self-attention、

f_pixel = nn.Sequential(
nn.Conv2d(in_ch=in_ch, out_ch=key_ch,kernel_size=1, stride=1, padding=0),
ModuleHelper.BNReLU(key_ch, bn_type=bn_type),
nn.Conv2d(in_ch=key_ch, out_ch=key_ch,kernel_size=1, stride=1, padding=0),
ModuleHelper.BNReLU(key_ch, bn_type=bn_type),
)
f_object = nn.Sequential(
nn.Conv2d(in_ch=in_ch, out_ch=key_ch,kernel_size=1, stride=1, padding=0),
ModuleHelper.BNReLU(key_ch, bn_type=bn_type),
nn.Conv2d(in_ch=key_ch, out_ch=key_ch,kernel_size=1, stride=1, padding=0),
ModuleHelper.BNReLU(key_ch, bn_type=bn_type),
)
根据
计算代码如下:
def get_sim_map(feats, proxy):
x=feats
batch_size, h, w = x.size(0), x.size(2), x.size(3)
# 1, 100, 100
## qk
query = f_pixel(x).view(batch_size, self.key_channels, -1)
# (1, 256, 10000)
query = query.permute(0, 2, 1)
# (1, 256, 10000)
key = f_object(proxy).view(batch_size, self.key_channels, -1)
# (1, 256, 20)
value = self.f_down(proxy).view(batch_size, self.key_channels, -1)
# (1, 256, 20)
value = value.permute(0, 2, 1)
# (1, 20, 256)
## sim
sim_map = torch.matmul(query, key)
# (1, 10000, 20)
sim_map = (self.key_channels**-.5) * sim_map
# (1, 10000, 20)
sim_map = F.softmax(sim_map, dim=-1)
# (1, 10000, 20)
return sim_map
if __name__ == "__main__":
feats = torch.randn((1, 512, 100, 100))
proxy=get_proxy(feats,probs)
sim_map=get_sim_map(feats,proxy)
Step3:获得上下文表示
simmap由step2计算,context可以乘以V,拼接context和像素特征,然后调整通道,得到最终的上下文表示。计算公式如下: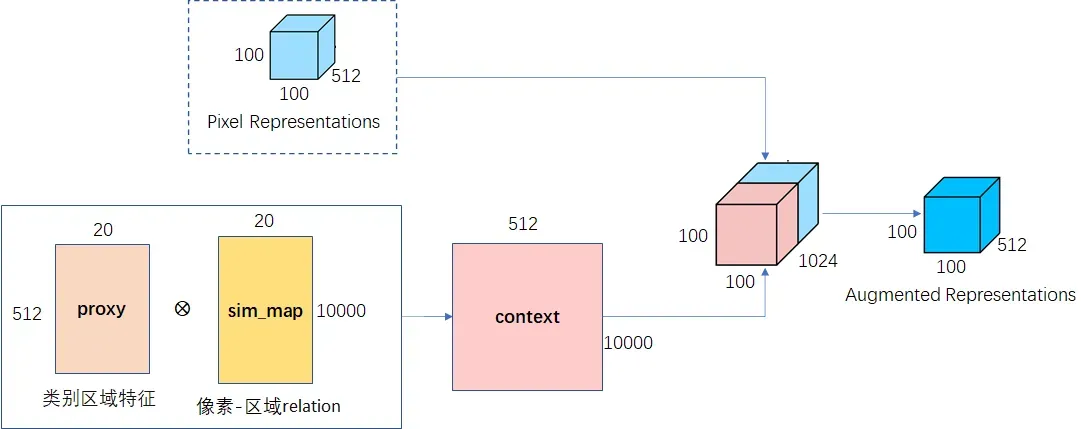

计算代码如下:
def get_context(feats,proxy,sim_map):
context = torch.matmul(sim_map, value) # hw x k x k x c
# (1, 10000, 256)
context = context.permute(0, 2, 1).contiguous()
# (1, 10000, 256)
context = context.view(batch_size, self.key_channels, *x.size()[2:])
# (1, 256, 100, 100)
context = f_up(context)
# (1, 512, 100, 100)
output = self.conv_bn_dropout(torch.cat([context, feats], 1))
# (1, 512, 100, 100)
return output
if __name__ == "__main__":
feats = torch.randn((1, 512, 100, 100))
proxy=get_proxy(feats,probs)
sim_map=get_sim_map(feats,proxy)
output=get_context(proxy,sim_map)
参考
Object-Contextual Representations for Semantic Segmentation
文章出处登录后可见!